一篇文章搞懂 Apache Kylin 4.x 的技术架构
Posted Shockang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一篇文章搞懂 Apache Kylin 4.x 的技术架构相关的知识,希望对你有一定的参考价值。
前言
本文隶属于专栏《1000个问题搞定大数据技术体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和文献引用请见1000个问题搞定大数据技术体系
正文
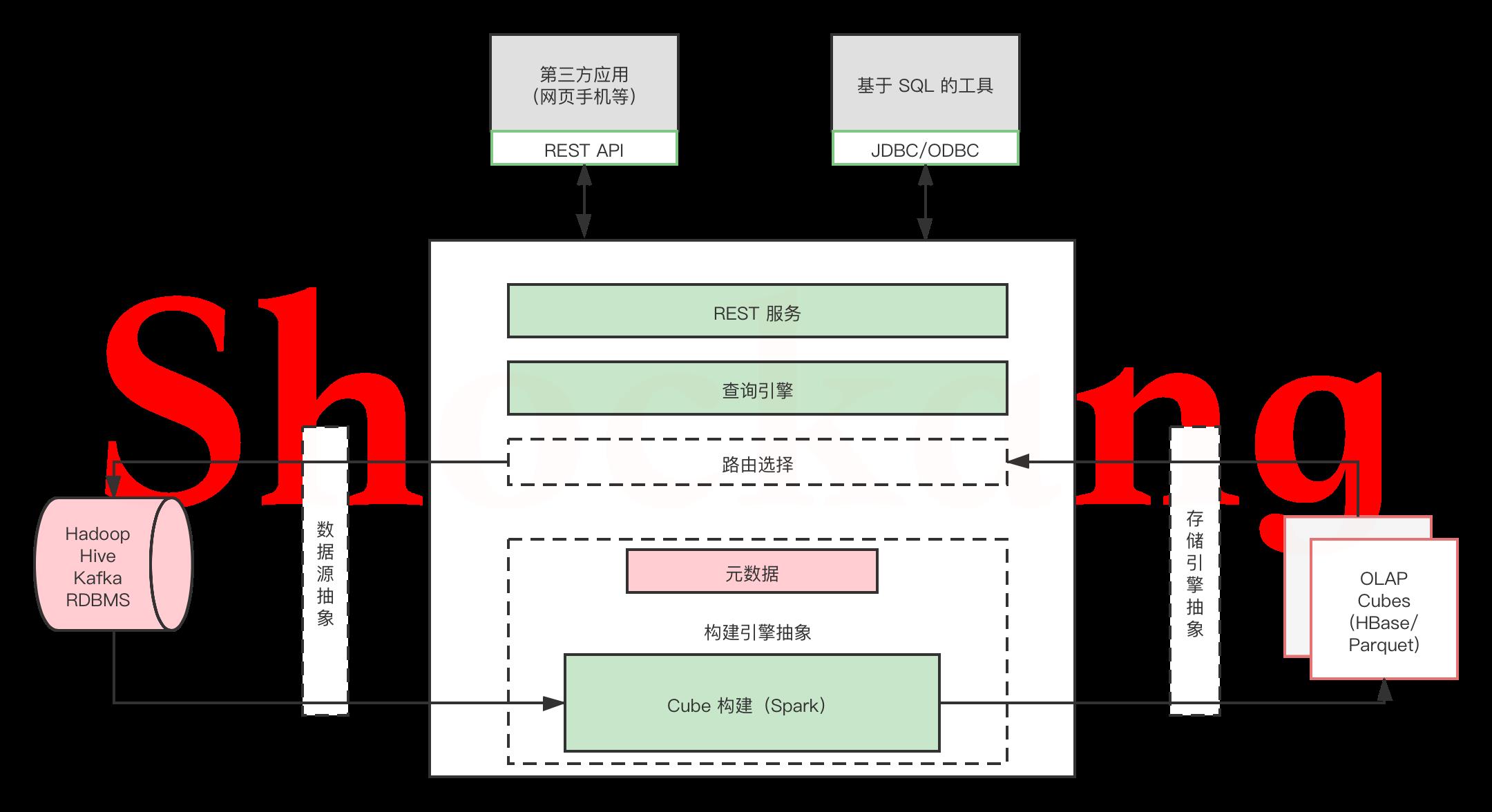
Apache Kylin 系统可以分为在线查询和离线构建两部分,技术架构如图所示,在线査询的模块主要处于上半区,而离线构建则处于下半区。
离线构建
我们首先来看看离线构建的部分。
从图中可以看出,数据源在左侧,主要是 Hadoop/Hive/Kafka/RDBMS ,保存着待分析的用户数据。
根据元数据的定义,下方构建引擎从数据源抽取数据,并构建 Cube 。
数据以关系表的形式输入,且必须符合星形模型( Star Schema )。
Map Reduce 和 Spark 是主要的构建技术,Kylin 4.0 版本中Spark Engine 是唯一的构建引擎。
构建后的 Cube 保存在右侧的存储引擎中,选用 Parquet 作为存储。
在 3.x 以及之前的版本中,kylin 一直使用 HBase 作为存储引擎来保存 cube 构建后产生的预计算结果。HBase 作为 HDFS 之上面向列族的数据库,查询表现已经算是比较优秀,但是它仍然存在以下几个缺点:
- HBase 不是真正的列式存储;
- HBase 没有二级索引,Rowkey 是它唯一的索引;
- HBase 没有对存储的数据进行编码,kylin 必须自己进行对数据编码的过程;
- HBase 不适合云上部署和自动伸缩;
- HBase 不同版本之间的 API 版本不同,存在兼容性问题(比如,0.98,1.0,1.1,2.0);
- HBase 存在不同的供应商版本,他们之间有兼容性问题。
针对以上问题,社区提出了对使用 Apache Parquet + Spark 来代替 HBase 的提议,理由如下:
- Parquet 是一种开源并且已经成熟稳定的列式存储格式;
- Parquet 对云更加友好,可以兼容各种文件系统,包括 HDFS、S3、Azure Blob store、Ali OSS 等;
- Parquet 可以很好地与 Hadoop、Hive、Spark、Impala 等集成;
- Parquet 支持自定义索引。
在线查询
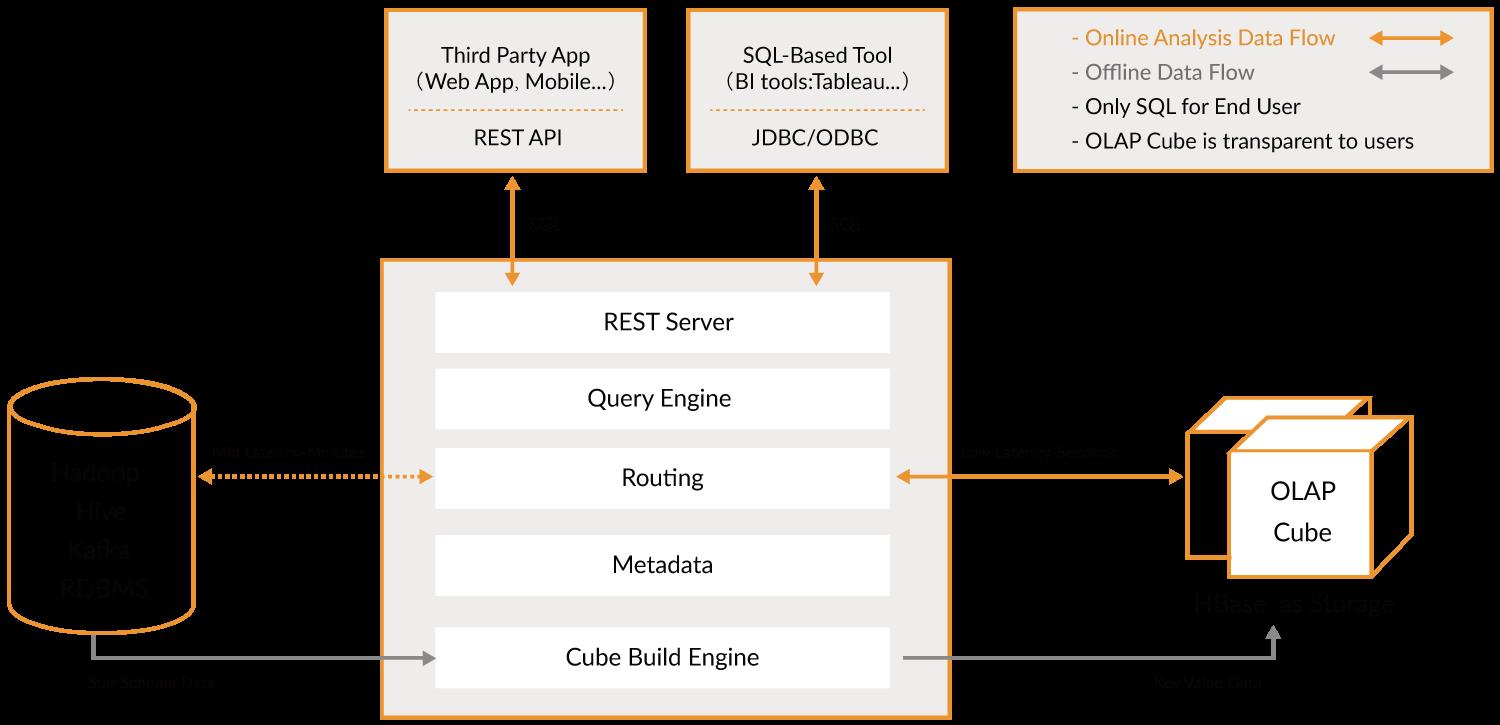
完成了离线构建之后,用户可以从上方查询系统发送 SQL 进行査询分析。
Kyin 提供了各种 RestAPI 、 JDBC / ODBC 接口。
无论从哪个接口进入, SQL 最终都会来到 Rest 服务层,再转交给查询引擎进行处理。
这里需要注意的是, SQL 语句是基于数据源的关系模型书写的,而不是 Cube 。
Kylin 在设计时刻意对査询用户屏蔽了 Cube 的概念,分析师只需要理解简单的关系模型就可以使用 Kylin ,没有额外的学习门槛,传统的 SQL 应用也很容易迁移。
查询引擎解析 SQL ,生成基于关系表的逻辑执行计划,然后将其转译为基于 Cube 的物理执行计划,最后查询预计算生成的 Cube 并产生结果。
整个过程不会访问原始数据源。
Apache Kylin 1.5 版本的可扩展架构
Apache Kylin 1.5 版本引入了“可扩展架构”的概念。
可扩展指 Kylin 可以对其主要依赖的三个模块做任意的扩展和替换。
Kylin 的三大依赖模块分别是数据源、构建引擎和存储引擎。
在设计之初,作为 Hadoop 家族的一员,这三者分别是 Hive 、 MapReduce 和 HBase 。
但随着推广和使用的深入,渐渐有用户发现它们均存在不足之处。
比如,实时分析可能会希望从 Kafka 导入数据而不是从 Hive,而 Spark 的迅速崛起,又使我们不得不考虑将 MapReduce 替换为 Spark ,以期大幅提高 Cube 的构建速度,至于 HBase ,它的读性能可能还不如 Cassandra 或 Kudu 等。
可见,是否可以将一种技术替换为另一种技术已成为一个常见的问题。
于是 Kylin 1.5 版本的系统架构进行了重构,将数据源、构建引擎、存储引擎三大依赖抽象为接口。
深度用户可以根据自己的需要做二次开发,将其中的一个或多个替换为更适合的技术。
以上是关于一篇文章搞懂 Apache Kylin 4.x 的技术架构的主要内容,如果未能解决你的问题,请参考以下文章