SIGKDD2021 | 淘宝搜索向量化召回实践
Posted 阿里巴巴淘系技术团队官网博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SIGKDD2021 | 淘宝搜索向量化召回实践相关的知识,希望对你有一定的参考价值。

论文下载链接:
https://arxiv.org/abs/2106.09297
摘要
近年来,随着深度学习在图像、自然语言处理等领域的蓬勃发展,越来越多的工业界搜索和推荐系统将大规模深度学习应用到真实的业务中。
一般来说业务的搜索系统由多阶段(召回-粗排-精排-重排等)组成,而召回决定了搜索性能的上限。
区别于网页搜索,电商搜索的召回除需要满足用户基本的搜索相关性需求外,还需要尽可能展现给用户对特点品牌、风格、价格等的个性化商品。然而传统的基于倒排索引的召回机制难以将用户个性化行为引入,向量化的深度召回模型则由于其天然的embedded特性逐渐成为重要的个性化召回来源。
但在我们长期实战中发现,虽然个性化向量召回对搜索成交提效有明显帮助,但其召回的商品相关性可控性差,损害了用户搜索体验,也成为其继续提效的瓶颈。因此,我们提出了一种同时兼顾个性化和搜索相关性的向量召回模型,将用户个性化行为和搜索词高效地建模到网络中,使最终学习到的用户向量表达既能满足个性化需求也能保证良好的搜索相关性。
我们的模型替换原有的向量召回模型在淘宝搜索上线,线上A/B测试显示用户搜索体验提升的同时,搜索成交也得到显著提升。同时我们的工作也被SIGKDD Applied Data Science Track录用。
背景
电商平台的商品搜索、推荐服务,从海量候选中高效且准确地为用户查找、过滤和展示商品,已然成为人们生活中重要的购物方式之一。
在电商搜索领域,除了满足推荐系统通常考虑的用户个性化需求外,搜索系统还必须满足用户查询的最基本相关性需求。
例如,当用户的搜索请求为“羽绒服”时,搜索系统既要满足用户个体对品牌、颜色和风格等偏好,还要保证所展示商品的品类都是羽绒服,而不能出现棉服。
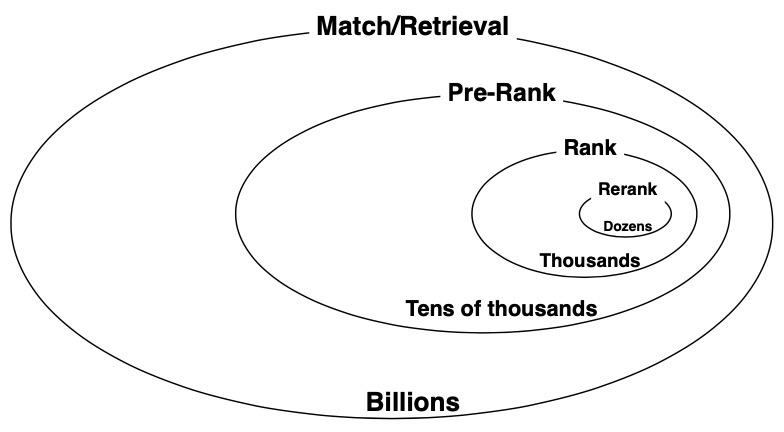
从技术角度看,工业界搜索、推荐系统通常采用了多阶段(包括召回、排序等)方法,如下图所示,是淘宝搜索系统的宏观视角,召回处于系统的最下层,首先负责从海量商品池中初步检索出符合用户意图的候选商品,进而送到排序阶段进行精细化的个性化排序,最终展示少量符合用户意图的商品。由于其处于搜索系统的上游流程,通常决定着搜索系统的性能和服务质量的上限。
近年来,随着深度学习在各领域的迅速发展,向量化召回技术EBR(Embedding-Based Retrieval)在工业界搜索(百度、京东、Facebook搜索等)、推荐(淘宝猜你喜欢推荐等)、广告(阿里妈妈)实际应用中同样发挥了重要作用,为用户提供了区别于传统召回视角的商品集候选。然而,在我们落地实战过程中发现,向量化召回虽然通过引入用户历史行为建模和模糊匹配为现有的淘宝搜索召回模块取得了明显的线上收益 。但由于向量内积检索相比于传统的倒排索引检索是一种非精确匹配(inexact match)的方式,在搜索相关性控制方面不足,给后链路引入了较多badcase,即使有相关性排序模块,依然对用户搜索带来了负面体验。此外,这些无效召回降低了召回率,无法满足排序模块的需求,降低了系统利用率。因此,只有在商品的检索召回阶段同时建模用户查询的语义相关性以及其个性化偏好,才能为排序阶段提供更好的商品候选集合,最终为用户提供优良的个性化商品搜索服务和在线购物体验。
问题分析
基于项目背景的分析,我们问题的定义可以数学化表示为:
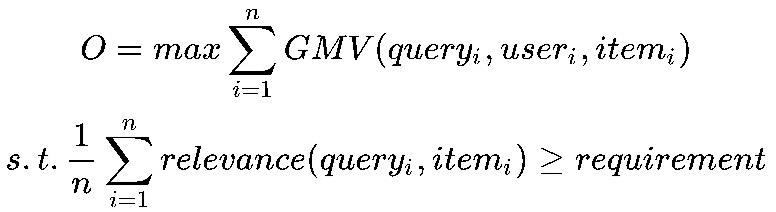
我们在使用用户个性化优化模型效率GMV(核心KPI)的同时,需要使得模型召回的商品与搜索query的相关性满足指定阈值(用户体验尽可能好)。建模用户个性化行为比较直接,在搜索、推荐系统中方法也比较常见,我们的线上向量召回base模型也已经将其引入,核心问题则是如何保证效率的同时,提升模型召回结果的相关性,使得相关性和个性化相辅相成。
我们在提出解决方法之前,通过相关工作调研,先分析了个性化向量召回搜索相关性低的原因,主要是以下两点:
exact match能力的缺乏:模型使用低维压缩的embedding进行向量内积检索,因此不能灵活地在词级别上进行文本相关性学习,可解释性和相关性可控性都不够好。
高质量训练样本的缺乏:模型通常使用点击曝光日志来训练,但“点击不等于相关”和“selection bias”的现象普遍存在,导致缺乏适合相关性学习的训练数据成为相关性低的原因之一。
学术界在exact match方向上的解决方法通常是query和item表达做复杂交叉建模,由于工业界召回需要使用向量内积K近邻检索,因此在工业级召回问题上不能适用。我们便将主要精力放在了样本方向上。此外,与文本搜索不同,电商搜索的用户个性化发挥了重要作用,我们通过设计平衡个性化和语义相关性的模型结构,在保证模型相关性的同时,优化模型的GMV效率。
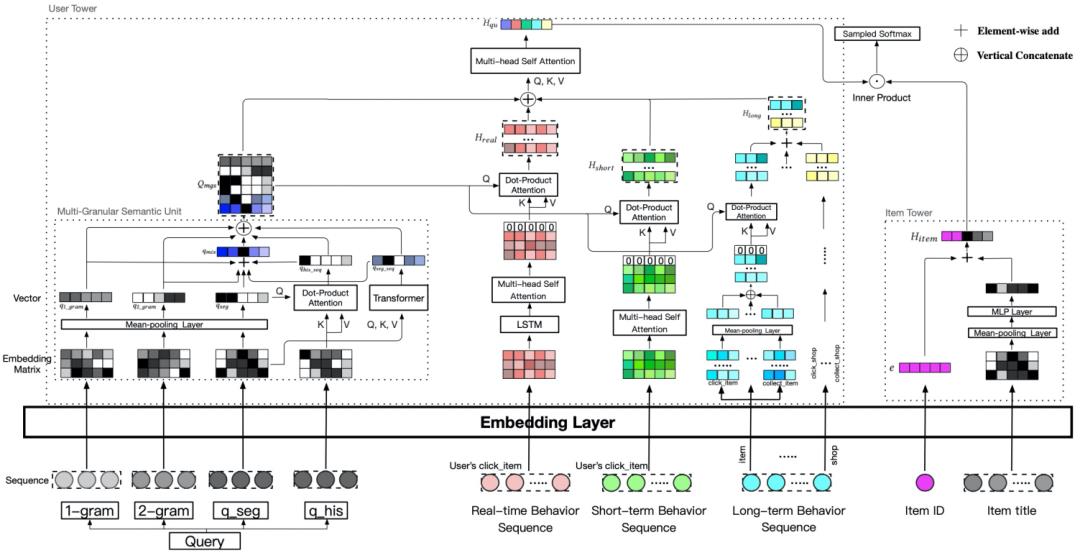
模型设计
我们提出一种新颖的平衡融合搜索语义相关性和个性化建模的深度向量召回模型(MGDSPR),输入用户在淘宝的历史行为和当前搜索query,模型建模得到用户搜索向量表示,与商品向量通过内积进行打分,从而获得检索结果的topK,计算打分公式数学化表示为:
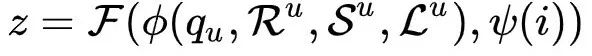
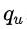 表示用户搜索词,
表示用户搜索词,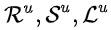 分别表示用户的实时、近期和长期行为。
分别表示用户的实时、近期和长期行为。 表示内积函数,
表示内积函数,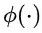 表述query和行为联合建模函数,
表述query和行为联合建模函数, 表示商品向量建模函数。建模函数具体结构如图所示。
表示商品向量建模函数。建模函数具体结构如图所示。
▐ 相关性建模
我们对向量召回模型相关性提升的主要收益来源于样本的改进,根据实战经验总结了多阶段下不同样本的优势。
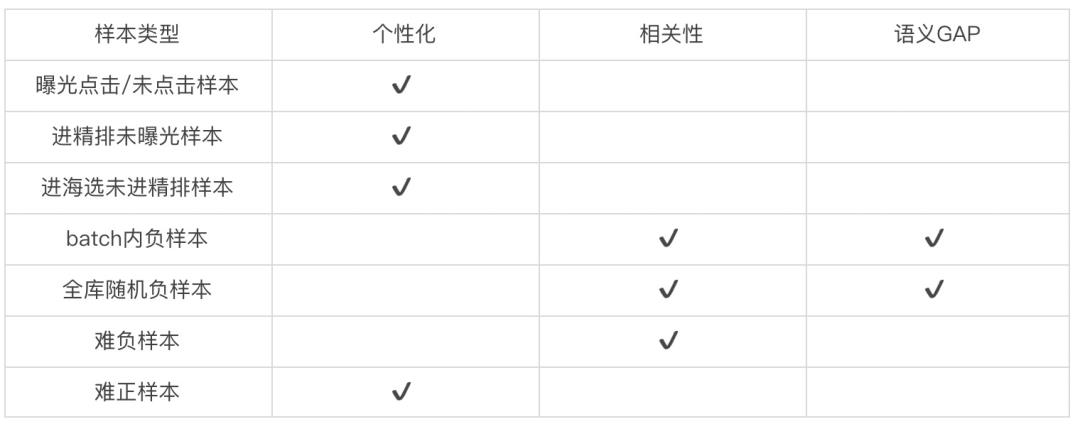
我们实践过程中尝试了上表中不同样本的利用,比较成功、能够显著提升模型相关性效果的方法主要包括全库随机负样本及其噪音平滑,以及难负样本生成。
训练样本和损失函数
把用户点击或购买的商品视为正样本,并按商品曝光频率从全集合采样商品作为负样本集合,我们发现使用这种全局随机负样本相比于只使用曝光点击和未点击样本,可以大幅提升模型的搜索相关性。为了使模型训练的样本空间与在线服务的样本空间一致,我们使用softmax来表示对某一商品的打分偏好在全局商品集合的概率分布,进而使用交叉熵作为损失函数:
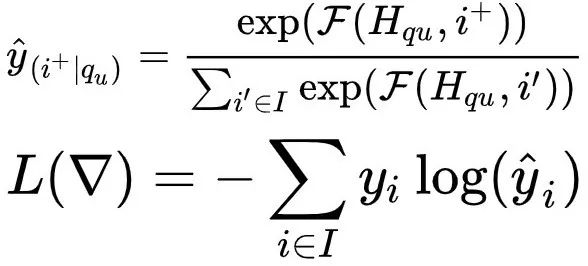
由于基于我们的商品集合在千万级别,上述公式中分母巨大,因此将喜好分输入到基于采样的归一化指数(sampled softmax)函数,以近似在全集合上的商品分数分布。
噪音平滑
我们往sampled softmax函数中引入温度参数以平滑弱监督训练数据中存在的相关性差的噪声影响。通过平滑操作可以降低模型对某些item置信度,提升多样性,减少由拟合点击样本带来的相关性差的影响,大幅提升模型召回结果的相关性,具体公式如下。
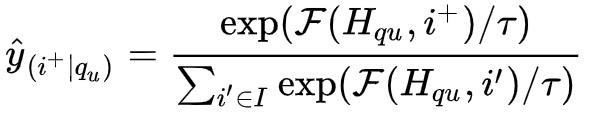
值得注意的是,该思路不仅适用于softmax函数,同时还适用于pairwise函数(通过调整pairwise的margin值,也能提升样本的相关性,并且由我们的实验现象看,随着margin值的增大,相关性评测分数下降)。
难负样本生成
我们尝试了两种难负样本生成的方式,一种是采用在线插值方法,从正样本和负样本中生成相关性难负样本并加入到负样本集合中,接着分别计算用户向量与正样本和负样本集合的内积分数。

首先计算用户query向量与随机采样得到的负样本向量内积的分数,选取top N个距离query向量比较近的负样本放入集合中。通过均匀分布中采样,将正样本向量和选出的负样本向量做插值运算生成难负样本,越接近于1,生成的样本越难。
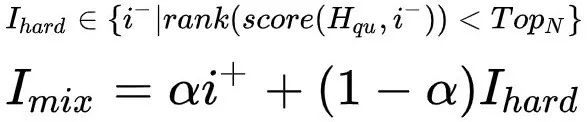
另一种是生成式难负样本,对一个item title,使用querytagging对词粒度打标后,我们将相关性信号重要的词(品类、型号、品牌、风格、人名、书名、电影名等)mask掉,比如“赛罗 奥特曼 的 男童 连体 衣服”转换成“[MASK] 奥特曼 的 [MASK] 连体 衣服”,然后用一个文本生成器输入这个转换后的title,预测被mask掉的词,生成一个新的title,可能为“迪迦 奥特曼 的 成人 衣服”,将新的title作为相关性难负样本放到我们上面提到的改进loss里。这样我们可以使模型从样本角度学习到相关性的exact match和term importance关键词信号。

有了难负样本之后,我们将其加入softmax函数的分母中,继而参与到最后的loss计算中:
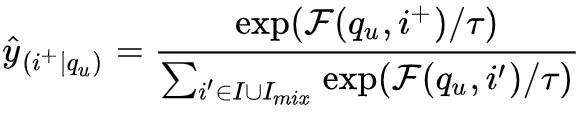
小结

▐ 语义与个性化建模
多粒度语义单元
从不同层面挖掘用户搜索查询词的语义信息,形成多粒度语义查询矩阵表示。具体地,使用用户搜索词的uni-gram、bi-gram、分词序列和历史相关搜索词序列组成特征矩阵,使用平均值池化或者transformer来建模向量表达。
比如,给定搜索词“红色连衣裙”,分词序列为
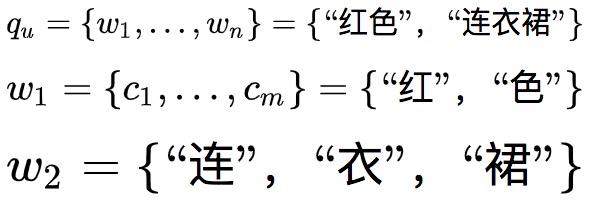
历史相关搜索词

语义建模向量表达为:
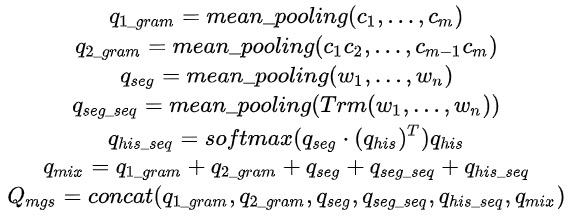
用户个性化异构行为表达
区别于网页搜索,在我们多年的实践中发现,考虑用户在淘宝存在多周期、多类型的历史行为,对于无论是推荐还是搜索、排序还是召回,都有显著的效果增益。在我们模型中,我们主要收集了用户实时行为 、近期行为
、近期行为 (最近100个商品点击)、长期行为
(最近100个商品点击)、长期行为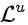 (一个月内的行为),长期行为还包括用户在商品、类目、店铺、品牌维度的点击、加购、购买、收藏行为序列。使用常用的行为序列建模方法,比如LSTM、transformer等得到相应的行为序列表达向量
(一个月内的行为),长期行为还包括用户在商品、类目、店铺、品牌维度的点击、加购、购买、收藏行为序列。使用常用的行为序列建模方法,比如LSTM、transformer等得到相应的行为序列表达向量 。此外与推荐不同的是,用户历史行为存在于当前搜索query完全不相关的情况,为此我们给每一个行为序列向量加了一个0向量来减轻噪音的影响,比如:
。此外与推荐不同的是,用户历史行为存在于当前搜索query完全不相关的情况,为此我们给每一个行为序列向量加了一个0向量来减轻噪音的影响,比如:

多粒度语义下用户个性化表示矩阵
计算多粒度语义矩阵与用户历史行为序列之间的重要性加权权重,以聚合行为序列中与当前查询词相关的个性化用户向量表示,得到 。比如:
。比如:

动态融合语义与个性化行为表达
个性化行为如何更合适地与用户搜索语义意图结合是学术界和工业界的热点话题。这里我们直接参考了现有电商商品搜索个性化相关工作的结论:个性化在越往头部query方向起到正向作用,在长尾方向作用降低甚至会对搜索结果有损。在模型设计上,也参考了这些研究工作的方法,使用自注意力机制融合多粒度语义查询矩阵和用户个性化表示矩阵的关系,得到兼顾用户查询语义相关性及其个性化偏好的用户向量表示。
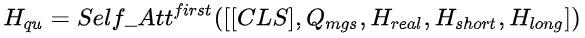
商品建模
商品向量表达 使用了商品ID和标题文本,通过简单的向量相加得到。
使用了商品ID和标题文本,通过简单的向量相加得到。

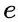 是商品ID的embedding,
是商品ID的embedding, 是全连接层矩阵参数,
是全连接层矩阵参数,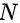 是商品标题里词的数量,
是商品标题里词的数量,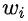 是标题里词的embedding。
是标题里词的embedding。
系统架构
线上服务链路,向量召回作为多通道召回的其中一路,加入到已有召回系统上,简略架构图如下图所示。
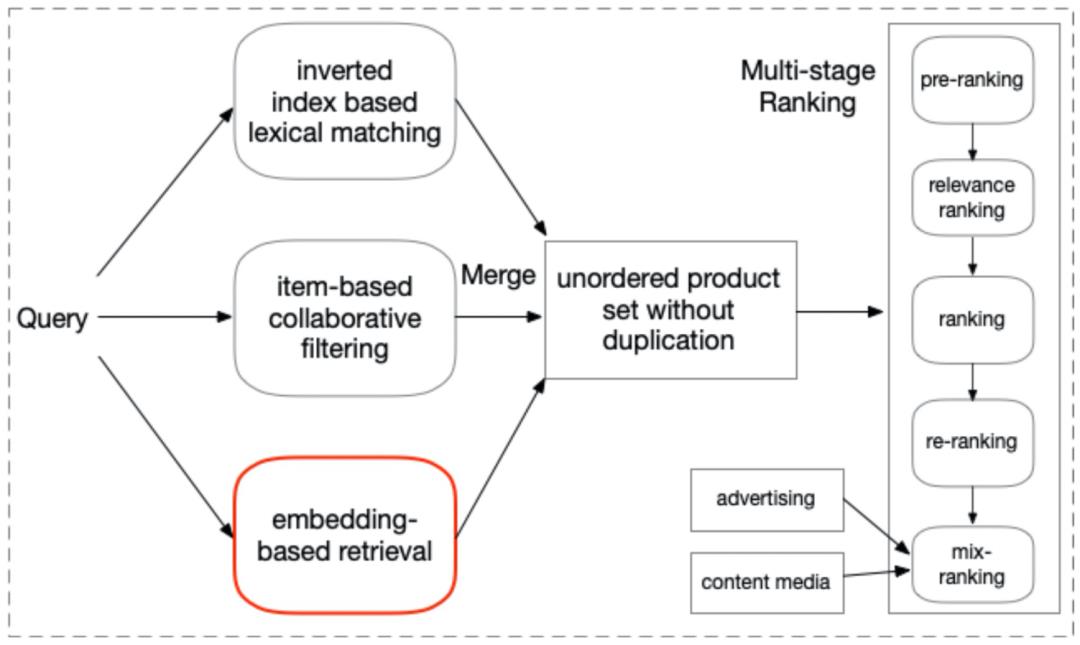
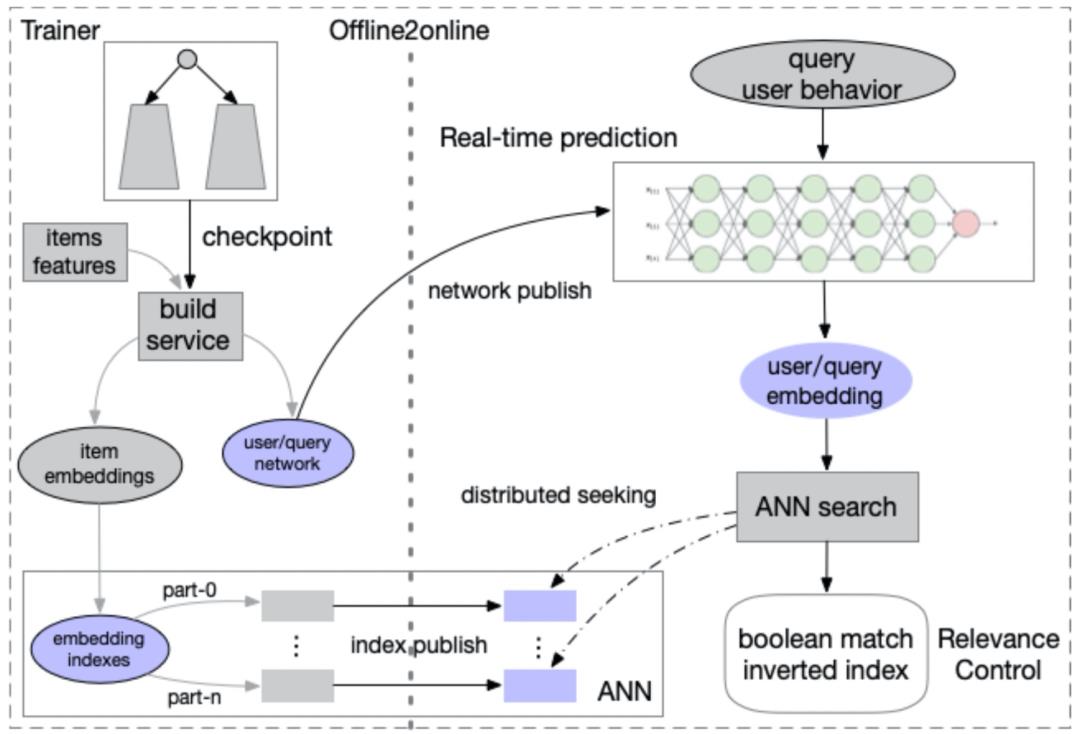
向量召回具体的线上大规模训练与部署我们采用了offline2online的架构,一次查询在所有商品候选中生效。除向量召回部署通用流程外,我们又增加了一个相关性控制模块,作为对模型相关性增强的补充。该模块结合了文本倒排索引,对向量召回的结果做过滤操作,过滤掉指定的搜索关键属性词。比如用户搜索“阿迪达斯运动鞋”,品牌“阿迪达斯”和品类“鞋”是核心属性词,对不包含这两个词的召回商品做过滤操作,从而高度保障用户搜索体验。
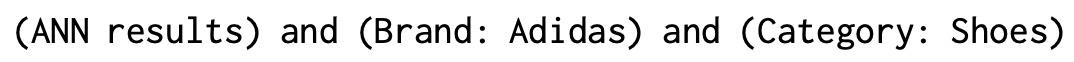
实验
▐ 离线评价
我们收集淘宝搜索的线上日志(点击、成交),来计算模型检索的topK的召回率和相关性。计算曝光点击、成交的商品集合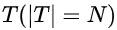 是否命中模型预测的top K结果来计算
是否命中模型预测的top K结果来计算 Recall@1000。鉴于召回结果集合的规模,我们使用线上相关性模型打分来替代人工评测,计算召回商品的相关性good率,以此来辅助指导相关性方向的建模工作。而线上A/B实验中,我们则使用了人工评测来衡量相关性体验。
Recall@1000。鉴于召回结果集合的规模,我们使用线上相关性模型打分来替代人工评测,计算召回商品的相关性good率,以此来辅助指导相关性方向的建模工作。而线上A/B实验中,我们则使用了人工评测来衡量相关性体验。
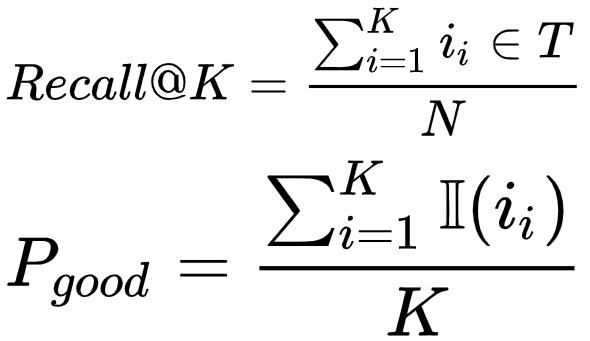
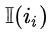 表示商品是否属于当前query的相关商品集合。此外,为了增加评测难度,我们还加入了一份由搜索点击引流到场景外成交的相关商品日志来评测。一共采样第N+1天上述类型的150多万条user query日志进行评测,使用前N天数据训练模型,模型离线评测训练使用与线上相同的全量数据进行。预测top K首先模拟线上全图化流程离线导出user和item向量,内积检索使用公司内部的Proxima建进行离线向量召回。Proxima离线的使用,我们尽可能与线上向量内积算法的配置保持一致,比如一致的建索引、查询索引参数,索引准确率,是否使用MIPS转换等。
表示商品是否属于当前query的相关商品集合。此外,为了增加评测难度,我们还加入了一份由搜索点击引流到场景外成交的相关商品日志来评测。一共采样第N+1天上述类型的150多万条user query日志进行评测,使用前N天数据训练模型,模型离线评测训练使用与线上相同的全量数据进行。预测top K首先模拟线上全图化流程离线导出user和item向量,内积检索使用公司内部的Proxima建进行离线向量召回。Proxima离线的使用,我们尽可能与线上向量内积算法的配置保持一致,比如一致的建索引、查询索引参数,索引准确率,是否使用MIPS转换等。
由于淘宝搜索早已使用多路召回,而且每路召回的特点不同,每类query类型的特点也不同,我们又将Recall和相关性分数拆分成在query类型和曝光商品召回来源类型下观测。比如模型在长尾query下Recall提升,说明模型在往长尾方向优化;如果模型Recall在top query下的Recall提升,说明模型在往个性化方向迭代。通过这种方式来辅助我们判断模型优化走向。 也正是由于多路召回存在,离线单模型Recall并不能直接反应线上效果,因为可能与已有召回重复。我们在线上做了计算逻辑等价于离线recall的指标——线上Recall,作为中间指标来参照,即计算线上所有向量召回(包括与其他路重叠)点击或成交在所有点击或成交中的占比。根据我们的上线经验,离线Recall增长,必然会使得线上向量召回单模型增强,线上Recall也会增长。由于线上链路对召回有很多其他限制,离线评测环境不能与线上完全保证一致,因此线下Recall数值上也不能与线上完全一致,只能提供给线上的一个upper bound参考。我们一直使用这个指标来判断模型线上是否正常服务,优化是否在线上起生效。线上成交是否增长,还是要看模型优化是否提供了正向的增益,但已有历史数据无法做到这点,目前来看还是需要上线测试。
▐ 线上实验
我们替换掉原有的向量召回模型上线,线上多天A/B实验显示,用户展示商品的相关性人工评测good率提升0.3%的条件下,搜索成交笔数和GMV都有显著提升。

▐ 消融实验
在这里,我们列了模型结构中提出的几个关键部分对召回模型的召回率、相关性的影响。
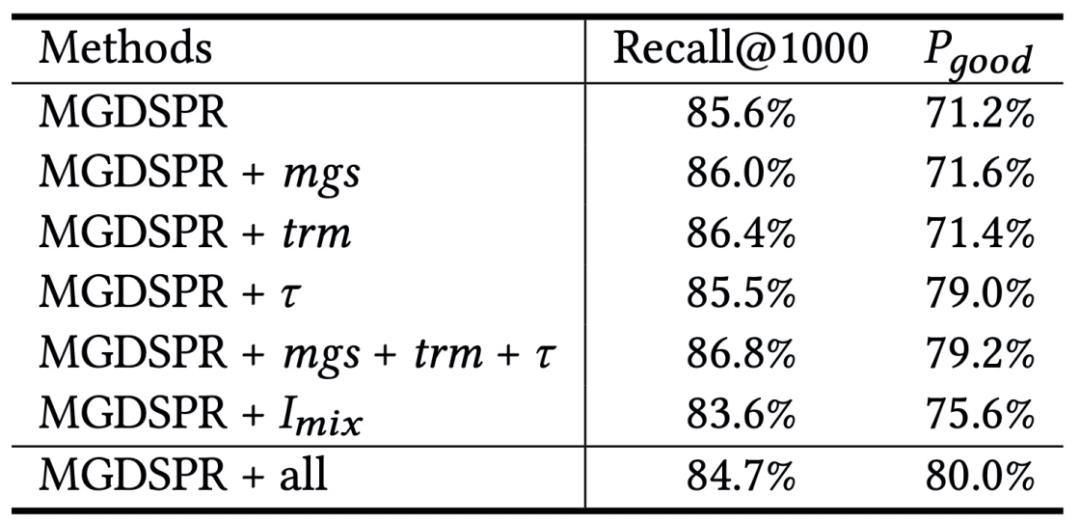
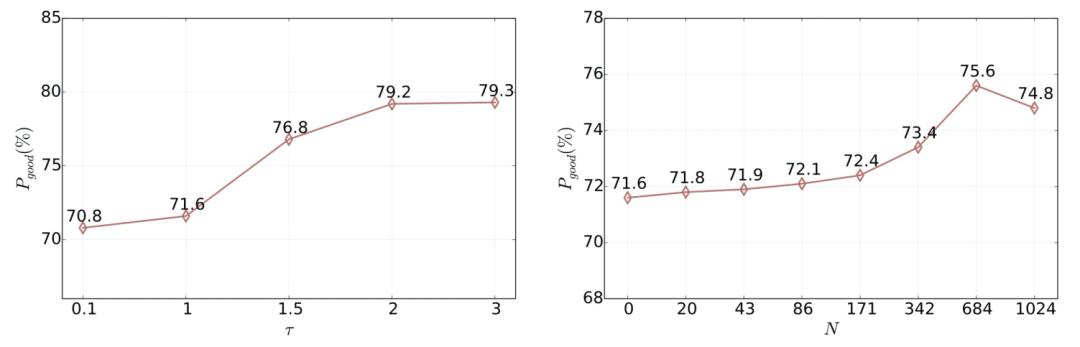
MGDSPR是基础版本的模型,不含mgs(多语义单元)、trm(self-attention动态融合语义和个性化表达)、 (softmax温度平滑)和
(softmax温度平滑)和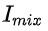 (难负样本)。可以看出样本的温度平滑和难负样本对优化模型相关性至关重要,我们对具体的超参做了更为细致的实验,如下图所示,温度越高、难负样本的数量N一定区间内越大,模型召回结果的相关性就越好。我们在召回率与相关性之间tradeoff,选择综合最优模型上线。
(难负样本)。可以看出样本的温度平滑和难负样本对优化模型相关性至关重要,我们对具体的超参做了更为细致的实验,如下图所示,温度越高、难负样本的数量N一定区间内越大,模型召回结果的相关性就越好。我们在召回率与相关性之间tradeoff,选择综合最优模型上线。
我们还实验了使用softmax相比传统pairwise方式的损失函数的优势,模型召回率更高,收敛更快,加速线上学习迭代。

总结和展望
如何让搜索系统同时兼备用户搜索相关性和个性化的能力,是电商搜索的核心问题之一。往往在真实业务背景下,相关性模块为了保证用户体验,对展示的商品控制严了,就会降低搜索效率(如成交),解决该问题比较好的方法就是在召回源头截断掉bad case,同时不失检索商品的个性化能力。我们的工作在这一方向上迈出了一小步,但仍需深入探索。此外,我们还发现,因为线上召回模块往往是多通道召回,向量召回与其他召回来源的商品存在比较大的交集,解决向量召回与其他通道召回的多样性也是未来亟待解决的问题,需要更加明确向量召回提供的增益方向。
参考文献
[1] Fan, Miao, et al. "MOBIUS: Towards the Next Generation of Query-Ad Matching in Baidu's Sponsored Search." Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019.
[2] Ai, Qingyao, et al. "A zero attention model for personalized product search." Proceedings of the 28th ACM International Conference on Information and Knowledge Management. 2019.
[3] Ai, Qingyao, et al. "Learning a hierarchical embedding model for personalized product search." Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2017.
[4] Bi, Keping, Qingyao Ai, and W. Bruce Croft. "A Transformer-based Embedding Model for Personalized Product Search." arXiv preprint arXiv:2005.08936 (2020).
[5] Guo, Jiafeng, et al. "A deep relevance matching model for ad-hoc retrieval." Proceedings of the 25th ACM International on Conference on Information and Knowledge Management. 2016.
[6] Huang, Jui-Ting, et al. "Embedding-based retrieval in facebook search." Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020.
✿ 拓展阅读


作者|福豆
编辑|橙子君
出品|阿里巴巴新零售淘系技术


以上是关于SIGKDD2021 | 淘宝搜索向量化召回实践的主要内容,如果未能解决你的问题,请参考以下文章
ElasticsearchElasticsearch 搜索体验可量化的指标 查准率(精确率)查全率(召回率)