REDIS08_缓存雪崩缓存穿透基于布隆过滤器解决缓存穿透的问题缓存击穿基于缓存击穿工作实际案例
Posted 所得皆惊喜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了REDIS08_缓存雪崩缓存穿透基于布隆过滤器解决缓存穿透的问题缓存击穿基于缓存击穿工作实际案例相关的知识,希望对你有一定的参考价值。
①. 缓存雪崩
-
①. 问题的产生:缓存雪崩是指缓存数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同 数据都过期了,很多数据都查不到从而查数据库
(redis主机挂了,Redis 全盘崩溃、比如缓存中有大量数据同时过期) -
②. 解决方案
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生
- 设置热点数据永远不过期。
- 使用缓存预热
- ③. 什么是缓存预热?
缓存预热就是将数据提前加入到缓存中,当数据发生变更,再将最新的数据更新到缓存
②. 缓存穿透
-
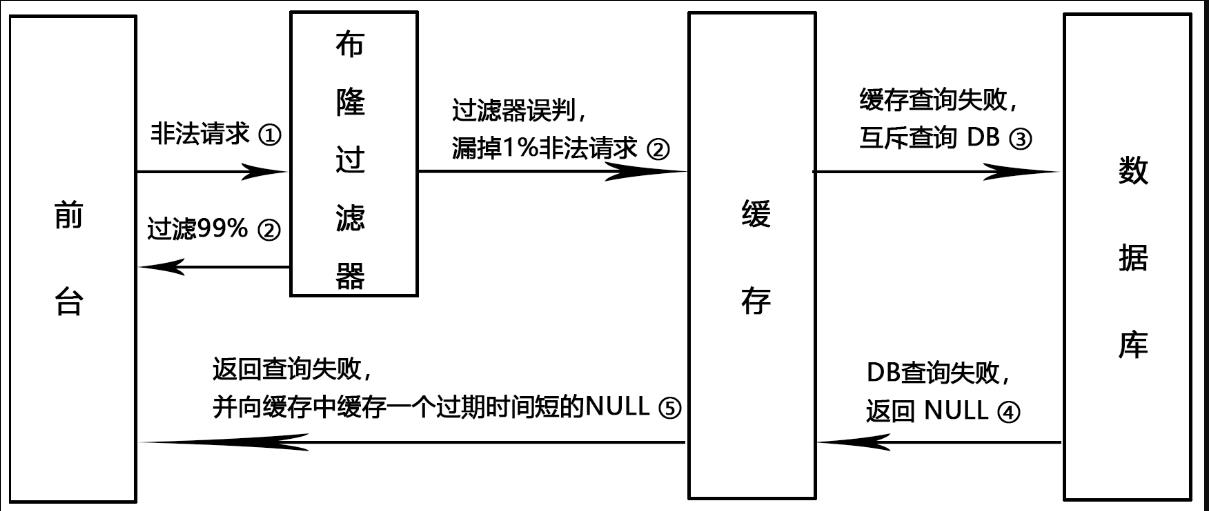
①. 请求去查询一条记录,先redis后mysql发现都查询不到该条记录,但是请求每次都会打到数据库上面去,导致后台数据库压力暴增,这种现象我们称为缓存穿透,这个redis变成了一个摆设(redis中没有、mysql也没有)
-
②. 解决方案一:空对象缓存或者缺省值
- 黑客会对你的系统进行攻击,拿一个不存在的id 去查询数据,会产生大量的请求到数据库去查询。可能会导致你的数据库由于压力过大而宕掉
- id相同打你系统:第一次打到mysql,空对象缓存后第二次就返回null了,避免mysql被攻击,不用再到数据库中去走一圈了
- id不同打你系统:由于存在空对象缓存和缓存回写(看自己业务不限死),redis中的无关紧要的key也会越写越多(记得设置redis过期时间)

- ③. 解决方案二:Google布隆过滤器Guava解决缓存穿透(核心代码如下)
//入门案列
@Test
public void bloomFilter(){
// 创建布隆过滤器对象
BloomFilter<Integer> filter = BloomFilter.create(Funnels.integerFunnel(), 100);
// 判断指定元素是否存在
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
// 将元素添加进布隆过滤器
filter.put(1);
filter.put(2);
System.out.println(filter.mightContain(1));
System.out.println(filter.mightContain(2));
}
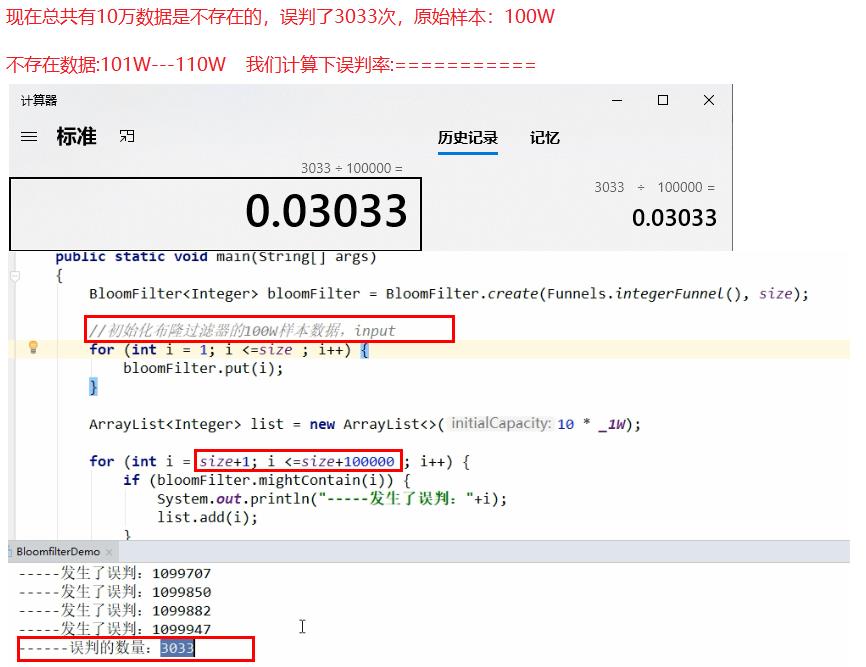
//取样本100W数据,查查不在100W范围内的其它10W数据是否存在
public class BloomfilterDemo {
public static final int _1W = 10000;
//布隆过滤器里预计要插入多少数据
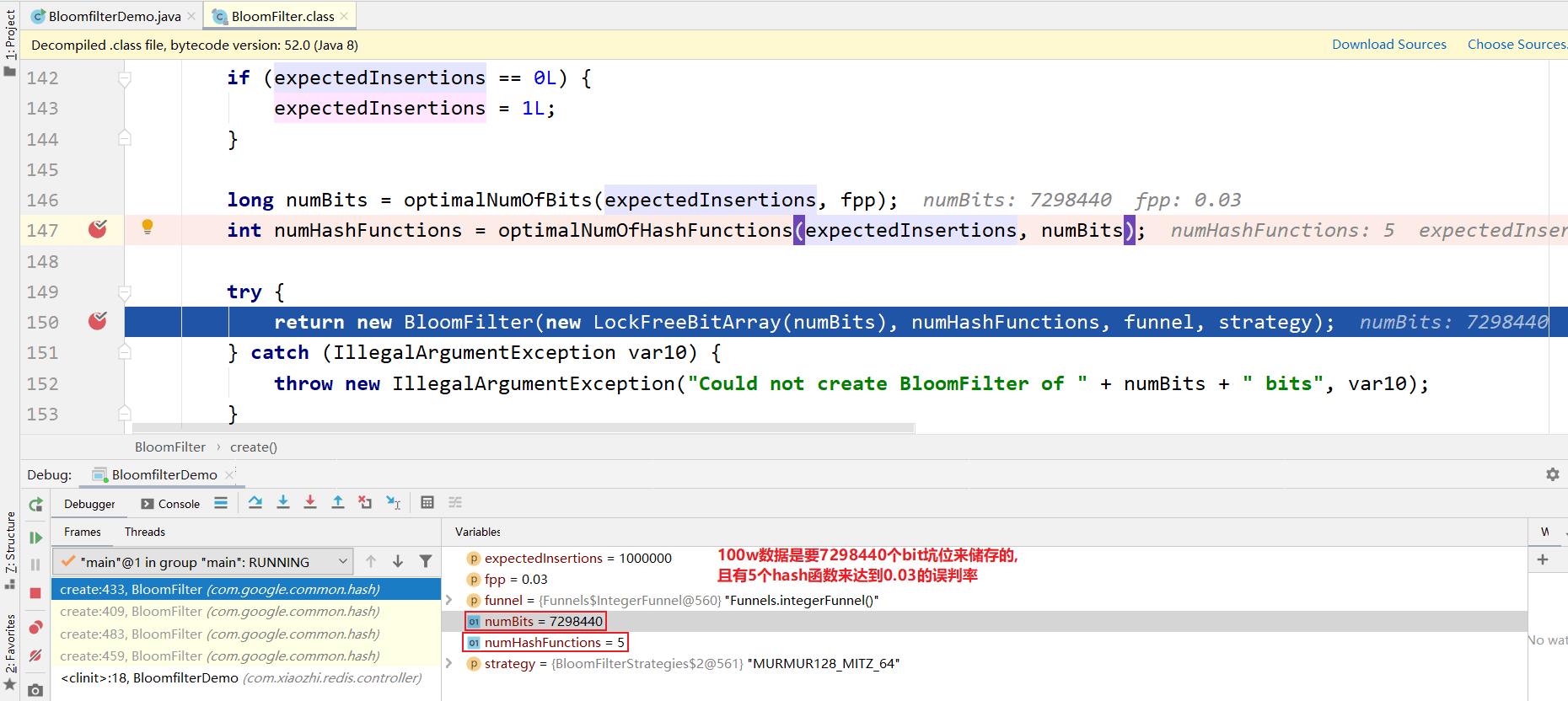
public static int size = 100 * _1W;
//误判率,它越小误判的个数也就越少(思考,是不是可以设置的无限小,没有误判岂不更好)
public static double fpp = 0.03;
// 构建布隆过滤器
//private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size);
//不写误判率就用默认的0.03
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size);
public static void main(String[] args) {
//1 先往布隆过滤器里面插入100万的样本数据
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
//故意取10万个不在过滤器里的值,看看有多少个会被认为在过滤器里
List<Integer> list = new ArrayList<>(10 * _1W);
for (int i = size+1; i < size + 100000; i++) {
if (bloomFilter.mightContain(i)) {
System.out.println(i+"\\t"+"被误判了.");
list.add(i);
}
}
System.out.println("误判的数量:" + list.size());
}
}
-
④. 解决方案三:Redis布隆过滤器解决缓存穿透
Guava 提供的布隆过滤器的实现还是很不错的 (想要详细了解的可以看一下它的源码实现),但是它有一个重大的缺陷就是只能单机使用 ,而现在互联网一般都是分布式的场景
为了解决这个问题,我们就需要用到Redis中的布隆过滤器了 -
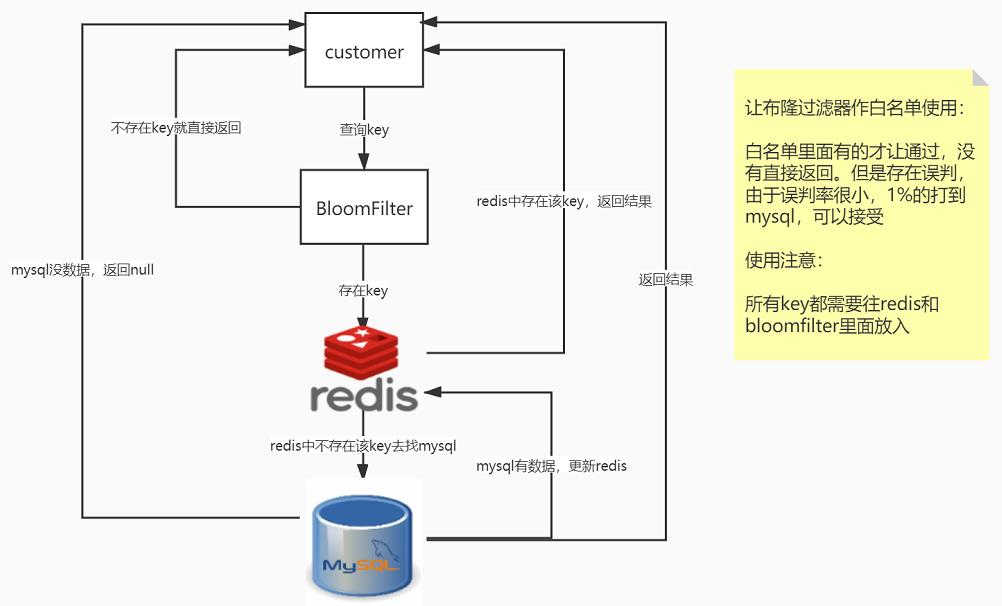
⑤. 针对方案三具体的案列说明:白名单过滤器
- 误判问题,但是概率小可以接受,不能从布隆过滤器删除
- 全部合法的key都需要放入过滤器+redis里面,不然数据就是返回null
public class RedissonBloomFilterDemo2 {
public static final int _1W = 10000;
//布隆过滤器里预计要插入多少数据
public static int size = 100 * _1W;
//误判率,它越小误判的个数也就越少
public static double fpp = 0.03;
static RedissonClient redissonClient = null;
static RBloomFilter rBloomFilter = null;
static {
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.68.143:6379").setDatabase(0);
//构造redisson
redissonClient = Redisson.create(config);
//通过redisson构造rBloomFilter
rBloomFilter = redissonClient.getBloomFilter("phoneListBloomFilter",new StringCodec());
rBloomFilter.tryInit(size,fpp);
// 1测试 布隆过滤器有+redis有
rBloomFilter.add("10086");
redissonClient.getBucket("10086",new StringCodec()).set("chinamobile10086");
// 2测试 布隆过滤器有+redis无
rBloomFilter.add("10087");
//3 测试 ,都没有
}
public static void main(String[] args) {
String phoneListById = getPhoneListById("10086");
//String phoneListById = getPhoneListById("10086");
//String phoneListById = getPhoneListById("10086");
System.out.println("------查询出来的结果: "+phoneListById);
//暂停几秒钟线程
try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); }
redissonClient.shutdown();
}
private static String getPhoneListById(String IDNumber) {
String result = null;
if (IDNumber == null) {
return null;
}
//1 先去布隆过滤器里面查询
if (rBloomFilter.contains(IDNumber)) {
//2 布隆过滤器里有,再去redis里面查询
RBucket<String> rBucket = redissonClient.getBucket(IDNumber, new StringCodec());
result = rBucket.get();
if(result != null) {
return "i come from redis: "+result;
}else{
result = getPhoneListByMySQL(IDNumber);
if (result == null) {
return null;
}
// 重新将数据更新回redis
redissonClient.getBucket(IDNumber,new StringCodec()).set(result);
}
return "i come from mysql: "+result;
}
return result;
}
private static String getPhoneListByMySQL(String IDNumber) {
return "chinamobile"+IDNumber;
}
}
- ⑥. 公司具体案列

③. 在centos7下布隆过滤器2种安装方式
- ①. 方式一:采用docker安装RedisBloom,推荐
具体步骤:
(1). Redis 在 4.0 之后有了插件功能(Module),可以使用外部的扩展功能,可以使用 RedisBloom 作为 Redis 布隆过滤器插件
(2). docker run -p 6379:6379 --name=redis6379bloom -d redislabs/rebloom
(3). docker exec -it redis6379bloom /bin/bash
(4). redis-cli
[root@TANG2021 ~]# docker exec -it myredistz /bin/bash
root@459c7c8679b1:/data# redis-cli
127.0.0.1:6379> keys *
1) "10086"
2) "{phoneListBloomFilter}:config"
3) "phoneListBloomFilter"
127.0.0.1:6379> type {phoneListBloomFilter}:config
hash
127.0.0.1:6379> hgetall {phoneListBloomFilter}:config
1) "size"
2) "7298440"
3) "hashIterations"
4) "5"
5) "expectedInsertions"
6) "1000000"
7) "falseProbability"
8) "0.03"
127.0.0.1:6379>
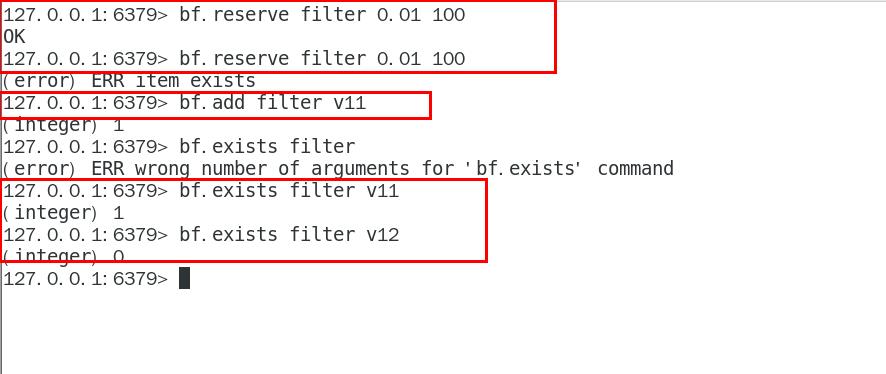
- ②. 布隆过滤器常用操作命令
bf.add key 值
bf.exists key 值
bf.madd 一次添加多个元素
bf.mexists 一次查询多个元素是否存在
- ③. 方式二:编译安装
# 下载 编译 安装Rebloom插件
wget https://github.com/RedisLabsModules/rebloom/archive/v2.2.2.tar.gz
# 解压
tar -zxvf v2.2.2.tar.gz
cd RedisBloom-2.2.2
# 若是第一次使用 需要安装gcc++环境
make
# redis服启动添加对应参数 这样写还是挺麻烦的
# rebloom_module="/usr/local/rebloom/rebloom.so"
# daemon --user ${REDIS_USER-redis} "$exec $REDIS_CONFIG --loadmodule # $rebloom_module --daemonize yes --pidfile $pidfile"
# 记录当前位置
pwd
# 进入reids目录 配置在redis.conf中 更加方便
vim redis.conf
# :/loadmodule redisbloom.so是刚才具体的pwd位置 cv一下
loadmodule /xxx/redis/redis-5.0.8/RedisBloom-2.2.2/redisbloom.so
# 保存退出
wq
# 重新启动redis-server 我是在redis中 操作的 若不在请写出具体位置 不然会报错
redis-server redis.conf
# 连接容器中的 redis 服务 若是无密码 redis-cli即可
redis-cli -a 密码
# 进入可以使用BF.ADD命令算成功
④. 缓存击穿
-
①. 缓存击穿:大量的请求同时查询一个 key 时,此时这个key正好失效了,就会导致大量的请求都打到数据库上面去(简单说就是热点key突然失效了,暴打mysql)
-
②. 危害:会造成某一时刻数据库请求量过大,压力剧增
-
③. 方案一:互斥更新、随机退避、差异失效时间

-
④. 方案2:对于访问频繁的热点key,干脆就不设置过期时间
-
⑤. 方案3:互斥独占锁防止击穿
public User findUserById2(Integer id) {
User user = null;
String key = CACHE_KEY_USER+id;
//1 先从redis里面查询,如果有直接返回结果,如果没有再去查询mysql
user = (User) redisTemplate.opsForValue().get(key);
if(user == null) {
//2 大厂用,对于高QPS的优化,进来就先加锁,保证一个请求操作,让外面的redis等待一下,避免击穿mysql
synchronized (UserService.class){
user = (User) redisTemplate.opsForValue().get(key);
//3 二次查redis还是null,可以去查mysql了(mysql默认有数据)
if (user == null) {
//4 查询mysql拿数据
user = userMapper.selectByPrimaryKey(id);//mysql有数据默认
if (user == null) {
return null;
}else{
//5 mysql里面有数据的,需要回写redis,完成数据一致性的同步工作
//setnx 不存在才创建
redisTemplate.opsForValue().setIfAbsent(key,user,7L,TimeUnit.DAYS);
}
}
}
}
return user;
}
⑤. 高并发的淘宝聚划算案例落地
-
①. 什么是淘宝聚划算?
-
②. 分析过程
| 步骤 | 说明 |
|---|---|
| 1 | 100%高并发,绝对不可以用mysql实现 |
| 2. | 先把mysql里面参加活动的数据抽取进redis,一般采用定时器扫描来决定上线活动还是下线取消 |
| 3 | 支持分页功能,一页20条记录 |
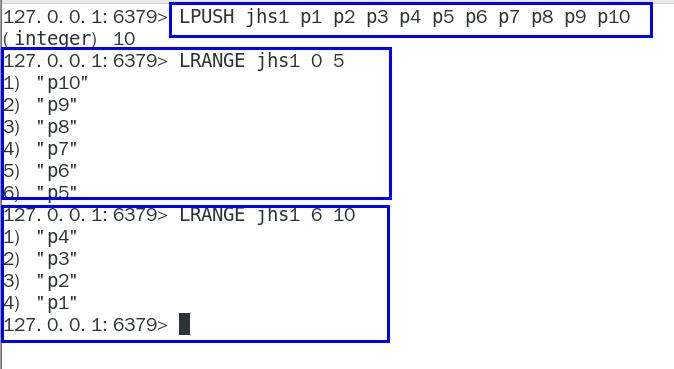
- ③. redis数据类型选型
- ④. springboot+redis实现高并发的淘宝聚划算业务
@Data
@ApiModel(value = "聚划算活动producet信息")
public class Product {
private Long id;
/**
* 产品名称
*/
private String name;
/**
* 产品价格
*/
private Integer price;
/**
* 产品详情
*/
private String detail;
public Product() {
}
public Product(Long id, String name, Integer price, String detail) {
this.id = id;
this.name = name;
this.price = price;
this.detail = detail;
}
}
public class Constants {
public static final String JHS_KEY="jhs";
public static final String JHS_KEY_A="jhs:a";
public static final String JHS_KEY_B="jhs:b";
}
@Service
@Slf4j
public class JHSTaskService{
@Autowired
private RedisTemplate redisTemplate;
@PostConstruct
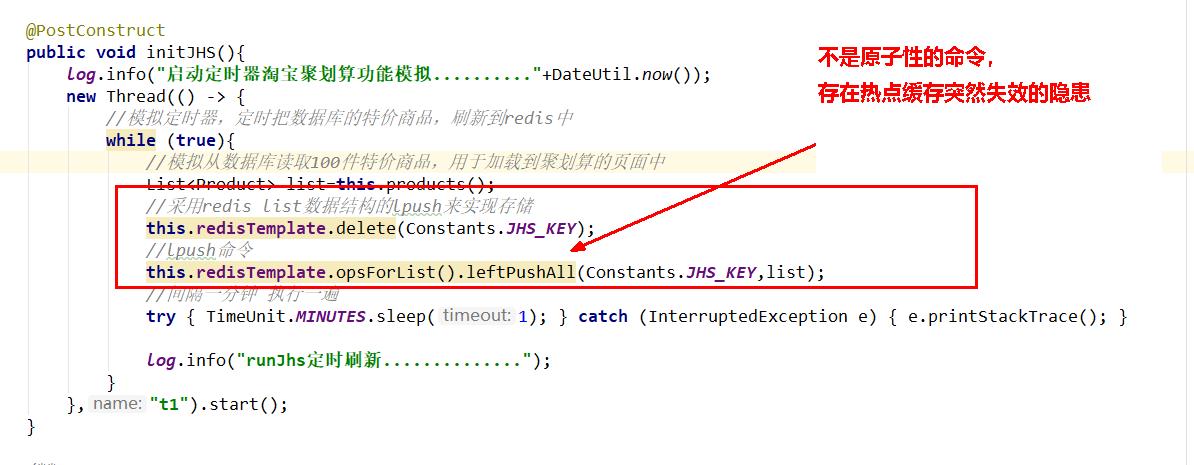
public void initJHS(){
log.info("启动定时器淘宝聚划算功能模拟.........."+DateUtil.now());
new Thread(() -> {
//模拟定时器,定时把数据库的特价商品,刷新到redis中
while (true){
//模拟从数据库读取100件特价商品,用于加载到聚划算的页面中
List<Product> list=this.products();
//采用redis list数据结构的lpush来实现存储
this.redisTemplate.delete(Constants.JHS_KEY);
//lpush命令
this.redisTemplate.opsForList().leftPushAll(Constants.JHS_KEY,list);
//间隔一分钟 执行一遍
try { TimeUnit.MINUTES.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); }
log.info("runJhs定时刷新..............");
}
},"t1").start();
}
/**
* 模拟从数据库读取100件特价商品,用于加载到聚划算的页面中
*/
public List<Product> products() {
List<Product> list=new ArrayList<>();
for (int i = 1; i <=20; i++) {
Random rand = new Random();
int id= rand.nextInt(10000);
Product obj=new Product((long) id,"product"+i,i,"detail");
list.add(obj);
}
return list;
}
}
@RestController
@Slf4j
@Api(description = "聚划算商品列表接口")
public class JHSProductController{
@Autowired
private RedisTemplate redisTemplate;
/**
* 分页查询:在高并发的情况下,只能走redis查询,走db的话必定会把db打垮
* http://localhost:5555/swagger-ui.html#/jhs-product-controller/findUsingGET
*/
@RequestMapping(value = "/pruduct/find",method = RequestMethod.GET)
@ApiOperation("按照分页和每页显示容量,点击查看")
public List<Product> find(int page, int size) {
List<Product> list=null;
long start = (page - 1) * size;
long end = start + size - 1;
try {
//采用redis list数据结构的lrange命令实现分页查询
list = this.redisTemplate.opsForList().range(Constants.JHS_KEY, start, end);
if (CollectionUtils.isEmpty(list)) {
//TODO 走DB查询
}
log.info("查询结果:{}", list);
} catch (Exception ex) {
//这里的异常,一般是redis瘫痪 ,或 redis网络timeout
log.error("exception:", ex);
//TODO 走DB查询
}
return list;
}
}
- ⑤. 上述存在哪些生产的问题?QPS上1000后导致可怕的缓存击穿
(互斥更新、随机退避、差异失效时间)
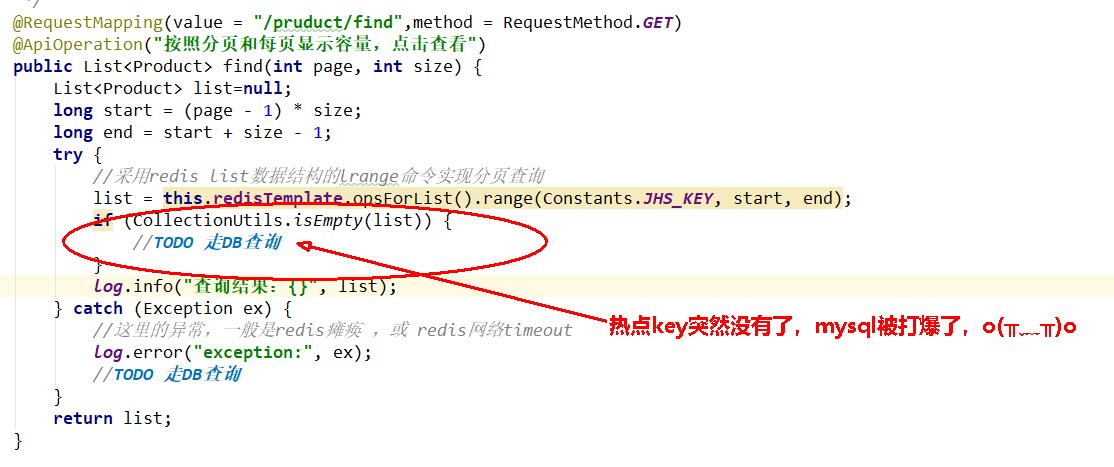
- ⑥. 互斥更新、随机退避
以上是关于REDIS08_缓存雪崩缓存穿透基于布隆过滤器解决缓存穿透的问题缓存击穿基于缓存击穿工作实际案例的主要内容,如果未能解决你的问题,请参考以下文章