并发底层原理之CPU缓存伪共享
Posted Code Mavs
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了并发底层原理之CPU缓存伪共享相关的知识,希望对你有一定的参考价值。
一、什么是CPU缓存
由于CPU 运算速度要比内存读写速度快上超过百倍,使得CPU需要花费很长时间来等待数据读取以及写入。而高速缓存的引入主要就是为了解决 CPU 运算速度与内存读写速度不匹配的矛盾。
在内存金字塔层次结构中,CPU高速缓存位于第二层,仅次于CPU的寄存器。
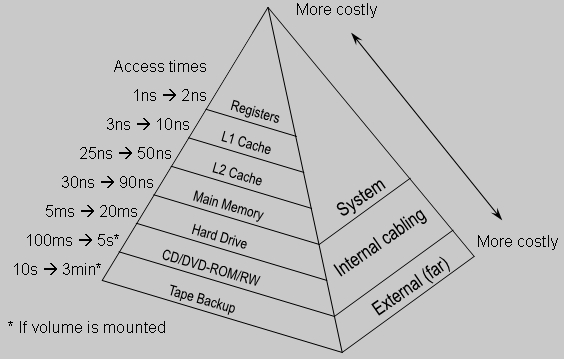
可以比对一下数据从不同存储到CPU大约的传输时间:
- 主存 约60-80ns
- L3 cache 约40-45时钟周期 约15ns
- L2 cache 约10时钟周期 约3ns
- L1 cache 约3-4时钟周期 约1ns
- 寄存器 约1时钟周期
其中 L1、L2、L3都属于CPU的高速缓存,容量依次增大,速度也依次变慢。
L1 和 L2 缓存在每一个CPU核中,L3则是所有CPU核心共享的内存。
此时可能令人疑惑,为什么要设计成这么多层?
原因其实很简单:
- 距离CPU越远,容量越大,理论上速度也越慢,这是物理层面决定的。
- 由于主内存与CPU速度差距实在太大,引入多级的缓存可以提高整体的性能。类似多级缓存的方案在我们如今的大型应用项目开发中也时常会使用到。
按起葫芦浮起瓢,在计算机世界中,经常会看到的一个现象的是:引入新的技术方案,一定就会引入其它的问题(其实不止是计算机世界,现实生活中亦是如此)。 这里引入的两个问题是:
- 缓存的命中率如何保证
- 缓存更新的一致性问题
下面来看看CPU是怎么解决这个问题的?
二、缓存的一致性
如果有一个数据在CPU中的某一个核的缓存上被更新了,那么在其它CPU核上对于该数据的值也要被相应地更新,这就是缓存一致性。
在分布式系统中,我们一般用Paxos/Raft这样的分布式一致性的算法来进行多副本数据一致性的保障。而在CPU的微观世界里,则不必使用这样复杂的算法,原因是CPU多核之间的硬件交互无需考虑网络中断延迟的问题。
所以,CPU的多核心缓存间同步的核心就是要管理好数据的状态即可。
缓存一致性解决方案:
- Snoopy 协议。这种协议更像是一种数据通知的总线型的技术(更准确的说是一种策略)。CPU Cache通过这个协议可以识别其它Cache上的数据状态。如果有数据共享的话,可以通过广播机制将共享数据的状态通知给其它CPU Cache。这个协议要求每个CPU Cache 都可以“窥探”数据事件的通知并做出相应的反应。
- MESI协议, 其主要表示缓存数据有四个状态:Modified(已修改), Exclusive(独占的),Shared(共享的),Invalid(无效的)。
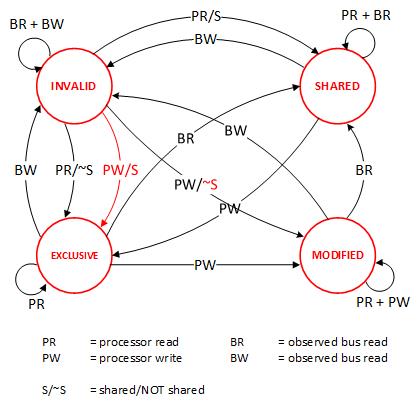
MESI 协议在缓存数据更新后,会标记其它共享的CPU缓存的数据拷贝为Invalid状态,然后当其它CPU再次read的时候,就会出现 cache miss 的问题,此时再从内存中更新数据。
三、伪共享
在谈伪共享问题前,先来看看一个概念——缓存行 。
对于CPU来说,它是不会一个字节一个字节的加载数据的,因为这非常没有效率,一般来说都是要一块一块的加载的,对于这样的一块一块的数据单位,术语叫“Cache Line”,也就是缓存行。
一般来说,一个主流的CPU的Cache Line 是 64 Bytes(也有的CPU用32Bytes和128Bytes),64Bytes也就是16个32位的整型,这就是CPU从内存中捞数据上来的最小数据单位。
缓存系统中是以缓存行(cache line)为单位存储的,当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
在核心1上运行的线程想更新变量X,同时核心2上的线程想要更新变量Y。
不幸的是,这两个变量在同一个缓存行中。每个线程都要去竞争缓存行的所有权来更新变量。
如果核心1获得了所有权,缓存子系统将会使核心2中对应的缓存行失效。
当核心2获得了所有权然后执行更新操作,核心1就要使自己对应的缓存行失效。这会来来回回的经过L3缓存,大大影响了性能。
伪共享解决方式:
- 缓存行填充。显式进行字符填充缓存行。(典型应用:Disruptor高性能队列)
- 使用@sun.misc.Contended注解 (典型应用:jdk8 LongAdder )
在使用此注解的对象或字段的前后各增加128字节大小的padding,使用2倍于大多数硬件缓存行的大小来避免相邻扇区预取导致的伪共享冲突。
伪共享示例一:
package cacheline;
public class FalseShareDemo implements Runnable{
private long ITERATION = 10L * 1000L * 10000L;
private final int arrayIndex;
private static VolatileLong[] longs;
public FalseShareDemo(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
@Override
public void run() {
long i = ITERATION ;
while (0 != i--) {longs[arrayIndex].value = i;}
}
public static void main(String[] args) throws Exception {
longs = new VolatileLong[4];
for (int i = 0; i < longs.length; ++i) {
longs[i] = new VolatileLong();
}
long start = System.currentTimeMillis();
runTest();
System.out.println("填充consume time : " + (System.currentTimeMillis() - start));
}
public static void runTest() throws InterruptedException {
Thread[] threads = new Thread[4];
for (int i = 0; i < threads.length; ++i) {
threads[i] = new Thread(new FalseShareDemo(i));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
}
// @sun.misc.Contended
private final static class VolatileLong {
public volatile long value = 0L;
// public long p1, p2, p3, p4, p5, p6 ;
}
}
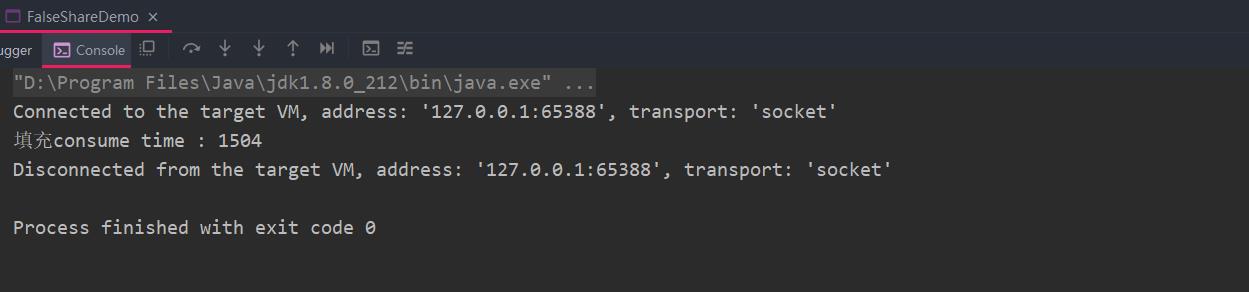
直接运行,耗时:1504ms
示例二:
package cacheline;
public class FalseShareDemo implements Runnable{
private long ITERATION = 10L * 1000L * 10000L;
private final int arrayIndex;
private static VolatileLong[] longs;
public FalseShareDemo(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
@Override
public void run() {
long i = ITERATION ;
while (0 != i--) {longs[arrayIndex].value = i;}
}
public static void main(String[] args) throws Exception {
longs = new VolatileLong[4];
for (int i = 0; i < longs.length; ++i) {
longs[i] = new VolatileLong();
}
long start = System.currentTimeMillis();
runTest();
System.out.println("填充consume time : " + (System.currentTimeMillis() - start));
}
public static void runTest() throws InterruptedException {
Thread[] threads = new Thread[4];
for (int i = 0; i < threads.length; ++i) {
threads[i] = new Thread(new FalseShareDemo(i));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
}
// @sun.misc.Contended
private final static class VolatileLong {
public volatile long value = 0L;
public long p1, p2, p3, p4, p5, p6 ;
}
}

通过第一种方式进行缓存行填充,显式的追加p1-p6六个字符串,运行耗时:456ms
示例三:
package cacheline;
public class FalseShareDemo implements Runnable{
private long ITERATION = 10L * 1000L * 10000L;
private final int arrayIndex;
private static VolatileLong[] longs;
public FalseShareDemo(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
@Override
public void run() {
long i = ITERATION ;
while (0 != i--) {longs[arrayIndex].value = i;}
}
public static void main(String[] args) throws Exception {
longs = new VolatileLong[4];
for (int i = 0; i < longs.length; ++i) {
longs[i] = new VolatileLong();
}
long start = System.currentTimeMillis();
runTest();
System.out.println("填充consume time : " + (System.currentTimeMillis() - start));
}
public static void runTest() throws InterruptedException {
Thread[] threads = new Thread[4];
for (int i = 0; i < threads.length; ++i) {
threads[i] = new Thread(new FalseShareDemo(i));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
}
@sun.misc.Contended
private final static class VolatileLong {
public volatile long value = 0L;
// public long p1, p2, p3, p4, p5, p6 ;
}
}

通过第二种方式使用@sun.misc.Contended注解,运行耗时:432ms
*(需要jvm参数开启-XX:-RestrictContended 选项)
参考文章
https://coolshell.cn/articles/20793.html
https://developer.aliyun.com/article/701276
以上是关于并发底层原理之CPU缓存伪共享的主要内容,如果未能解决你的问题,请参考以下文章