Swift之深入解析Core Data数据管理的集成指南
Posted Forever_wj
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Swift之深入解析Core Data数据管理的集成指南相关的知识,希望对你有一定的参考价值。
一、Core Data 简介
① 什么是 Core Data?
- CoreData 是 ios SDK 里的一个很强大的框架,允许开发者以面向对象的方式存储和管理数据,使用 CoreData 框架,开发者可以轻松有效地通过面向对象的接口管理数据。
- CoreData 是一个模型层的技术,可以帮助建立代表程序状态的模型层。CoreData 也是一种持久化技术,能将模型对象的状态持久化到磁盘,但它最重要的特点是:不仅是一个加载和保存数据的框架,还能和内存中的数据很好的共事。在数据操作过程中,Core Data 无需编写任何 SQL 语句。
- CoreData 使用包括实体和实体间的关系,以及查找符合某些条件实体的请求等内容。开发者可以在纯对象层上查找与管理这些数据,而不必担心存储和查找的实现细节。
- CoreData 框架最早出现在 Mac OS 10.4 Tiger 与 iOS 3.0 系统,经过成千上万的应用程序以及数以百万用户的反复验证,CoreData 确实已经是一套非常成熟的框架,它利用 Objective-C 语言和运行时,巧妙地集成 CoreFoundation 框架,是一个易于使用的框架,不仅可以优雅地管理对象图,而且在内存管理方面表现异常优异。
- CoreData 不是一个数据库,不要用数据库的眼光去看待 CoreData,它不是应用程序的数据库,也不是将数据持久化保存到数据库的 API,它是一个用于管理对象图的框架,可以把对象图写入磁盘从而持久化保存。
② Core Data 特点
- 支持对象改变过程管理,支持撤销和重做;
- 关系维护(例如删除一张照片的同时,会在拍照者中删除对应的指针);
- 惰性加载,部分加载来降低内存(在需要使用数据的时候再加载);
- 属性值检查(例如:保证年龄在0-200岁),保证数据有意义;
- Schema 迁移:Schema 用来描述对象(例如:name,age,sex 描述一个人),CoreData 能够适应 Schema 的改变;
- NSFetchedResultsController 来更好支持 Tableview;
- 完整的支持 KVC/KVO;
- 支持复杂的数据查询;
- 支持 Merge policies(例如:两个线程对同一个数据改变的情况)。
③ Core Data 架构
- Core Data 的完整架构,如下图所示:

- 大部分情况下的架构:

- 分析:
-
- NSManagedObjectContext 可以理解为是一个容器,从持久化存储(文件)中查询的数据在这个容器中形成对象图,对这些对象图中的对象操作都会存储在这个容器里,直到发出指令让容器中的内容同步到磁盘;
-
- NSManagedObject 是 NSManagedObjectContext 对象图中的实际对象,由 NSManagedObjectContext 管理,NSManagedObjectContext 会存储这些对象的变化来支持重做和撤销;
-
- NSPersistent Store 负责把对象图中的信息 map 到实际的存储信息,NSPersistentStoreCordinator 存储调度器:负责将数据保存到磁盘的;
-
- SQLite 和 FileSystem 是保存到持久化存储的文件,CoreData 支持 SQLite 的数据格式,但是需注意:coreData 不是 DBMS,并不能管理 SQLite。
④ Core Data 与应用、磁盘存储的关系
- Core Data 比 SQLite 做了更进一步的封装,SQLite 提供了数据的存储模型,并提供了一系列 API,可以通过 API 读写数据库,去处理想要处理的数据。但是 SQLite 存储的数据和编写代码中的数据(比如一个类的对象)并没有内置的联系,必须我们自己编写代码去一一对应。
- 而 Core Data 却可以解决一个数据在持久化层和代码层的一一对应关系,也就是说,处理一个对象的数据后,通过保存接口,它可以自动同步到持久化层里,而不需要去实现额外的代码。这种“对象→持久化”方案叫“对象→关系映射”(英文简称 ORM)。
- Core Data 还提供了很多有用的特性,比如回滚机制,数据校验等,它与应用、磁盘存储的关系如下:

二、数据模型
① 数据模型文件:Data Model
- 当使用 Core Data 时,需要一个用来存放数据模型的地方,数据模型文件就是要创建的文件类型,它的后缀是 .xcdatamodeld,在创建工程的时候,勾选 Use Core Data 创建:

- 或者在项目中选新建文件→Data Model 即可创建:

- 系统默认提供的命名为 Model.xcdatamodeld,以 Model.xcdatamodeld 作为示例的文件名,这个文件就相当于数据库中的“库”。通过编辑这个文件,就可以去添加定义想要处理的数据类型。
② 数据模型中的表格:Entity
- 当在 Xcode 中点击 Model.xcdatamodeld 时,会看到苹果提供的编辑视图,其中有个醒目的按钮 Add Entity:

- 什么是 Entity 呢?中文翻译叫“实体”,如果把数据模型文件比作数据库中的“库”,那么 Entity 就相当于库里的“表格”。简单理解,Entity 就是定义数据表格类型的名词。例如,这个数据模型是用来存放图书馆信息的,那么很自然的,会想建立一个叫 Book 的 Entity。
- 注意:创建 Entity 实体的首字母必须为大写。
③ 属性 Attributes
- 当建立一个名为 Book 的 Entity 时,会看到视图中有栏写着 Attributes,我们知道,当定义一本书时,自然要定义书名、书的编码等信息,这部分信息叫 Attributes,即书的属性:
| 属性名 | 类型 |
|---|---|
| name | String |
| isbm | String |
| page | Integer32 |

- 同理,也可以再添加一个读者:Reader 的 Entity 描述,如下:
| 属性名 | 类型 |
|---|---|
| name | String |
| idCard | String |

④ 关系 Relationship
- 在使用 Entity 编辑时,除了看到 Attributes 一栏,还看到下面有 Relationships 一栏,这栏是做什么的?
- 回到示例中来,当定义图书馆信息时,刚书籍和读者的信息,但这两个信息彼此是孤立的,而事实上它们存在着联系。比如一本书,它被某个读者借走了,这样的数据该怎么存储呢?直观的做法是再定义一张表格来处理这类关系,但是 Core Data 提供了更有效的办法:Relationship。
- 从 Relationship 的思路来思考,当一本书 A 被某个读者 B 借走,可以理解为这本书 A 当前的“借阅者”是该读者 B,而读者 B 的“持有书”是 A。从以上描述可以看出,Relationship 所描述的关系是双向的,即 A 和 B 互相以某种方式形成了联系,而这个方式是我们来定义的。
- 在 Reader 的 Relationship 下点击 + 号键,然后在 Relationship 栏的名字上填 borrow,表示读者和书的关系是“借阅”,在 Destination 栏选择 Book,这样,读者和书籍的关系就确立了,如下所示:

- 对于第三栏,Inverse 却没有东西可以填,这是为什么?因为现在定义了读者和书的关系,却没有定义书和读者的关系。因为关系是双向的,就好比定义了 A 是 B 的父亲,那也要同时去定义 B 是 A 的儿子一个道理,计算机不会帮我们打理另一边的联系。
- 理解了这点,开始选择 Book 的一栏,在 Relationship 下添加新的 borrowBy,Destination 是 Reader,这时候点击 Inverse 一栏,会发现弹出了borrowBy,直接点上,这是因为在定义 Book 的 Relationship 之前,已经定义了 Reader 的 Relationship 了,所以电脑已经知道了读者和书籍的关系,可以直接选上。而一旦选好了,那么在 Reader 的 Relationship 中,我们会发现 Inverse 一栏会自动补齐为 borrowBy,这是因为电脑这时候已经完全理解了双方的关系,自动做了补齐。

⑤ “一对一”和“一对多”:to one 和 to many
- 建立 Reader 和 Book 之间的联系的时候,发现它们的联系逻辑之间还漏了一个环节:假设一本书被一个读者借走了,它就不能被另一个读者借走,而当一个读者借书时,却可以借很多本书,也就是说,一本书只能对应一个读者,而一个读者却可以对应多本书,这就是“一对一→to one”和“一对多→to many”。
- Core Data 允许配置这种联系,具体做法就是在 RelationShip 栏点击对应的关系栏,它将会出现在右侧的栏目中(栏目如果没出现可以在 Xcode 右上角的按钮调出,如果点击后栏目没出现 Relationship 配置项,可以多点击几下,这是 Xcode 的 bug)。
- 在 Relationship 的配置项里,有一项项名为 Type,点击后有两个选项,一个是 To One(默认值),另一个就是 To Many。
-
- Book 与 Reader 的 Relationship 如下:

-
- Reader 与 Book 的 Relationship 如下:

- 通过改变实体的展示样式,能够帮助我们更加直观的看到它们之间的关系:

三、Core Data 的主仓库
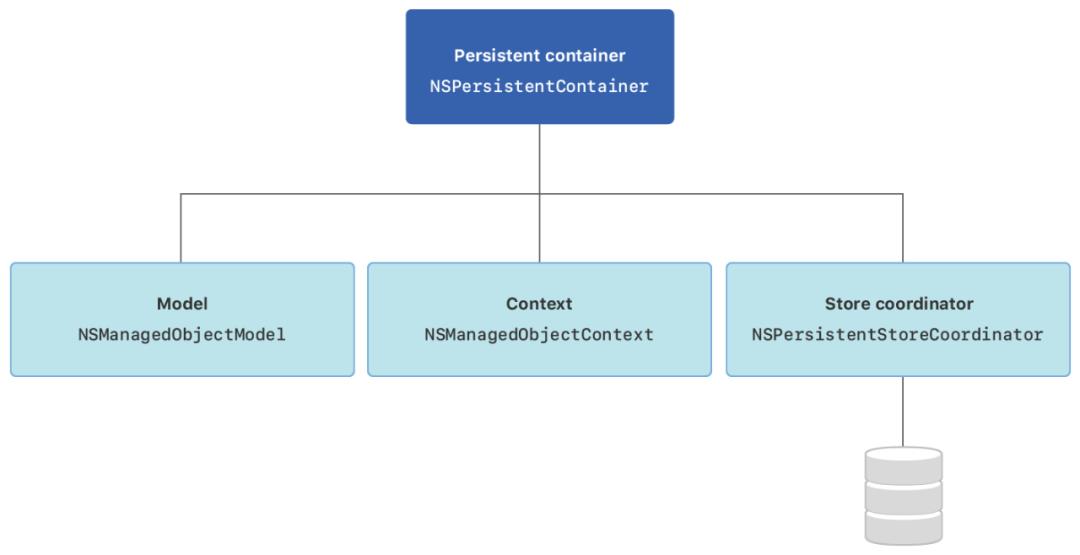
① 主仓库 NSPersistentContainer 说明
- 当配置完 Core Data 的数据类型信息后,并没有产生任何数据,就好比图书馆已经制定了图书的规范:一本书应该有名字、isbm、页数等信息,规范虽然制定,却没有真的引进书进来,那么怎么才能产生和处理数据呢?这就需要通过代码真刀真枪的和 Core Data 打交道了。
- 由于 Core Data 的功能较为强大,必须分成多个类来处理各种逻辑,一次性学习多个类是不容易的,还容易混淆。要和这些各司其职的类打交道,不得不提第一个要介绍的类 NSPersistentContainer,因为它就是存放这多个类成员的“仓库类”。
- 这个 NSPersistentContainer 就是通过代码和 Core Data 打交道的第一个目标,它存放着几种和 Core Data 进行业务处理的工具,当拿到这些工具之后,就可以自由的访问数据,所以它的名字 Container 蕴含着的意思,就是“仓库、容器、集装箱”。
- NSPersistentContainer 和其它成员的关系:
- 进入正式的代码编写的第一步,先要在使用 Core Data 框架的 Swift 文件开头引入这个框架:
import CoreData
② NSPersistentContainer 的初始化
- 在新建的 UIKit 项目中,找到 AppDelegate 类,写一个成员函数(即方法,后面直接用函数这个术语替代):
private func createPersistentContainer() {
let container = NSPersistentContainer(name: "Model")
}
- 这样,NSPersistentContainer 类的建立就完成了,其中 Model 字符串就是建立的 Model.xcdatamodeld 文件,但是输入参数的时候,不需要(也不应该)输入 .xcdatamodeld 后缀。
- 当创建了 NSPersistentContainer 对象时,仅仅完成了基础的初始化,而对于一些性能开销较大的初始化,比如本地持久化资源的加载等,都还没有完成,必须调用 NSPersistentContainer 的成员函数 loadPersistentStores 来完成它。
private func createPersistentContainer() {
let container = NSPersistentContainer(name: "Model")
container.loadPersistentStores { (description, error) in
if let error = error {
fatalError("Error: \\(error)")
}
print("Load stores success")
}
}
- 从代码设计的角度看,为什么 NSPersistentContainer 不直接在构造函数里完成数据库的加载?这就涉及到一个面向对象的开发原则,即构造函数的初始化应该是(原则上)倾向于原子级别,即简单的、低开销内存操作,而对于性能开销大的,内存之外的存储空间处理(比如磁盘,网络),应尽量单独提供成员函数来完成,这样做是为了避免在构造函数中出错时错误难以捕捉的问题。
③ Core Data 表格属性信息的提供者 NSManagedObjectModel
- 现在已经持有并成功初始化了 Core Data 的仓库管理者 NSPersistentContainer,接下去就可以使用向这个管理者索取信息了,我们已经在模型文件里存放了读者和书籍这两个 Entity 了,如何获取这两个 Entity 的信息呢?这就需要用到 NSPersistentContainer 的成员,即 managedObjectModel,该成员就是标题所说的 NSManagedObjectModel 类型。
- 为了了解 NSManagedObjectModel 能提供什么,通过以下函数来提供说明:
private func parseEntities(container: NSPersistentContainer) {
let entities = container.managedObjectModel.entities
print("Entity count = \\(entities.count)\\n")
for entity in entities {
print("Entity: \\(entity.name!)")
for property in entity.properties {
print("Property: \\(property.name)")
}
print("")
}
}
- 为了执行上面这个函数,需要修改 createPersistentContainer,在里面调用 parseEntities:
private func createPersistentContainer() {
let container = NSPersistentContainer(name: "Model")
container.loadPersistentStores { (description, error) in
if let error = error {
fatalError("Error: \\(error)")
}
self.parseEntities(container: container)
}
}
- 在这个函数里,通过 NSPersistentContainer 获得了 NSManagedObjectModel 类型的成员 managedObjectModel,并通过它获得了文件 Model.xcdatamodeld 中配置好的 Entity 信息,即图书和读者。由于配置了两个 Entity 信息,所以运行正确的话,打印出来的第一行是:
Entity count = 2
- container 的成员 managedObjectModel 有一个成员叫 entities,它是一个数组,这个数组成员的类型叫 NSEntityDescription,这个类名是专门用来处理 Entity 相关操作的,这里就没必要多赘述。
- 示例代码里,获得了 entity 数组后,打印 entity 的数量,然后遍历数组,逐个获得 entity 实例,接着遍历 entity 实例的 properties 数组,该数组成员是由类型 NSPropertyDescription 的对象组成。
- 关于名词 Property,在 Core Data 的术语环境下,一个 Entity 由若干信息部分组成,之前已经提过的 Entity 和 Relationship 就是,而这些信息用术语统称为 property。NSPropertyDescription 看名字就能知道,就是处理 property 用的。
Entity count = 2
Entity: Book
Property: isbm
Property: name
Property: page
Property: borrowedBy
Entity: Reader
Property: idCard
Property: name
Property: borrow
- 可以看到,打印出来配置的图书有 4 个 property,最后一个是 borrowedBy,明显这是个 Relationship,而前面三个都是 Attribute,这和刚刚对 property 的说明是一致的。
④ Entity 对应的类
- Core Data 是一个“对象-关系映射”持久化方案,现在在 Model.xcdatamodeld 已经建立了两个 Entity,那么如果在代码里要操作它们,是不是会有对应的类?答案是确实如此,而且还不需要自己去定义这个类。
- 如果点击 Model.xcdatamodeld 编辑窗口中的 Book 这个 Entity,打开右侧的属性面板,属性面板会给出允许编辑的关于这个 Entity 的信息,其中 Entity 部分的 Name 就是命名的 Book,而下方还有一个 Class 栏,这一栏就是跟 Entity 绑定的类信息,栏目中的 Name 就是要定义的类名,默认它和 Entity 的名字相同,也就是说,类名也是 Book,所以改与不改,看个人思路以及团队的规范。
- 所有 Entity 对应的类,都继承自 NSManagedObject。为了检验这一点,可以在代码中编写这一行作为测试:
var book: Book! // 纯测验代码,无业务价值
- 如果写下这一行编译通过了,那说明开发环境已经生成了 Book 这个类,不然它就不可能编译通过。测试结果,完美编译通过,说明不需要自己编写,就可以直接使用这个类。
- 说明:
-
- 关于类名,官方教程里一般会把类名更改为 Entity 名 + MO,比如这个 Entity 名为 Book,那么如果是按照官方教程的做法,可以在面板中编辑 Class 的名字为 BookMO,这里 MO 大概就是 Model Object 的简称。但是这里为简洁起见,就不做任何更改了,Entity 名为 Book,那么类名也一样为 Book。
-
- 另外,也可以自己去定义 Entity 对应的类,这样有个好处是可以给类添加一些额外的功能支持,这部分 Core Data 提供了编写的规范,但是大部分时候这个做法反而会增加代码量,不属于常规操作。
四、数据业务的操作
① 数据操作管理类 NSManagedObjectContext
- 接下来,隆重介绍 NSPersistentContainer 麾下的一名工作任务最繁重的大将,成员 viewContext,接下去和实际数据打交道,处理增删查改这四大操作,都要通过这个成员才能进行。
- viewContext 成员的类型是 NSManagedObjectContext,顾名思义,它的任务就是管理对象的上下文。从创建数据,对修改后数据的保存、删除数据、修改数据,无一不是以它为入口。
- 现在开始,正式从“定义数据”的阶段,正式进入到“产生和操作数据”的阶段。
② 数据的插入
- “数据插入”的调用方法:NSEntityDescription.insertNewObject。
- 先尝试创建一本图书,用一个 createBook 函数来进行,示例代码如下:
private func createBook(container: NSPersistentContainer,
name: String, isbm: String, pageCount: Int) {
let context = container.viewContext
let book = NSEntityDescription.insertNewObject(forEntityName: "Book",
into: context) as! Book
book.name = name
book.isbm = isbm
book.page = Int32(pageCount)
if context.hasChanges {
do {
try context.save()
print("Insert new book(\\(name)) successful.")
} catch {
print("\\(error)")
}
}
}
- 在这个代码里,最值得关注的部分就是 NSEntityDescription 的静态成员函数 insertNewObject,通过这个函数来进行所要插入数据的创建工作。
- insertNewObject 对应的参数 forEntityName 就是要输入的 Entity 名,这个名字当然必须是之前创建好的 Entity 有的名字才行,否则就出错,因为要创建的是书,所以输入的名字就是 Book。
- 而 into 参数就是处理增删查改的大将 NSManagedObjectContext 类型。insertNewObject 返回的类型是 NSManagedObject,如前所述,这是所有 Entity 对应类的父类,因为要创建的 Entity 是 Book,我们已经知道对应的类名是 Book,所以可以放心大胆的把它转换为 Book 类型。接下来就可以对 Book 实例进行成员赋值,可以惊喜的发现 Book 类的成员都是在 Entity 表格中编辑好的,真是方便极了。
- 那么问题来了,当把 Book 编辑完成后,是不是这个数据就完成了持久化了,其实不是的。这里要提一下 Core Data 的设计理念:懒原则,Core Data 框架之下,任何原则操作都是内存级的操作,不会自动同步到磁盘或者其它媒介里,只有开发者主动发出存储命令,才会做出存储操作,这么做自然不是因为真的很懒,而是出于性能考虑。
- 为了真的把数据保存起来,首先通过 context (即 NSManagedObjectContext 成员)的 hasChanges 成员询问是否数据有改动,如果有改动,就执行 context 的 save 函数(该函数是个会抛异常的函数,所以用 do→catch 包裹起来)。至此,添加书本的操作代码就全部写完,接下来把它放到合适的地方运行。
- 对 createPersistentContainer 稍作修改:
private func createPersistentContainer() {
let container = NSPersistentContainer(name: "Model")
container.loadPersistentStores { (description, error) in
if let error = error {
fatalError("Error: \\(error)")
}
//self.parseEntities(container: container)
self.createBook(container: container,
name: "算法(第4版)",
isbm: "9787115293800",
pageCount: 636)
}
}
- 运行项目,会看到如下打印输出:
Insert new book(算法(第4版)) successful.
- 至此,书本的插入工作顺利完成,因为这个示例没有去重判定,如果程序运行两次,那么将会插入两条书名都为“算法(第4版)”的 book 记录。
③ 数据的获取
- 读取的示例代码:
private func readBooks(container: NSPersistentContainer) {
let context = container.viewContext
let fetchBooks = NSFetchRequest<Book>(entityName: "Book")
do {
let books = try context.fetch(fetchBooks)
print("Books count = \\(books.count)")
for book in books {
print("Book name = \\(book.name!)")
}
} catch {
}
}
- 处理数据处理依然是数据操作主力 context,而处理读取请求配置细节则是交给一个专门的类 NSFetchRequest 来完成,因为处理读取数据有各种各样的类型,所以 Core Data 设计了一个泛型模式,只要对 NSFetchRequest 传入对应的类型,比如 Book,它就知道应该传回什么类型的对应数组,其结果是可以通过 Entity 名为 Book 的请求直接拿到 Book 类型的数组,真是很方便。
- 打印结果:
Books count = 1
Book name = 算法(第4版)
④ 数据获取的条件筛选
- 通过 NSFetchRequest 可以获取所有的数据,但是很多时候需要的是获得想要的特定的数据,通过条件筛选功能,可以实现获取出想要的数据,这时候需要用到 NSFetchRequest 的成员 predicate 来完成筛选,如下所示,要找书名叫“算法(第4版)”的书,在代码示例里,在之前实现的 readBooks 函数代码里略作修改:
private func readBooks(container: NSPersistentContainer) {
let context = container.viewContext
let fetchBooks = NSFetchRequest<Book>(entityName: "Book")
fetchBooks.predicate = NSPredicate(format: "name = \\"算法(第4版)\\"")
do {
let books = try context.fetch(fetchBooks)
print("Books count = \\(books.count)")
for book in books {
print("Book name = \\(book.name!)")
}
} catch {
print("\\(error)")
}
}
- 通过代码:
fetchBooks.predicate = NSPredicate(format: "name = \\"算法(第4版)\\"")
- 从书籍中筛选出书名为 算法(第4版) 的书,因为之前已经保存过这本书,所以可以正确筛选出来。筛选方案还支持大小对比,如:
fetchBooks.predicate = NSPredicate(format: "page > 100")
- 这样将筛选出 page 数量大于 100 的书籍。
⑤ 数据的修改
- 当要修改数据时,比如说需要把 isbm = “9787115293800” 这本书的书名修改为“算法(第5版)” ,可以按照如下代码示例:
let context = container.viewContext
let fetchBooks = NSFetchRequest<Book>(entityName: "Book")
fetchBooks.predicate = NSPredicate(format: "isbm = \\"9787115293800\\"")
do {
let books = try context.fetch(fetchBooks)
if !books.isEmpty {
books[0].name = "算法(第5版)"
if context.hasChanges {
try context.save()
print("Update success.")
}
}
} catch {
print("\\(error)")
}
- 上面的例子里,遵循了“读取→修改→保存”的思路,先拿到筛选的书本,然后修改书本的名字,当名字被修改后,context 将会知道数据被修改,这时候判断数据是否被修改(实际上不需要判断便也知道被修改了,只是出于编码规范加入了这个判断),如果被修改,就保存数据,通过这个方式,成功更改了书名。
⑥ 数据的删除
- 数据的删除,依然遵循“读取→修改→保存”的思路,找到想要的思路,并且删除它。删除的方法是通过 context 的 delete 函数。
- 如下所示,删除所有 isbm=“9787115293800” 的书籍:
let context = container.viewContext
let fetchBooks = NSFetchRequest<Book>(entityName: "Book")
fetchBooks.predicate = NSPredicate(format: "isbm = \\"9787115293800\\"")
do {
let books = try context.fetch(fetchBooks)
for book in books {
context.delete(books[0])
}
if context.hasChanges {
try context.save()
}
} catch {
print("\\(error)")
}
以上是关于Swift之深入解析Core Data数据管理的集成指南的主要内容,如果未能解决你的问题,请参考以下文章