Elasticsearch bucket_scriptbucket_selectorbucket_sort 区别和应用场景?
Posted 铭毅天下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch bucket_scriptbucket_selectorbucket_sort 区别和应用场景?相关的知识,希望对你有一定的参考价值。
1、实战问题
POST test-002/_bulk
"index":"_id":1
"name": "张三","city": "beijing"
"index":"_id":2
"name": "李四","city": "beijing"
"index":"_id":3
"name": "王五","city": "shanghai"
"index":"_id":4
"name": "赵六","city": "shanghai"请教老师, 上面的是我在es保存的数据, 想写一个dsl, 求出来 beijing 占比 50%, shanghai 占比 50%。
死磕Elasticsearch知识星球 https://t.zsxq.com/0bqpcJiLL
2、问题分析
类似问题,样例数据单看计算不复杂,“beijing” 2 个,“上海” 2 个,“beijing”占比: 2/(2+2) = 50%; "shanghai"同样计算,占比 50%。
业务层面,建议获取到分桶聚合结果后,直接代码求解百分比效率更高。
仅就上面数据解释如下,两个步骤搞定。
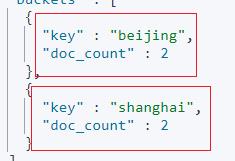
第一步:基于city 字段分桶聚合。
POST test-002/_search
"size": 0,
"aggs":
"city_aggs":
"terms":
"field": "city",
"size": 10
获取结果如下截图所示。
第二步:业务代码层面(python或Java或其他),直接来个除法搞定。
如上,才是效率最高的方案,尤其数据量巨大的业务场景。
问题来了,我就想让 Elasticsearch 搞定计算,怎么办?
我们需要在刚才分桶聚合的基础上,获取桶内“beijing”、“shanghai”的值,然后做除法。
这里的除法本质会用到 Elasticsearch Pipeline 子聚合 bucket_script 的概念。
讲到这里,有必要再把聚合梳理一遍。
3、聚合详解
3.1 聚合全局认知
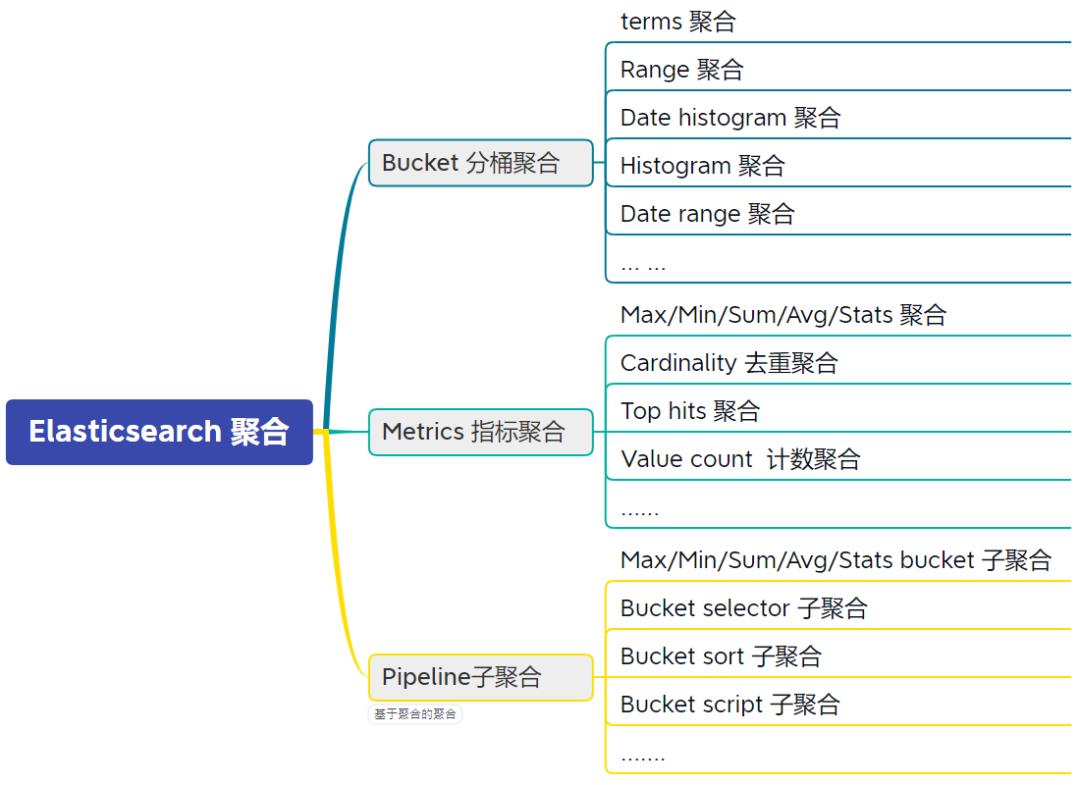
聚合分类
核心分为三大类:
(1)Bucket 分桶聚合
通俗举例:开篇示例,按照“city”分桶,“beijing”一桶、“shanghai”一桶。
协议分桶聚合饼图
时间走势聚合示意图
(2)Metrics 指标聚合
通俗举例:求一组数据中的最大值;求一组数的平均值。
(3)Pipeline子聚合(基于聚合的聚合)
通俗举例:以B站视频为例,首先按年度统计每年最大观看量视频,然后再统计观看量最大视频所在的年份(基于聚合再聚合)。
如果基础概念还有点模糊,推荐阅读:基于儿童积木玩具图解 Elasticsearch 聚合。
3.2 Pipeline子聚合全局认知
子聚合核心又可以分为两类:
parent 子聚合
sibling 子聚合
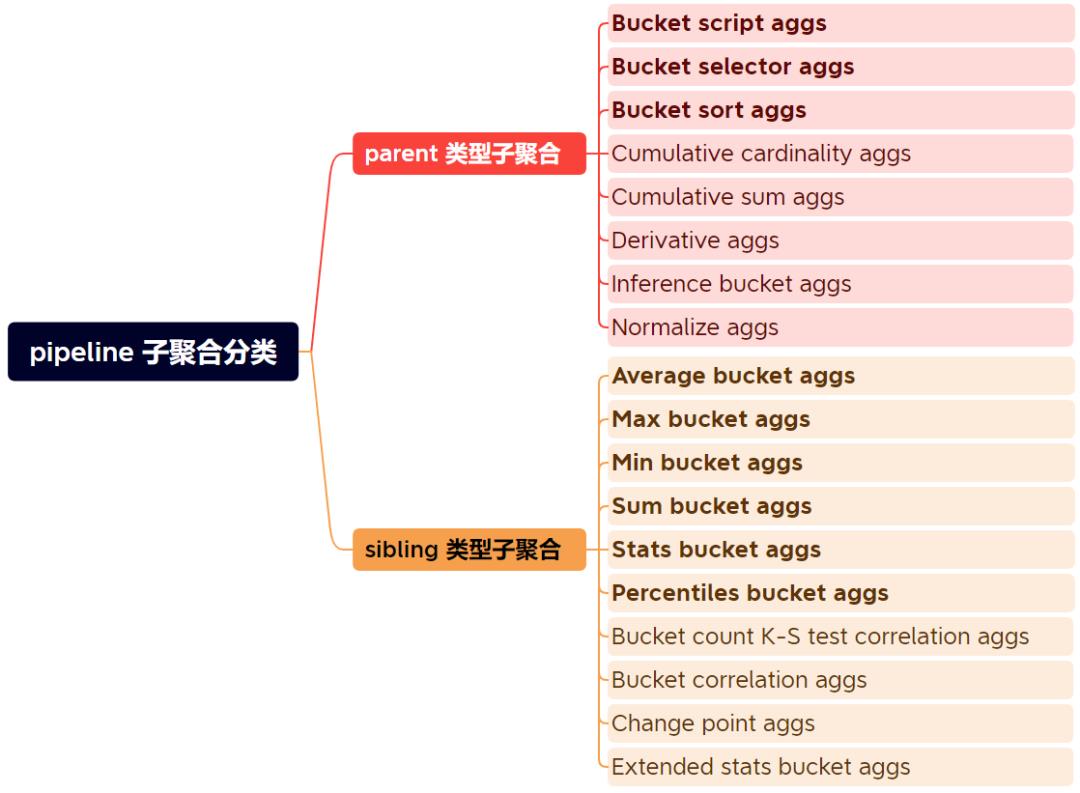 子聚合分类
子聚合分类
分类的依据更通俗讲是语法规则的不同。
4、Pipeline子聚合详解
为了更清楚的说明两者的不同,重构了样例数据如下。
####重构后的样例数据
DELETE test-002
PUT test-002
"mappings":
"properties":
"sale_data":
"type": "date",
"format": "yyyy-MM-dd"
,
"sale_count":
"type": "long"
,
"name":
"type": "keyword"
,
"city":
"type": "keyword"
POST test-002/_bulk
"index":"_id":1
"name":"张三","city":"beijing","sale_date":"2023-01-08","sale_count":100
"index":"_id":2
"name":"李四","city":"beijing","sale_date":"2023-01-18","sale_count":5000
"index":"_id":3
"name":"王五","city":"shanghai","sale_date":"2022-11-08","sale_count":300
"index":"_id":4
"name":"赵六","city":"shanghai","sale_date":"2022-12-28","sale_count":10004.1 sibling 子聚合举例
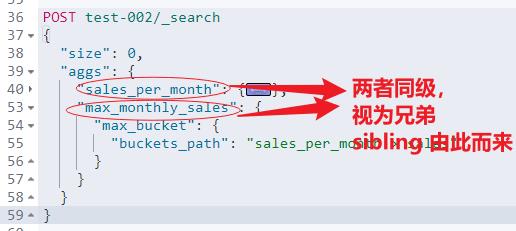
需求描述:按照月份统计每个月的总销量,并获取月总销量最大的月份?
需求拆解:
(1)按照月份统计:使用 bucket 分桶聚合的date_histogram时间走势直方图聚合实现。
(2)每个月的总销量:在按照月份统计的基础上进行嵌套聚合,借助Metric指标聚合的sum实现。
(3)获取月总销量最大的月份:使用 Pipeline 子聚合的 Max_bucket 实现。
最终实现:
POST test-002/_search
"size": 0,
"aggs":
"sales_per_month":
"date_histogram":
"field": "sale_date",
"calendar_interval": "month"
,
"aggs":
"sales":
"sum":
"field": "sale_count"
,
"max_monthly_sales":
"max_bucket":
"buckets_path": "sales_per_month > sales"
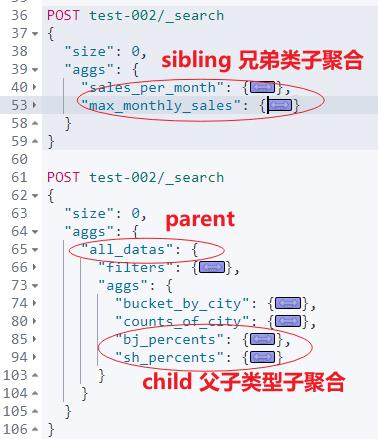
4.2 parent 子聚合举例
需求描述:文章开头,求“beijing”、“shanghai”的各占百分比 ?
需求拆解:
(1)按照 city 分桶:获取“beijing”、“shanghai”的 bucket 分桶聚合结果。
(2)计算百分比:借助 “bucket_script” 脚本子聚合实现。
这里实现层面不简单是上面的两步就可以完成。
核心原因在于:bucket_script 是 “parent”类型的子聚合,进一步说,它需要嵌套在外层聚合的里面,外层聚合就相当于它的“parent”,新加的子聚合相当于“child”。
外层怎么加,这个类似咱们之前的实现:图解:Elasticsearch 8.X 如何求解环比上升比例?
需要借助 filters 过滤聚合整出一个全量数据集,然后在此基础上统计分桶、桶内数据量,并借助 bucket_script 实现百分比。
具体实现如下:
POST test-002/_search
"size": 0,
"aggs":
"all_datas":
"filters":
"filters":
"all_dates_no_process":
"match_all":
,
"aggs":
"bucket_by_city":
"terms":
"field": "city",
"size": 10
,
"counts_of_city":
"value_count":
"field": "city"
,
"bj_percents":
"bucket_script":
"buckets_path":
"bj_count": "bucket_by_city['beijing']>_count",
"all_counts": "counts_of_city"
,
"script": "params.bj_count / params.all_counts"
,
"sh_percents":
"bucket_script":
"buckets_path":
"sh_count": "bucket_by_city['shanghai']>_count",
"all_counts": "counts_of_city"
,
"script": "params.sh_count / params.all_counts"
不常用参数:bucket_by_city['beijing']>_count 含义如下:
获取“beijing”桶下的count计数结果。
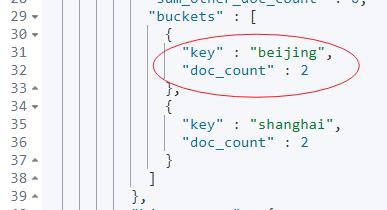
折叠图如下图所示,parent 类别的含义由此而来。

最终百分比结果如下:

至此,开篇问题求解完毕。
5、bucket_script、bucket_selector、bucket_sort 的定义和应用场景?
Bucket selector选择子聚合:对聚合的结果执行进一步的筛选和运算。
Bucket script 脚本子聚合:在聚合的结果上执行脚本运算,以生成新的聚合结果。
Bucket sort 排序子聚合:用聚合结果的任意字段进行排序,并返回一个排序后的桶列表。
这三类都属于 parent 类型的子聚合。子聚合的核心是对前置聚合结果的二次聚合,所以,只有业务需求有对聚合结果再聚合的场景才考虑子聚合。
bucket_script 是一种特殊的子聚合功能,它允许我们在聚合的桶中执行脚本。
应用举例:可以使用脚本来计算每个桶的平均值、百分比(如本文示例)、环比及标准差等。
bucket_selector 是一种特殊的子聚合功能,它允许我们选择某些桶并对其进行子聚合。
应用举例:可以使用选择器选择某些桶并统计它们的总和。
bucket_sort 是一种排序功能,它允许我们按指定顺序对桶进行排序。
应用举例:可以按照每个桶的计数进行排序,以便查看最频繁的项目。
在实际应用场景中,可以根据需要选择使用上述功能中的一个或多个。
应用举例:可以对某个字段的值进行分组,然后使用 bucket_sort 对分组后的桶进行排序,并使用bucket_script在桶中执行脚本,最后使用bucket_selector选择某些桶并对其进行聚合。
这样,我们可以对业务数据进行多层次的分析和统计功能。
6、小结
由百分比的问题引申出聚合分类,由聚合分类引申出Pipeline 子聚合的两个子类型:parent、sibling(兄弟)的区别,更进一步引申出bucket_script、bucket_selector、bucket_sort的定义和应用场景。为后续类似问题提供参考。
推荐视频解读:
参考
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations.html
推荐阅读

更短时间更快习得更多干货!
和全球 1800+ Elastic 爱好者一起精进!

比同事抢先一步学习进阶干货!
以上是关于Elasticsearch bucket_scriptbucket_selectorbucket_sort 区别和应用场景?的主要内容,如果未能解决你的问题,请参考以下文章