实战案例!使用 Python 进行 RFM 客户价值分析!
Posted Python学习与数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实战案例!使用 Python 进行 RFM 客户价值分析!相关的知识,希望对你有一定的参考价值。
欢迎关注 ,专注Python、数据分析、数据挖掘、好玩工具!
RFM 建模是一种用于评估客户价值的营销分析技术。RFM 模型基于三个因素:
- Recency:客户最近购买的情况
- Frequency:客户进行购买的频率
- Monetary Value:顾客在购买上花了多少钱
RFM 模型提供了上述三个度量的数值。这些价值观有助于公司更好地了解客户潜力。
如果客户在过去一年中每天从星巴克购物,但在上个月没有购买任何东西,他们可能会转向竞争对手的品牌。
星巴克可以针对这些客户,提出一个营销策略,把他们赢回来。
在本文中,我将向你展示如何使用 Python 构建 RFM 模型。我们将使用包含4000多个唯一客户ID的数据集,并将RFM值分配给每个客户。
第一步
从 Kaggle 获取数据:https://www.kaggle.com/carrie1/ecommerce-data,确保在设备上安装了Python IDE以及Pandas库。
使用以下代码行读取下载的数据集:
import pandas as pd
df2 = pd.read_csv('data.csv',encoding='unicode_escape')
现在,让我们看一下数据帧:
df.head()

对于此分析,我们将只使用四列:数量(Quantity)、发票日期(InvoiceDate)、单价(UnitPrice)和客户ID(CustomerID)。
第二步
让我们先计算每个客户的总花费(Monetary Value)。
为此,我们需要使用 UnitPrice 和 Quantity 列。我们将首先将这些值相乘,以获得每个客户在每笔交易中花费的总金额。
下面是执行此操作的代码:
df['Total'] = df['Quantity']*df['UnitPrice']

现在,我们需要在整个数据集中找到同一客户花费的总金额。我们可以使用以下代码行来做到这一点:
m = df.groupby('CustomerID')['Total'].sum()
m = pd.DataFrame(m).reset_index()
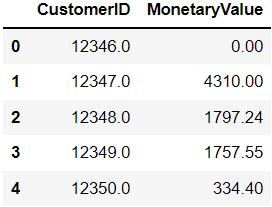
第三步
现在,让我们计算频率(Frequency)。我们希望找到每个客户购买的次数。
让我们再次看看数据帧,看看如何做到这一点:

要查找每个客户的购买次数,我们需要使用 CustomerID 和 InvoiceDate 列。
为此,请运行以下代码行:
freq = df.groupby('CustomerID')['InvoiceDate'].count()
f = pd.DataFrame(freq).reset_index()
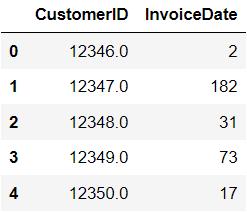
第四步
最后,我们可以计算数据框中每个客户的最近性(recency)。
为了计算最近性,我们需要找到上次此人进行购买的时间。
要找到这个值,我们需要使用 CustomerID 和 InvoiceDate 列。我们首先需要找到每个客户进行购买的最新日期。然后,我们需要给这个日期分配一些定量值。
例如,如果两个月前看到客户 A 进行购买,两年前看到客户 B 进行购买,我们需要为客户 A 指定更高的最近值。
为此,我们首先需要将 InvoiceDate 列转换为 datetime 对象。运行以下代码行:
df['Date']= pd.to_datetime(df['InvoiceDate'])

我们现在有了一个新的"Date"列,现在需要找到每个客户最近购买的日期。
为此,我们需要为每个CustomerID的所有日期分配一个等级。
最近的日期将被列为1,第二个最近的日期将被列为2,依此类推。
运行以下代码行:
df['rank'] = df.sort_values(['CustomerID','Date']).groupby(['CustomerID'])['Date'].rank(method='min').astype(int)

现在,我们根据看到客户购物的时间进行了不同的排名。最近的购买排名为1。
现在,让我们过滤数据帧并去掉所有其他购买。我们只需要保留最新的:
recent = df[df['rank']==1]
现在我们所需要做的就是给出一个定量的最近值。这意味着与一周前看到的人相比,一天前看到的人将获得更高的最近值。
为此,我们只需计算数据框中的每个日期与最早日期之间的差值。这样,最近的日期将具有更高的值。
运行以下代码行:
recent['recency'] = recent['Date'] - pd.to_datetime('2010-12-01 08:26:00')
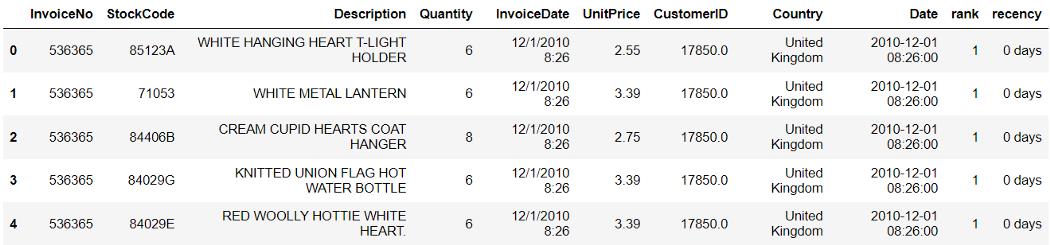
上面的数据框对于每个 CustomerID 都有许多重复的值。这是因为细分是按产品进行的,同一客户同时购买了多个产品。
让我们仅选择CustomerID和Recenty列并删除重复项:
recent = recent[['CustomerID','recency']]
recent = recent.drop_duplicates()

第五步
我们现在已经完成了RFM值的计算。我们将结果存储在单独的数据帧中,因此让我们将它们合并在一起:
finaldf = f.merge(m,on='CustomerID').merge(recent,on='CustomerID')
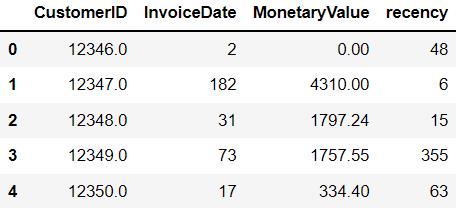
总结
我们已成功地将 RFM 值附加到数据集中的每个客户ID,可以根据这些计算建立某种聚类模型,将类似的客户分组在一起。
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

目前开通了技术交流群,群友超过2000人,添加方式如下:
如下方式均可,添加时最好方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式一、发送如下图片至微信,进行长按识别,回复加群;
- 方式二、直接添加小助手微信号:pythoner666,备注:来自CSDN
- 方式三、微信搜索公众号:Python学习与数据挖掘,后台回复:加群

以上是关于实战案例!使用 Python 进行 RFM 客户价值分析!的主要内容,如果未能解决你的问题,请参考以下文章