Apache Kylin 的工作流程是什么?
Posted Shockang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache Kylin 的工作流程是什么?相关的知识,希望对你有一定的参考价值。
前言
本文隶属于专栏《1000个问题搞定大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和文献引用请见1000个问题搞定大数据技术体系
正文
Apache Kylin 的工作原理就是对数据模型做 Cube 预计算,并利用计算的结果加速查询。
具体工作过程如下
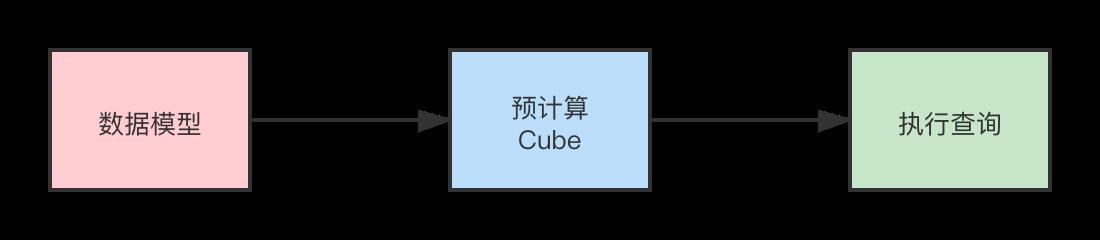
- 指定数据模型,定义维度和度量。
- 预计算 Cube ,计算所有 Cuboid 并保存为物化视图。
- 执行查询时,读取 Cuboid ,运算,产生査询结果。
关于维度和度量请参考我的博客——什么是事实表和维度表?什么是维度和度量?
关于 Cube 和 Cuboid 请参考我的博客——Cube技术是什么?
由于 Kyin 的查询过程不会扫描原始记录,而是通过预计算预先完成表的关联、聚合等复杂运算,并利用预计算的结果来执行査询,因此相比非预计算的查询技术,其速度一般要快一到两个数量级,并且这点在超大的数据集上优势更明显。
当数据集达到千亿乃至万亿级别时, Kylin 的速度甚至可以超越其他非预计算技术 1000 倍以上。
以上是关于Apache Kylin 的工作流程是什么?的主要内容,如果未能解决你的问题,请参考以下文章