python中yield的用法
Posted 呆呆象呆呆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python中yield的用法相关的知识,希望对你有一定的参考价值。
0 理解说明
- 功能1:把
yield看做return。就是在程序中yield处返回某个值,返回之后程序就不再往下运行了。他们都在函数中使用,并履行着返回某种结果的职责。 - 功能2:同时还是一个生成器
generator,有return的普通函数直接返回所有结果,程序终止不再运行,并销毁局部变量;而有yield的函数则返回一个可迭代的生成器generator对象,你可以使用for循环或者调用next()方法,send()方法遍历生成器对象来提取结果。
1 举2个例子说明yield生成迭代器:
python生成器有两个主要方法,一个是send一个是next。
next函数
next调用,相当于启动生成器,会从生成器函数的第一行代码开始执行,直到第一次执行完yield语句后,跳出生成器函数。然后第二个next调用,进入生成器函数后,从yield语句的下一句语句开始执行,然后重新运行到yield语句,执行后,跳出生成器函数后面再次调用next,依此类推。即执行一次next则调用一次生成器函数,直至抛出不可迭代的错误。
def fun_yield():
print("starting fun yield")
while True:
res = yield 4
print("判断yield之后是否继续执行",res)
g = fun_yield() # 调用这个函数只是会得到一个生成器
print("函数结果是一个生成器:",g)
print("对此生成器还是进行调用:")
print("第一次调用")
print("生成器的返回值",next(g))
print("第二次调用")
print("生成器的返回值",next(g))
print("第三次调用")
print("生成器的返回值",next(g))
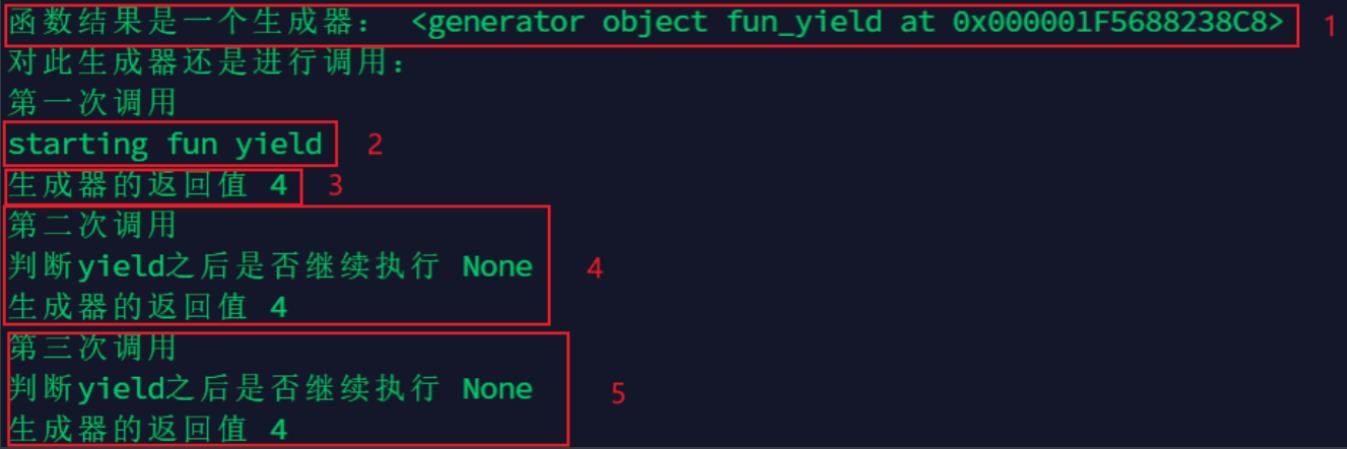
- 程序开始执行以后,因为
fun_yield函数中有yield关键字,所以函数并不会真的执行,而是先得到一个生成器g(相当于一个对象),结果1可以看出 - 直到调用
next方法,fun_yield函数正式开始执行,先执行函数中的print("starting fun yield"),然后进入while循环,结果2可以看出 - 程序遇到
yield关键字,然后把yield理解为return,return了一个4之后,程序停止,并没有执行后面的print("判断yield之后是否继续执行",res)操作,此时next(g)语句执行完成,所以输出的前两行,接下来准备运行第二次调用,结果3可以看出 - 又开始执行下面的
print("生成器的返回值",next(g)),这个时候和上面那个差不多,不过不同的是,这个时候是从刚才那个next程序停止的地方开始执行的,也就是要执行print("判断yield之后是否继续执行",res)操作,这时候要注意,这个时候赋值操作的右边是没有值的(因为刚才那个是return出去了,并没有给赋值操作的左边传参数,也就相当于说res里面是没有内容的),所以这个时候res赋值是None,所以接着下面的输出就是None,结果4可以看出 - 之后的程序会继续在
while里执行,又一次碰到yield,这个时候同样return出4,结果5可以看出
说明:
- 理解
yield和return与generator的关系和区别:- 带
yield的函数是一个生成器,而不是一个函数了,每次通过generator迭代中会从yield处得到return的返回数据
- 带
- 这个生成器有一个函数就是
next函数,next就相当于“下一步”生成哪个数,这一次的next开始的地方是接着上一次的next停止的地方执行的,所以调用next的时候,生成器并不会将函数从头开始执行,只是接着上一步停止的地方开始,然后遇到yield后,return出要生成的数,此步就结束。
send函数
send函数和next函数其实很相似,唯一的区别在于send函数可以传入值,而next函数不能传值,可以这样说:
next(f) = f.send(None)
第一次调用时不能使用send发送一个非None的值,否则会出错的,因为没有yield语句来接收这个值。
这里给出一个例子:
def fun_yield():
print("starting fun yield")
while True:
res = yield 4
print("判断yield之后是否继续执行",res)
g = fun_yield() # 调用这个函数只是会得到一个生成器
print("函数结果是一个生成器:",g)
print("对此生成器还是进行调用:")
print("第一次调用")
print(next(g))
print("生成器的返回值",g.send(1))
print("第二次调用")
print("生成器的返回值",g.send(2))
print("第三次调用")
print("生成器的返回值",g.send(3))
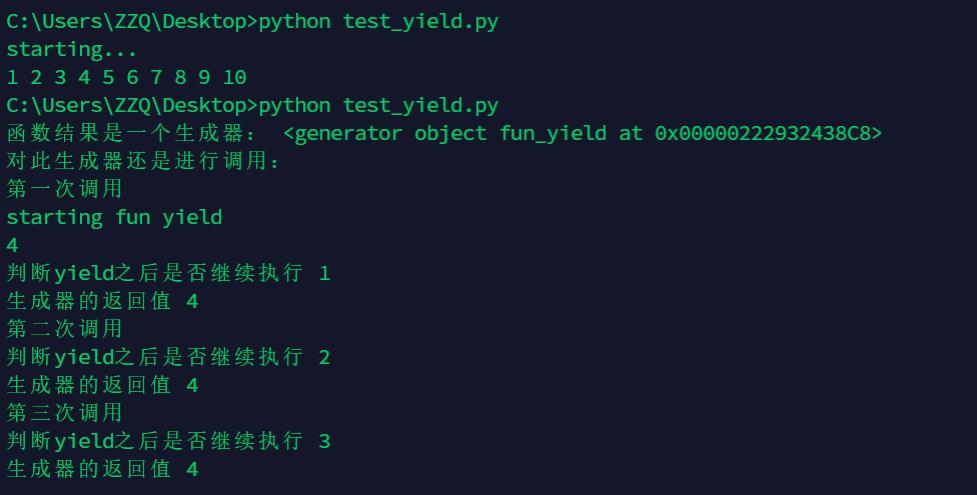
主要变化:
之前res的值是None,现在变成1,2,3,因为send是发送参数给res,因为上面讲到,return的时候,并没有把4赋值给res,下次执行的时候只好继续执行赋值操作,只好赋值为None了。
如果用send的话,出现的情况是,先接着上一次(yield 4之后)执行,先把接受到的1,2,3等赋值给了res,然后执行打印的作用,程序执行再次遇到yield关键字,yield会返回后面的值后,程序再次暂停,直到再次调用next方法或send方法。
2 常用的代码例子
例子1 输出斐波那契数列的前N个数(比较常用的使用方式)
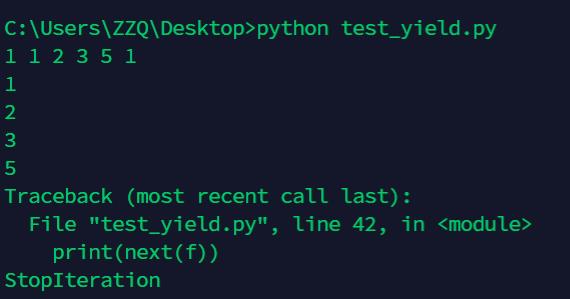
调用fab(5)不会执行fab函数,而是返回一个generator对象。在for循环执行时,每次循环都会执行fab函数内部的代码,执行到yield b时,fab函数就返回一个迭代值,下次迭代时,代码从yield b的下一条语句继续执行,而函数的本地变量看起来和上次中断执行前是完全一样的,于是函数继续执行,直到再次遇到yield。
def fab(max):
n, a, b = 0, 0, 1
while n < max:
yield b # 使用 yield
a, b = b, a + b
n = n + 1
for n in fab(5):
print(n,end = " ")
f = fab(5)
print(next(f))
print(next(f))
print(next(f))
print(next(f))
print(next(f))
print(next(f))
例子2 使用types和inspect库判断是否为生成器(关于类型判断的说明)
def fab(max):
n, a, b = 0, 0, 1
while n < max:
yield b # 使用 yield
a, b = b, a + b
n = n + 1
from inspect import isgeneratorfunction
print(isgeneratorfunction(fab))
print(isgeneratorfunction(fab(5)))
import types
print(isinstance(fab, types.GeneratorType) )
print(isinstance(fab(5), types.GeneratorType))
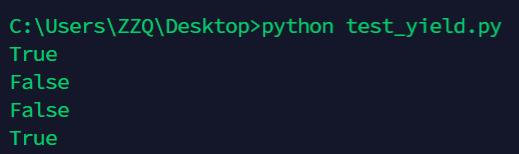
要注意区分fab和fab(5)
fab是一个generator function,而fab(5)是调用generator function返回的一个generator,好比类的定义和类的实例的区别,fab是无法迭代的,而fab(5)是可迭代的。
例子3 多个生成器不影响
每次调用含有yield的函数行成一个新的generator实例,各实例互不影响。
def fab(max):
n, a, b = 0, 0, 1
while n < max:
yield b # 使用 yield
a, b = b, a + b
n = n + 1
from inspect import isgeneratorfunction
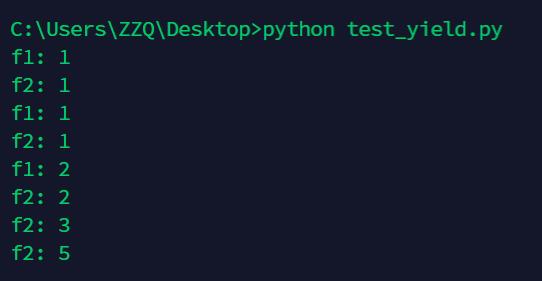
f1 = fab(3)
f2 = fab(5)
print("f1:",next(f1))
print("f2:",next(f2))
print("f1:",next(f1))
print("f2:",next(f2))
print("f1:",next(f1))
print("f2:",next(f2))
print("f2:",next(f2))
print("f2:",next(f2))
例子4 文件读取
如果直接对文件对象调用read()方法,会导致不可预测的内存占用。好的方法是利用固定长度的缓冲区来不断读取文件内容。通过yield,不再需要编写读文件的迭代类,就可以轻松实现文件读取:
def read_file(fpath):
BLOCK_SIZE = 1024
with open(fpath, 'rb') as f:
while True:
block = f.read(BLOCK_SIZE)
if block:
yield block
else:
return
3 yield 优势
为什么用这个生成器,是因为如果用List的话,会占用更大的空间。这个时候range(1000)就默认生成一个含有1000个数的list了,所以很占内存。
for n in range(1000):
a=n
这个时候你可以用yield组合成生成器进行实现,也可以用xrange(1000)这个生成器实现
def foo(num):
print("starting...")
while num<10:
num=num+1
yield num
for n in foo(0):
print(n,end=" ")

Python 2 中的一个特性:内建函数 range 和 xrange。其中,range 函数返回的是一个列表,而 xrange 返回的是一个迭代器。在 Python 3 中,range 相当于 Python 2 中的 xrange;而 Python 2 中的 range 可以用 list(range()) 来实现。
之所以要提供这样的解决方案,是因为在很多时候,只是需要逐个顺序访问容器内的元素。大多数时候,不需要一口气获取容器内所有的元素。比方说,顺序访问容器内的前 5 个元素,可以有两种做法:
- 获取容器内的所有元素,然后取出前 5 个;
- 从头开始,逐个迭代容器内的元素,迭代 5 个元素之后停止。
显而易见,如果容器内的元素数量非常多(比如有 10 ** 8 个),或者容器内的元素体积非常大,那么后一种方案能节省巨大的时间、空间开销。
现在假设,我们有一个函数,其产出(返回值)是一个列表。而若我们知道,调用者对该函数的返回值,只有逐个迭代这一种方式。那么,如果函数生产列表中的每一个元素都需要耗费非常多的时间,或者生成所有元素需要等待很长时间,则使用 yield 把函数变成一个生成器函数,每次只产生一个元素,就能节省很多开销了。
LAST 参考文献
以上是关于python中yield的用法的主要内容,如果未能解决你的问题,请参考以下文章