MySQL索引事物
Posted 你这家伙
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL索引事物相关的知识,希望对你有一定的参考价值。

索引
什么是索引
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现
(就好像书的目录一样,它的作用就是用来加速数据库查询的)
索引的作用
- 数据库中过的表,数据,索引之间的关系,类似书架上的图书,书籍内容和书目录的关系
- 素银所起的作用类似于数据目录,可用于快速定位,检索数据
- 索引对于提高数据库的性能有很大的帮助
为什么要有索引
因为数据库上的数据都是存储在磁盘上的(而磁盘的操作是非常慢的(10^-3),而内存的操作是非常快的(10 ^-9),内存操速度远超于磁盘操作速度),然后磁盘是很大的,而内存比磁盘要小很多,所有磁盘(比如C盘)上的数据会被永久保存(除非自己删除),内存的数据重启电脑之后就没有了。而数据库的数据一定是要永久保存的,因此必须存在磁盘上面,但是磁盘操作速度慢,因此需要辅助功能(索引)来进行查询,而且磁盘如果在数据量比较大的情况下进行按顺序查询速度比较慢,而索引的诞生就解决了这个问题。
实现索引的方式
索引是使用哪种数据结构实现的呢?数据结构可以分为四类
线性表(数组,链表,堆栈……)
树(二叉树,AVL树,B树……)
图(图属于特殊的二叉树)
其他类型数据(跳表,压缩表……)
既然有这么多数据结构,那么我们该如何抉择?
- 哈希表:(根据哈希函数,得到哈希值,然后在链表中的位置进行遍历的key查询,找到最终位置),但是哈希函数只能怪很快的进行查询具体某一个数据的位置,但是数据库存在着范围查询,然后这个是哈希表实现不了的(×)
- 二叉搜索树:因为对二叉搜索树进行中序遍历,得到的将是有序的数据,那么既可以查询到具体的某一个数据,也可以查询到某一个范围的数据(即分别找到范围的起始和终止范围,然后就查询到了范围数据),但是为什么不用二叉树呢?1 .因为当有海量数据的时候,每个节点只能存储一个数据,那么需要进行磁盘遍历的次数就会很多,需要的时间就会很长.2.因为二叉树只有两个叉,因为当有很多数据的时候,此时二叉树的层高就会很高,那么比较的次数也就越多,导致效率很低
索引底层是使用 B +树来进行实现
B树又分为B-(-是连接符)和B+树,他是一个多分枝的结构
B树

B树查询流程:
如上图我要从上图中找到 E 字母,查找流程如下
(1)获取根节点的关键字进行比较,当前根节点关键字为M,E<M(26个字母顺序),所以往找到指向左边的子节点(二分法规则,左小右大,左边放小于当前节点值的子节点、右边放大于当前节点值的子节点);
(2)拿到关键字D和G,D<E<G 所以直接找到D和G中间的节点;
(3)拿到E和F,因为E=E 所以直接返回关键字和指针信息(如果树结构里面没有包含所要查找的节点则返回null);
B树的优点:
- b树的层高更低
- b树每个节点可以存储多个数据
但是索引底部却不是使用B树,而是使用B+树来实现的,也就是对B树的一个改进
B+树的结构
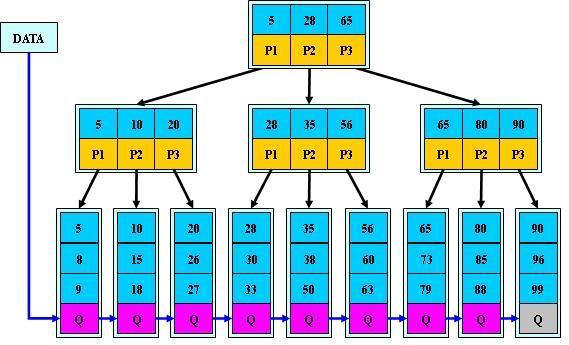
B+树的优点:
- 把每一层的节点使用链表进行关联(省去了O(n)的中序遍历,直接进行链表查询就可以得到区间信息)
- 把所有的数据存储在叶子节点,而非叶子节点只存储辅助查询的ID信息
- 把所有的非叶子节点存储在内存中,因此查询性能就大大提升了
索引的使用
对于索引的操作只能增加,删除,和查找操作,没有修改操作
当我们创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY)时,会自动创建对应列的索引。
注意:外键的索引是创建在子表当中的
索引类型 主键索引(不能删除) 、外键索引(不能删除) 、普通索引 、唯一索引
- 查看索引
如:当我创建一个student表,并将其id设置为主键之后,查看这个表的索引
查看索引:show index from 【表名】

就会发现自动创建了一个名为“PRIMARY”的索引
- 创建索引:
对于非主键、非唯一约束、非外键的字段,可以创建普通索引
创建索引:create index 索引名 on 表名(字段名);
- 删除索引
注意:主键索引和外键索引是不能够被删除的
删除索引:drop index 索引名 on 表名;
注意:foreign key 创建索引在子表中而非主表中的原因
- 设计层面的考虑:foreign key是在子表中进行创建和操作的,出于软件设计层面解耦的考虑,不能在操作子表的时候,影响到其他表
- 出于业务层面考虑:因为子表的业务量更大,应该把索引给业务量大的表
注意: 唯一索引注意点
比如现在又一个student表,里面又两个字段(id,name)当我们将设置成unique的时候,然后我们添加一个数据(1,’Java‘),这时候因为当我们创建unique的时候会自动帮我们创建索引,那么在当我们添加(1,’mysql‘)的时候,因id和前面的重复了,所以会添加失败,但是当我们删除这个表的索引之后,就能够添加成功,是因为我们删除唯一索引之后,那么这个unique约束也就失效了
那么此时就会有人可能是不小心删除索引了怎么办?
此时肯定会有人就说:那我们直接在创建一个索引不就行了,但是一操作就会发现失败,是因为如果想要创建索引,必须保证创建索引的这一列数据中没有重复项,因为前面我们添加了(1,’Java‘)和(1,’mysql‘)这两条数据,id相同,所以当你去创建索引的时候就会发现创建失败
那么如果解决呢?
首先可以将name = ’mysql‘的数据删除,然后在去创建唯一索引(注意:一定是唯一索引,不能是普通索引哦(也就是在index前面加上unique)),此时就会发现创建成功,然后再去添加id重复字段就会发现添加失败
索引的使用场景
要考虑对数据库表的某列或者某几列创建索引,需要注意:
- 数据量较大,且经常对这些列进行条件查询
- 该数据库表的插入操作,及对这些列的修改操作频率较低
- 索引会占用额外的磁盘空间
也即是:如果非条件查询列,或经常做插入,修改操作,或磁盘空间不足时,不考虑创建索引
事物
什么是事物
事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败。在不同的环境中,都可以有事务。对应在数据库中,就是数据库事务。
事物的操作
事物的执行步骤:
- 开启事物:start transaction;
- 一系列的SQL操作
- 提交或回滚事物(rollback/commit)
说明:rollback即是全部失败,commit即是全部成功。
示例
比如:
此时史迪仔要给蓝精灵转1000元,按道理说
史迪仔的账户 -1000
蓝精灵的长湖 +1000
此时如果突然停电了,那么史迪仔的账户就会凭空消失1000元,而此时蓝精灵的账户却没有增加1000
元
使用事物:
也就是将多个操作步骤合并成一个执行单元的操作,要么全部执行成功,要么不执行(反补的机制回滚数据)
比如此时还是停电了,但是史迪仔还是-1000元,但是因为停电了,索引此时这1000元是在磁盘上的,当通电之后,此时发现磁盘上还有一个执行了一半的数据,此时就会执行这个反补的回滚机制,就会给史迪仔的账户+2000元
start transaction;
-- 史迪仔账户减少2000
update accout set money=money-2000 where name = '史迪仔';
-- 蓝精灵账户增加2000
update accout set money=money+2000 where name = '蓝精灵';
commit;
事务的四大特性
- 原子性:一系列操作的数据,要么全部执行成功,要么不执行
- 持久性:事务执行完成之后,所有的操作结果必须持久化到磁盘进行永久保存
- 一致性:事务执行前,后,必须保证数据的安全性(有效性)
- 隔离性:一个事务在执行的时候对其他并发事务是隔离的
隔离性(重):
隔离级别(四种):
- 读未提交
- 读已提交
- 不可重复读
- 串行化
隔离性存在的三个问题
- 脏读
- 幻读
- 不可重复读
为什么要有这个四个隔离级别呢?
其实解决的就是并发事务操作级别的问题
以上是关于MySQL索引事物的主要内容,如果未能解决你的问题,请参考以下文章