Elasticsearch:在搜索中使用衰减函数(Gauss)
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:在搜索中使用衰减函数(Gauss)相关的知识,希望对你有一定的参考价值。
在我之前的文章 “Elasticsearch:使用 function_score 及 script_score 定制搜索结果的分数” 我有讲到 Decay 函数在搜索中的使用。在那里,我有一个例子讲述在规定的时间里,分数不进行衰减。同一的函数也可以适用于地理位置的搜索。位置搜索的范围在规定范围里可以不进行衰减,超过这个范围就会按照衰减函数进行衰减。
想象一下,你需要根据用户位置的接近程度对结果进行排序。完成此任务的方法之一是使用定位和衰减函数。 衰减函数可用于根据比例调整文档的相关性分数。
在我们的示例中,我们将注册一些餐厅,并从用户的位置返回最近的餐厅。
让我们创建我们的地图,现在我们将使用 geo_point 类型,因为我们将使用纬度和经度。
PUT restaurants
"mappings":
"properties":
"title":
"type": "text"
,
"location":
"type": "geo_point"
现在让我们插入一些文档:
POST restaurants/_bulk
"index":
"title":"McDonald's 1000","location":"lat" : -23.525920 ,"lon" : -46.650211
"index":
"title":"McDonald's Caneca","location":"lat" : -23.553720 ,"lon" : -46.652940
"index":
"title":"McDonald's Paulista","location":"lat" : -23.565920 ,"lon" : -46.650210
"index":
"title":"McDonald's - Shopping Pátio Higienópolis","location":"lat" : -23.582460 ,"lon" : -46.688560上面的命令将创建 4 个位置文档。假如我们想在位置 [-23.542719, -46.653965] 进行搜索。它们的相对位置关系如下:
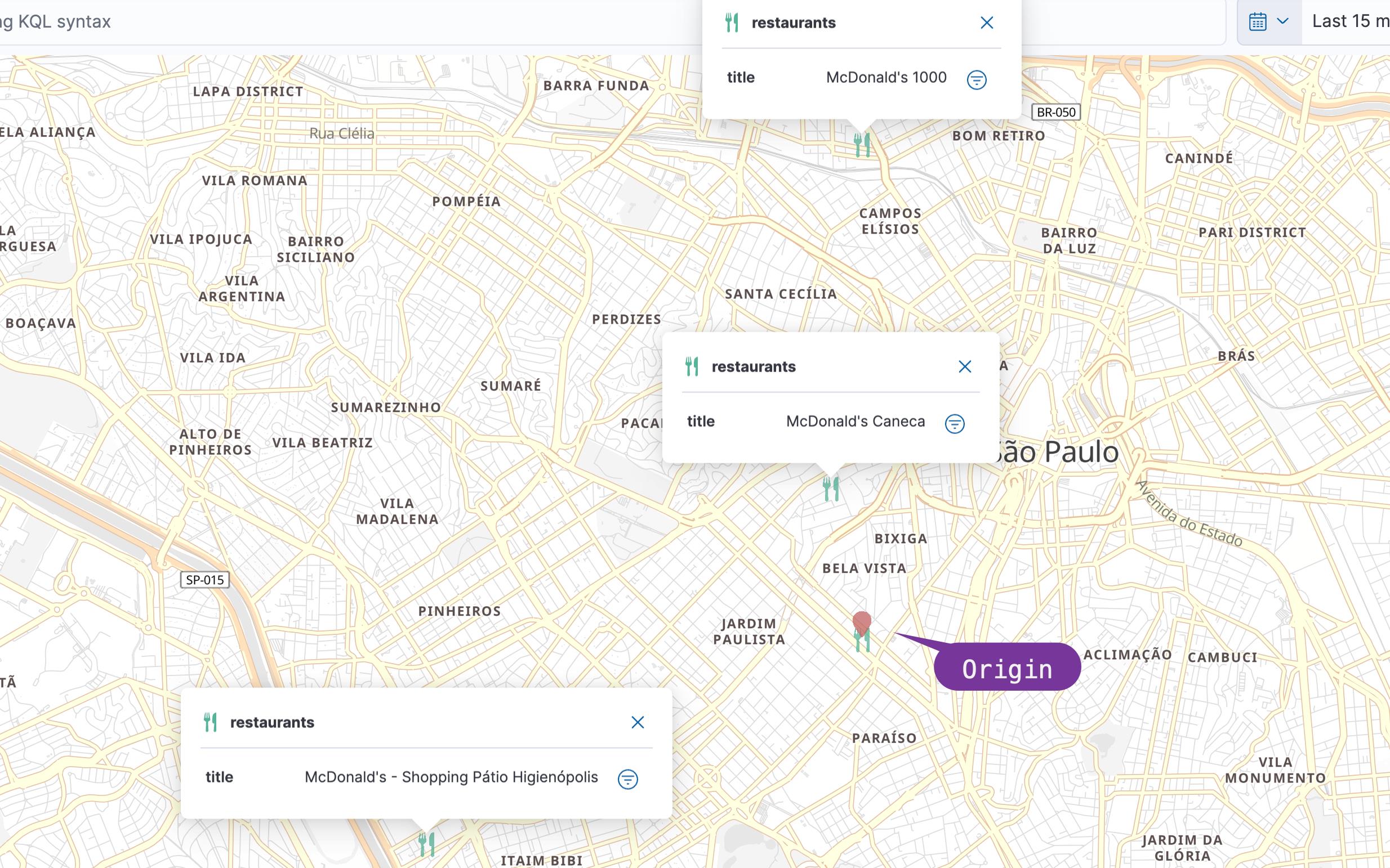
在我们的查询中,我们将使用 Function score query | Elasticsearch Guide [8.6] | Elastic 和 Gaussian 函数,我们希望距离半径 500 米的人获得最大得分(origin - offset <= value <= origin + offset)和 200m (scale) 分数将开始下降。根据 Gaussian function的曲线分布,超过一定的范围衰减非常之快,以至于很快到 0。

在第一个测试中,我们将使用原点 -23.561581、-46.659540。 此搜索的结果将是最接近的(请注意分数如何随着离原点越远而降低):
GET restaurants/_search?filter_path=**.hits
"query":
"function_score":
"query":
"match":
"title":
"query": "McDonald's"
,
"functions": [
"gauss":
"location":
"origin":
"lat": -23.542719,
"lon": -46.653965
,
"offset": "500m",
"scale": "200m",
"decay": "0.5"
,
"weight": 10
],
"boost_mode": "replace"
参数说明:
| 项目 | 说明 |
|---|---|
| origin | 用于计算距离的原点。 必须以数字字段的数字、日期字段的日期和地理字段的地理点的形式给出。 地理和数字字段必填。 对于日期字段,默认值为现在。 origin 支持日期数学(例如 now-1h)。 |
| scale | 所有类型都需要。 定义距离原点的距离 + 偏移量,在该距离处计算的分数将等于衰减参数。 对于地理字段:可以定义为数字+单位(1km,12m,...)。 默认单位是米。 对于日期字段:可以定义为数字+单位(“1h”、“10d”、… )。 默认单位是毫秒。 对于数字字段:任何数字。 |
| offset | 如果定义了偏移量,衰减函数将只计算距离大于定义的偏移量的文档的衰减函数。 默认值为 0。 |
| decay | decay 参数定义了如何在按比例给定的距离对文档进行评分。 如果没有定义衰减,则距离 scale 的文档将得分为 0.5。 |
上述查询在离 origin 开始的 200m + 500m 开始进行衰减。它的衰减因子为 0.5。在这个以 200m + 500m 为圆半径的文档得分值将保持不变。
运行上面查询的结果为:
"hits":
"hits": [
"_index": "restaurants",
"_id": "QxqBNYYB2XodIZsbBsV5",
"_score": 0.0010342363,
"_source":
"title": "McDonald's Caneca",
"location":
"lat": -23.55372,
"lon": -46.65294
,
"_index": "restaurants",
"_id": "QhqBNYYB2XodIZsbBsV5",
"_score": 1.2783469e-14,
"_source":
"title": "McDonald's 1000",
"location":
"lat": -23.52592,
"lon": -46.650211
,
"_index": "restaurants",
"_id": "RBqBNYYB2XodIZsbBsV5",
"_score": 3.5952473e-33,
"_source":
"title": "McDonald's Paulista",
"location":
"lat": -23.56592,
"lon": -46.65021
,
"_index": "restaurants",
"_id": "RRqBNYYB2XodIZsbBsV5",
"_score": 0,
"_source":
"title": "McDonald's - Shopping Pátio Higienópolis",
"location":
"lat": -23.58246,
"lon": -46.68856
]
正像我们看到的那样,搜索的结果是我们所期望的。从返回的分数来看在范围里的文档的分数不受影响,但是一旦超出范围,搜索到的文档的分数会被加权并得到衰减。
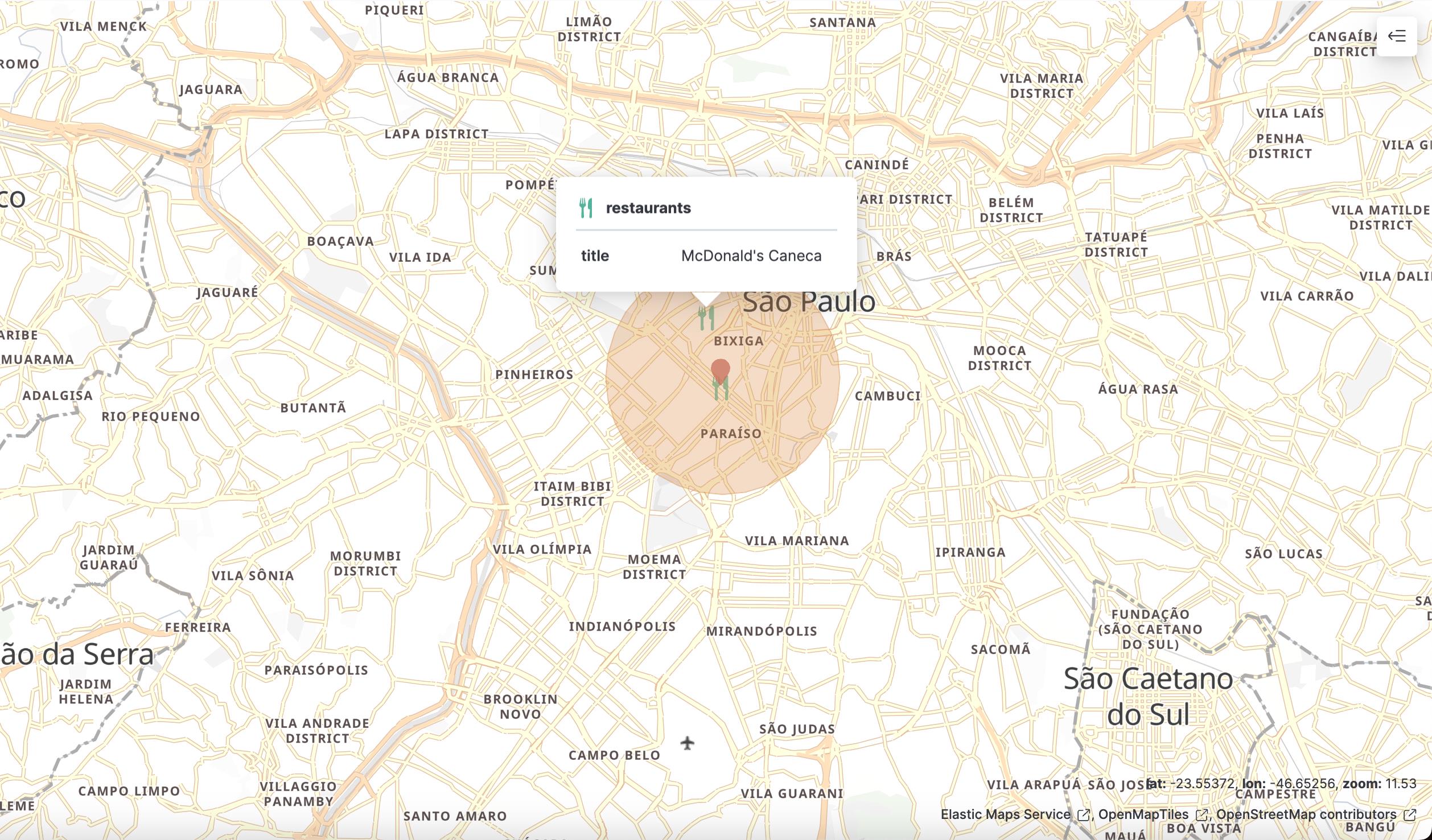
我们再次修改 origin 的位置到 -23.542719, -46.653965。它们的相对关系显示如下:
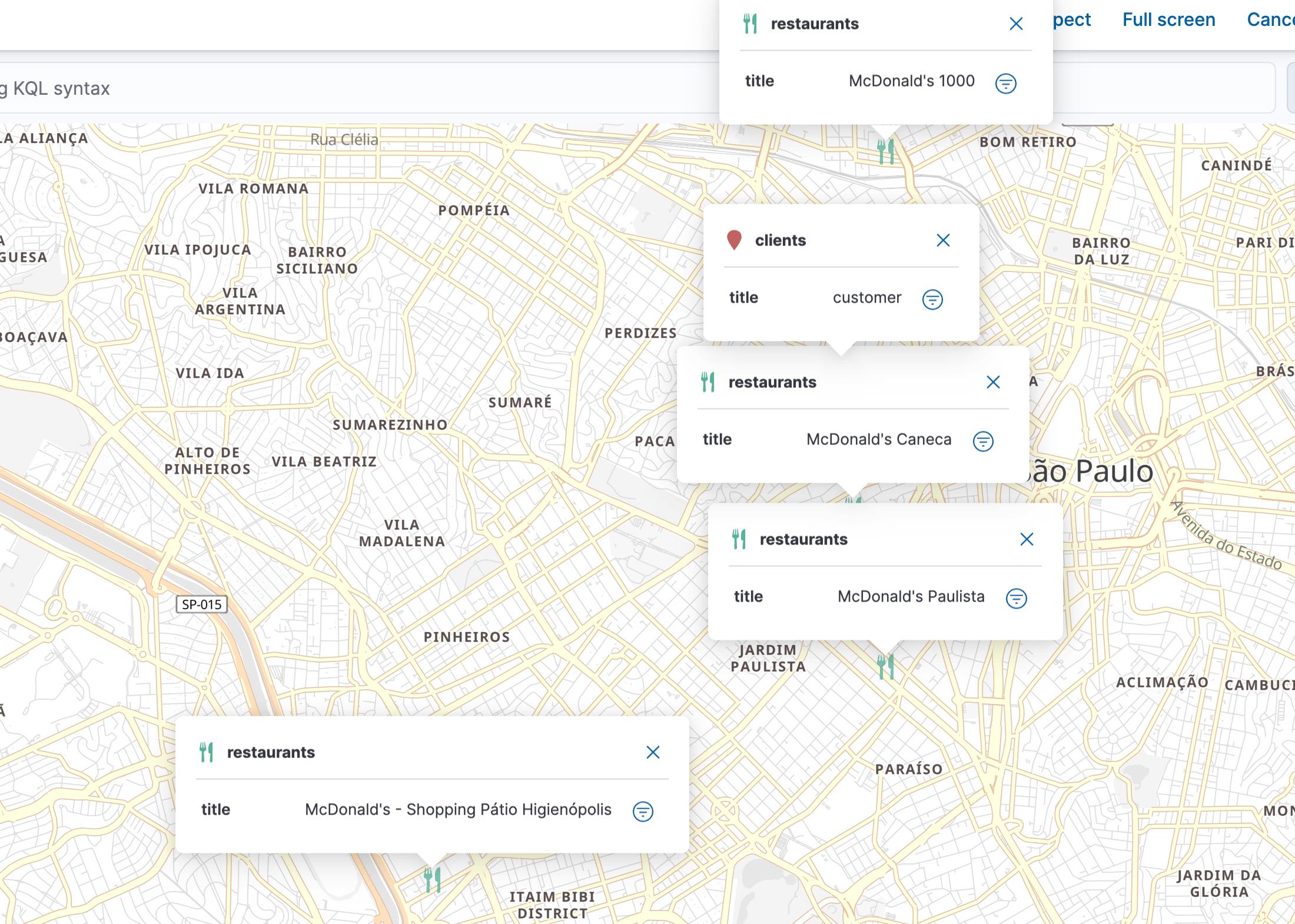
我们再次进行搜索:
GET restaurants/_search?filter_path=**.hits
"query":
"function_score":
"query":
"match":
"title":
"query": "McDonald's"
,
"functions": [
"gauss":
"location":
"origin":
"lat": -23.542719,
"lon": -46.653965
,
"offset": "500m",
"scale": "200m",
"decay": "0.5"
,
"weight": 10
],
"boost_mode": "replace"
我们可以看到如下的结果:
"hits":
"hits": [
"_index": "restaurants",
"_id": "QxqBNYYB2XodIZsbBsV5",
"_score": 0.0010342363,
"_source":
"title": "McDonald's Caneca",
"location":
"lat": -23.55372,
"lon": -46.65294
,
"_index": "restaurants",
"_id": "QhqBNYYB2XodIZsbBsV5",
"_score": 1.2783469e-14,
"_source":
"title": "McDonald's 1000",
"location":
"lat": -23.52592,
"lon": -46.650211
,
"_index": "restaurants",
"_id": "RBqBNYYB2XodIZsbBsV5",
"_score": 3.5952473e-33,
"_source":
"title": "McDonald's Paulista",
"location":
"lat": -23.56592,
"lon": -46.65021
,
"_index": "restaurants",
"_id": "RRqBNYYB2XodIZsbBsV5",
"_score": 0,
"_source":
"title": "McDonald's - Shopping Pátio Higienópolis",
"location":
"lat": -23.58246,
"lon": -46.68856
]
这是介绍衰减函数的方法之一,我希望它有用。
以上是关于Elasticsearch:在搜索中使用衰减函数(Gauss)的主要内容,如果未能解决你的问题,请参考以下文章