大数据——Flink 中的角色及安装部署
Posted Vicky_Tang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据——Flink 中的角色及安装部署相关的知识,希望对你有一定的参考价值。
一、Flink 中的角色
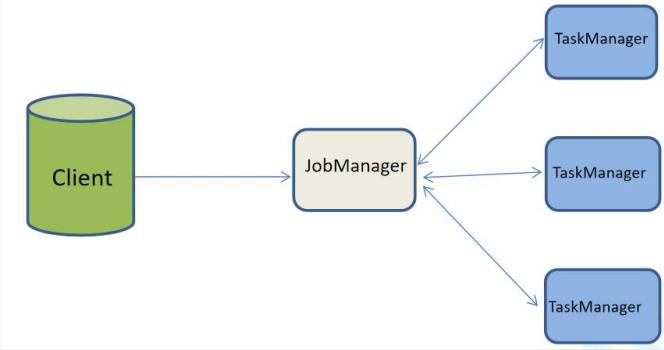
Flink 也遵循主从原则,主节点为JobManager,从节点为TaskManager

1.1. Client
将任务提交到JobManager,并和JobManager进行任务交互获取任务执行状态。
1.2. JobManager
负责任务的调度和资源的管理。负责Checkpoint的协调过程。
获取到客户端的任务后,会根据集群中 TaskManager 上 TaskSlot 的使用情况, 为提交的任务分配相应的 TaskSlots 资源,并命令 TaskManager 启动。 JobManager 在任务执行过程中,会触发 Checkpoints 操作,每个 TaskManager 收到 Checkpoint 指令后,完成 Checkpoint 操作。完成任务后,Flink 会将结果反 馈给客户端,并释放掉 TaskManager 中的资源。
1.3. TaskManager
负责任务的执行。负责对应任务在每个节点上的资源申请与管理。 TaskManager 从 JobManager 接受到任务后,使用 Slot 资源启动 Task,开始接 受并处理数据。
1.4. ResourceManager
ResourceManager 负责 Flink 集群中的资源提供、回收、分配、管理 task slots。 Flink 为不同的环境和资源提供者(例如 YARN、Mesos、Kubernetes 和 standalone 部署)实现了对应的 ResourceManager。在 standalone 设置中,ResourceManager 只能分配可用 TaskManager 的 slots,而不能自行启动新的 TaskManager。
1.5. Dispatcher
Dispatcher 提供了一个 REST 接口,用来提交 Flink 应用程序执行,并为每 个提交的作业启动一个新的 JobMaster。它还运行 Flink WebUI 用来提供作业执 行信息。
1.6. JobMaster
JobMaster 负责管理单个 JobGraph 的执行。Flink 集群中可以同时运行多个 作业,每个作业都有自己的 JobMaster。
二、Flink 的安装部署
2.1 本地模式
在本地以多线程的方式模拟 Flink 中的多个角色。(开发环境不用)
下载地址:https://flink.apache.org/downloads.html
这里选择下载:flink-1.13.0-bin-scala_2.12.tgz
上传到节点上并解压
tar -zxvf flink-1.13.0-bin-scala_2.12.tgz 启动: 切换到 flink 的 bin 目录下,执行./start-cluster.sh,然后查看进程。
./start-cluster.sh2.2 Standalone 独立集群模式
1.上传、解压 tar 包
当前使用的版本是基于 Scala2.12 的 Flink1.13 版本。
tar -zxvf flink-1.13.0-bin-scala_2.12.tgz2.修改配置文件
vi conf/flink-conf.yaml 指定 Flink 集群 JobManager RPC 通信地址。
vi conf/flink-conf.yaml
------------------------------------------
jobmanager.rpc.address: master
------------------------------------------注意:flink-conf.yaml中配置key/value时候在 :后面需要有一个空格,否则配置不会生效。
其他重要配置解释
# jobmanager 和 taskmanager 通信的端口号
jobmanager.rpc.port: 6123
# JobManager 的总进程内存大小
jobmanager.memory.process.size: 1600m
#当前 taskmanager 整个进程占用的内存是多少
taskmanager.memory.process.size: 1728m
#每个 taskmanager 可以提供的 slots
taskmanager.numberOfTaskSlots: 1
#默认的并行度 parallelism.default: 1
#jobmanager 故障转移策略,1.9 之后出现的新属性,区域性恢复策略
jobmanager.execution.failover-strategy: region
#flink web 界面的端口号
rest.port: 8081vi conf/workers 指定 Flink 集群 TaskManager
vi /conf/workers
---------------------------------
master
slave1
slave2
---------------------------------3.分发 Flink 到其他节点
scp -r flink-1.13.0 slave1:$PWD
scp -r flink-1.13.0 slave2:$PWD4. 配置环境变量
vi /etc/profile.d/myenv.sh
----------------------------------------------
export FLINK_HOME=/usr/software/flink-1.13.0
export PATH=$PATH:$FLINK_HOME/bin
----------------------------------------------
source /etc/profile5. 启动集群
在master节点上执行start-cluster.sh
start-cluster.sh
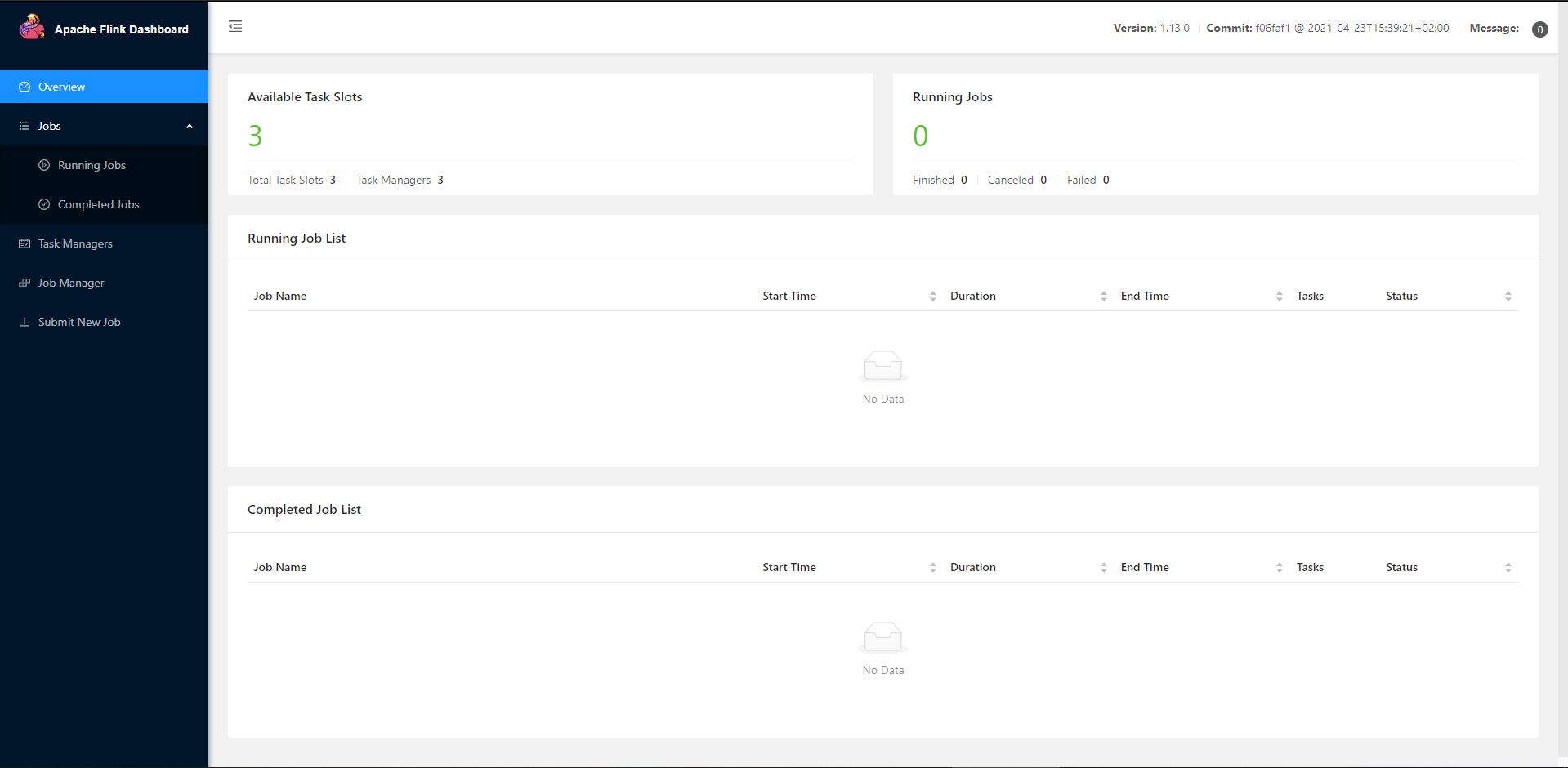
可以通过 master:8081 访问 flink web UI 界面
2.3 Standalone HA
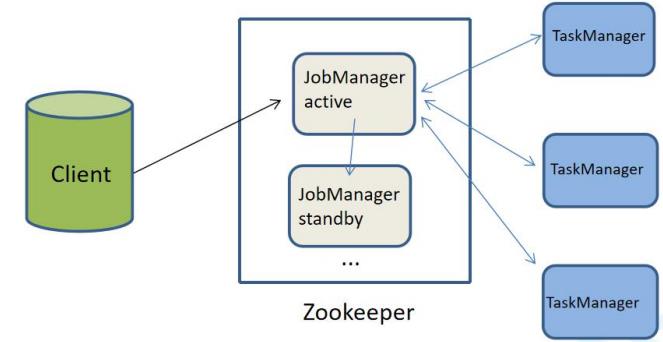
从之前的架构中我们可以发现 JobManager 有明显的单点问题(SPOF,single point of failure)。JobManager 肩负着任务调度以及资源分配,一旦 JobManager 出现意外,其后果可想而知。
我们借助在 Zookeeper 的帮助下,一个 Standalone 的 Flink 集群会同时有多 个活着的 JobManager,其中只有一个处于工作状态,其他处于 Standby 状态。 当工作中的 JobManager 失去连接后(如宕机或 Crash),Zookeeper 会从 Standby 中选一个新的 JobManager 来接管 Flink 集群。
1. 集群规划
master: JobManager + TaskManager
slave1: JobManager + TaskManager
slave2: TaskManager
2. 修改配置文件
vi masters 修改集群 JobManager 节点
vi master
-------------------------
master:8081
slave1:8081
-------------------------vi workers 修改集群 TaskManager节点
vi workers
-------------------------
master
slave1
slave2
-------------------------vi flink-conf.yaml 添加如下配置
vi flink-conf.yaml
--------------------------------------------------------------------------
state.backend: filesystem
state.backend.fs.checkpointdir: hdfs://master:9000/flink-checkpoints
high-availability: zookeeper
high-availability.storageDir: hdfs://master:9000/flink/ha/
high-availability.zookeeper.quorum: master:2181,slave1:2181,slave2:2181
--------------------------------------------------------------------------3. 同步 flink 配置文件目录 conf 到其他两台节点上
scp -r conf slave1:$PWD
scp -r conf slave2:$PWD4.修改 slave1 上的 JobManager 通讯地址
vi flink-conf.yaml
---------------------------------------
jobmanager.rpc.address:slave1
---------------------------------------5. 启动
启动 ZooKeeper
zkServer.sh start启动 HDFS
start-dfs.sh将 flink-shaded-hadoop-2-uber-2.7.5-10.0.jar 拷贝到 flink 的 lib 目录下,三台 节点都拷贝。
启动 Flink
start-cluster.sh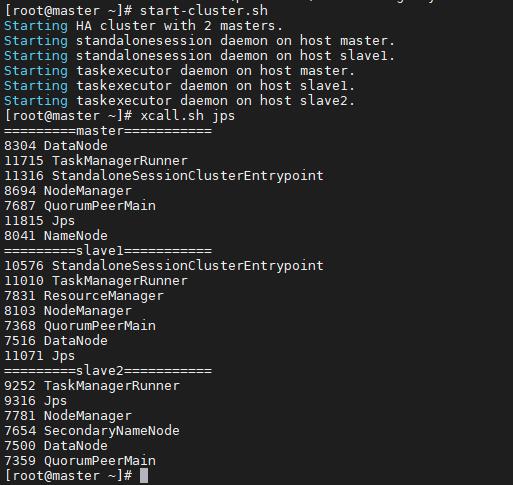
6. 测试
yum -y install nc
nc -lk 1234在新窗口执行如下 jar 包
flink run /usr/software/flink-1.13.0/examples/streaming/SocketWindowWordCount.jar --hostname master --port 12342.4 Flink on yarn(开发重点)
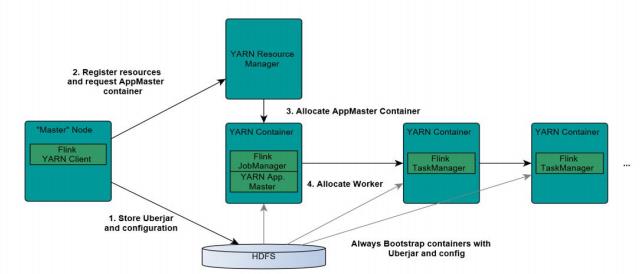
1.flink 与 yarn 的交互
在实际开发中使用 Flink on yarn 模式比较多。
2. 配置
关闭 yarn 的内存检查,yarn-site.xml。并分发给其他节点。
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值, 则直接将其杀掉,默认是 true。在这里面我们需要关闭,因为对于 flink 使用 yarn 模式下,很容易内存超标,这个时候 yarn 会自动杀掉 job。
启动yarn,切换到slave1节点(slave1为ResourceManager部署节点)
start-yarn.sh2.4.1 Session模式
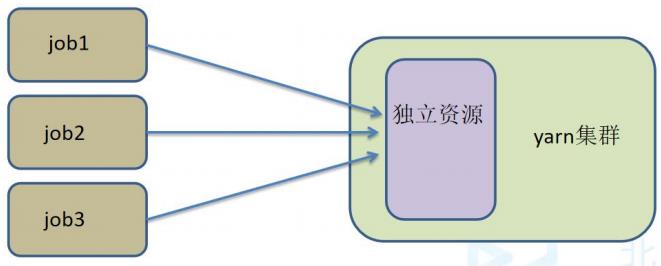
特点:需要事先申请资源,启动 JobManager 和 TaskManger
优点:不需要每次递交作业申请资源,而是使用已经申请好的资源,从而提
高执行效率
缺点:作业执行完成以后,资源不会被释放,因此一直会占用系统资源
应用场景:适合作业递交比较频繁的场景,小作业比较多的场景
yarn-session.sh(开辟资源) + flink run(提交任务)在 yarn 上启动一个 Flink 会话,执行以下命令:
yarn-session.sh -n 2 -tm 800 -s 1 -d
flink run /usr/software/flink-1.13.0/examples/batch/WordCount.jar说明:
# -n 表示申请 2 个容器,这里指的就是多少个 taskmanager
# -tm 表示每个 TaskManager 的内存大小
# -s
表示每个 TaskManager 的 slots 数量
# -d
表示以后台程序方式运行
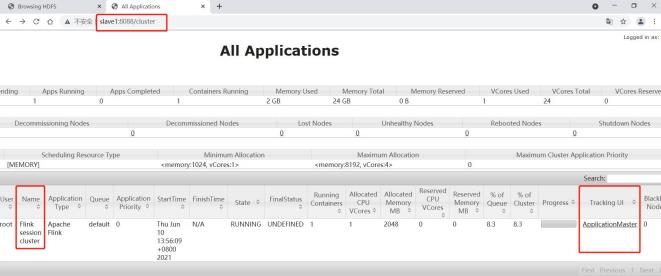
在 yarn 的 8088 界面可以看到 Flink session cluster 正在运行。
关闭 yarn-session:
yarn application -kill application_id2.4.2 Pre-job 模式
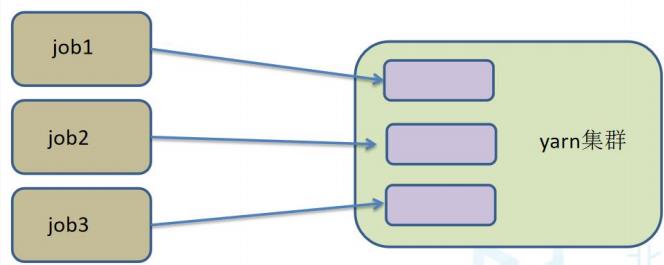
特点:每次递交作业都需要申请一次资源
优点:作业运行完成,资源会立刻被释放,不会一直占用系统资源
缺点:每次递交作业都需要申请资源,会影响执行效率,因为申请资源需要
消耗时间
应用场景:适合作业比较少的场景、大作业的场景
直接提交 job
flink run -m yarn-cluster -yjm 1024 -ytm 1024 /usr/software/flink-1.13.0/examples/batch/WordCount.jar
# -m jobmanager 的地址
# -yjm 1024 指定 jobmanager 的内存信息
# -ytm 1024 指定 taskmanager 的内存信息
2.5 Flink 测试 WordCount
1.安装 netcat。
yum install -y nc
2.开启 nc。
nc -lk 1234
3.统计该端口输入的词频
flink run /usr/software/flink-1.13.0/examples/streaming/SocketWindowWordCount.jar --hostname master --port 1234
4.查看统计的结果。
在 Flink 的 TaskManager 节点的 log 目录下。查看以.out 结尾的文件。

以上是关于大数据——Flink 中的角色及安装部署的主要内容,如果未能解决你的问题,请参考以下文章