从零到一学爬虫
Posted 馋学习的身子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从零到一学爬虫相关的知识,希望对你有一定的参考价值。
爬虫是什么?
爬虫是使用编程语言所编写的一个用于爬取web或app数据的应用程序。
浏览器工作原理
关于Http协议
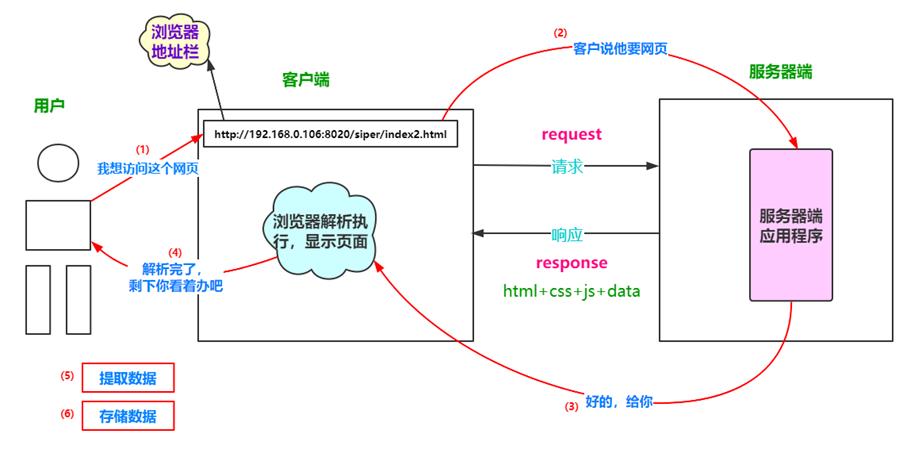
客户端和服务端进行数据交互时绝大部分采用的是HTTP协议,HTTP协议是基于TCP/IP通信协议来传递数据的(html 文件, 图片文件, 查询结果等),TCP/IP协议是面向连接,可以保证数据的完整性,关于其三次握手建立连接与四次挥手断开连接的内容具体可以参考这篇博客:https://blog.csdn.net/iss_cream/article/details/109908287,介绍的非常详细。
HTTP是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide
Web )服务器传输超文本到本地浏览器的传送协议。
浏览器发送http请求的过程:
1.域名解析
2.发起TCP的3次握手
3.建立TCP连接后发起http请求
4.服务器响应http请求,浏览器得到html代码
5.浏览器解析html代码,并请求html代码中的资源(如js、css、图片等)
6.浏览器对页面进行渲染呈现给用户.
http请求的格式
客户端发送一个HTTP请求到服务器的请求消息包括以下部分:请求行,请求头,空行和请求数据。
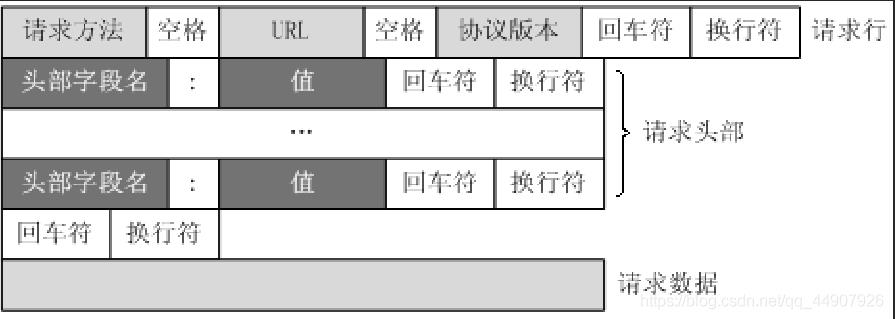
1.请求行:
常用的请求方法为post和get:
-
GET
1.主要是负责从服务器获取数据
2.URL中添加请求参数,显示在地址栏
3.请求字符串限制 1024个字节
比POST更加高效和方便。 -
POST
1.主要负责向服务器提交数据
2.没有大小限制(但一般是2M)
比’GET’传递数据量大,安全性高。
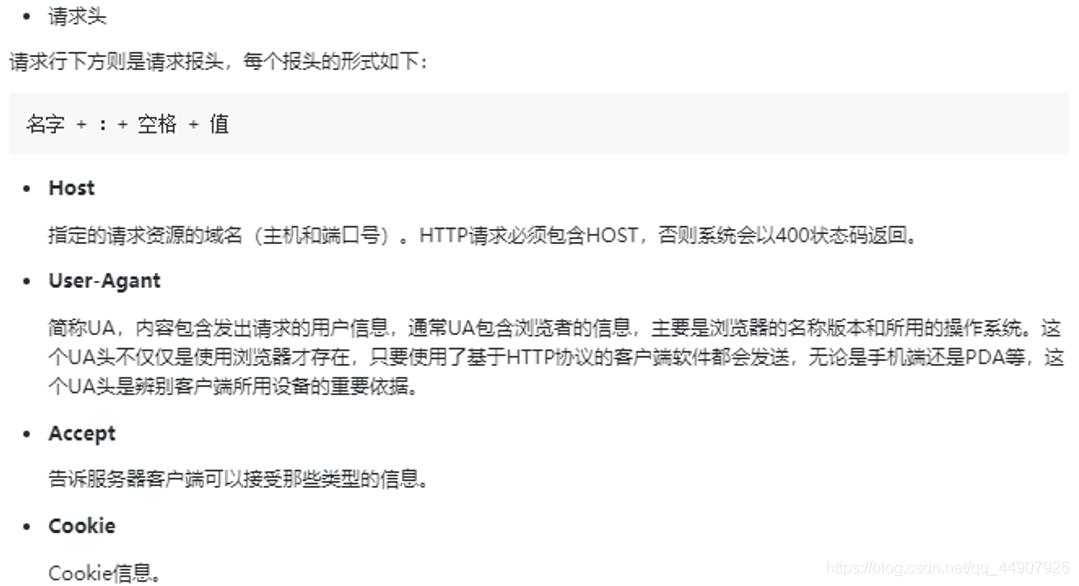
2.请求头
下图是我打开百度的请求头信息:
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cache-Control: max-age=0
Connection: keep-alive
Cookie: BIH_WISE_SIDS=110085_127969_128698_164869_168389_174662_175609_175755_176158_176554_176590_176677_177085_177316_177371_177409_177480_177563_177566_177632_177727_177749_177786_177950_178076_178118_178121_178328_178381_178384_178415_178494_178602_178703_178796_178817_178852_178896_178924_178946_178993_179200_179280_179318_179324_179349_179466_179575_179645_179974_180075_8000080_8000130_8000141_8000149_8000162_8000167_8000177_8000176; BDSFRCVID=ITuOJeC62wratQceTwKmEXdT8ebRG9TTH6aooNxA9Hus9AJdQT05EG0P-M8g0KuMEVMXogKK0mOTHv-BDRCVFR[CLK3Lyfkr9D]=mk3SLVN4HKm; COOKIE_SESSION=42897_1_7_8_4_7_1_0_7_4_0_0_732_0_0_0_1625841671_1625750311_1625884545%7C9%23355686_235_1625750229%7C9; H_PS_645EC=2f337Wjsc9UtMnLtXTHPOoq9fvq159chvowR8JkXTNyvvwc6d1Z3Nt6FyFRLv621wLIY; ZD_ENTRY=baidu; ab_sr=1.0.1_YWZhYjQ1MjZhNTFmYjI3ODliZWM4NTU0Zjg0NGEwOGEzYWU1N2FlMzdkM2ZjZDY0MDk2MDUzODhkMzFiNWVlOTAyNWIxMjVjZmE4NWQxYjM1MWFlZTk3MTJlYTkwNDFmMmE3NWU3ZDMyNzdlM2VmYWY0ZTJlYmI3ZWZjMmQ5ODc3ZDkwNzAxYzk3ZTcxMDRiYzU2ZWU0OGY5NjdkNzI0ZmQ3ZWNhZDYxMWExMDZkYjU2ZTJlZWM4NjU1NWVlYTQx; sug=3; sugstore=0; ORIGIN=2; bdime=0; BA_HECTOR=0k2585a12k0g248huo1gei6440q
Host: www.baidu.com
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"
sec-ch-ua-mobile: ?1
Sec-Fetch-Dest: document
Sec-Fetch-Mode: navigate
Sec-Fetch-Site: none
Sec-Fetch-User: ?1
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Linux; android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Mobile Safari/537.36
其中各个报头的内容如下:


3.请求正文
请求正文通常是使用POST方法进行发送的数据,GET方法是没有请求正文的。请求正文跟上面的消息报头由一个空行隔开。
http响应的格式
HTTP响应也由四个部分组成,分别是:状态行(响应行)、消息报头、空行和响应正文
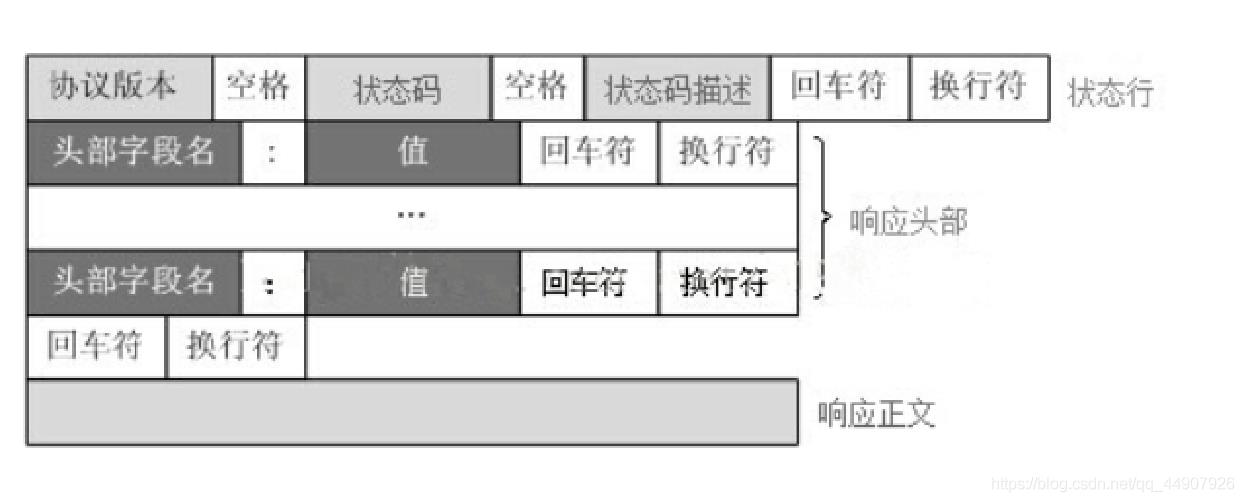
1.常见的响应状态码
| 状态码 | 描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
2.响应报头

下图是打开百度时的响应报头的内容:
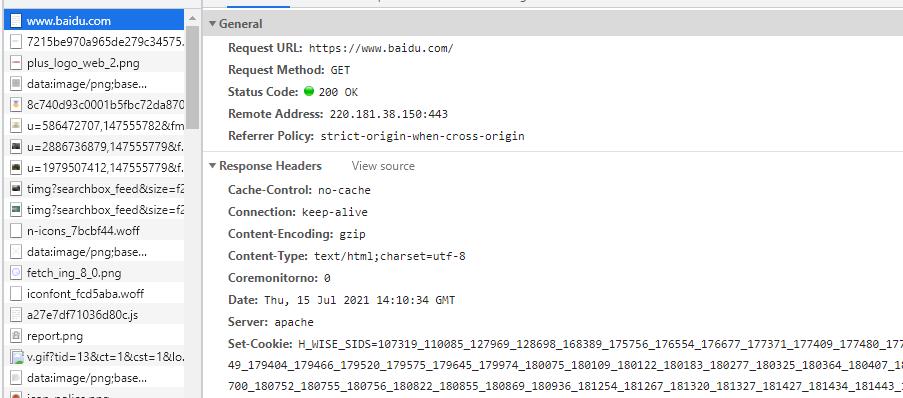
全部的响应报头的内容如下:
Cache-Control: no-cache
Connection: keep-alive
Content-Encoding: gzip
Content-Type: text/html;charset=utf-8
Coremonitorno: 0
Date: Thu, 15 Jul 2021 14:10:34 GMT
Server: apache
Set-Cookie: H_WISE_SIDS=107319_110085_127969_128698_168389_175756_176554_176677_177371_177409_177480_177950_178328_178494_178602_178817_178852_179200_179349_179404_179466_179520_179575_179645_179974_7_8000177_8000176; path=/; expires=Fri, 15-Jul-22 14:10:33 GMT; domain=.baidu.com
Set-Cookie: bd_traffictrace=152210; expires=Thu, 08-Jan-1970 00:00:00 GMT
Set-Cookie: rsv_i=e9a7ma5IAMs0EsZDVlAORBuEE48A4Aqq%2B44F3towLaXFxP9zj1HkgdkittQgfglJA%2BrLSFxYU; path=/; domain=.baidu.com
Set-Cookie: BDSVRTM=583; path=/
Set-Cookie: eqid=deleted; path=/; domain=.baidu.com; expires=Thu, 01 Jan 1970 00:00:00 GMT
Set-Cookie: BDUSS_BFESS=DlEUXNsM2R4U2FMWAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA8IrmAPCK5gS; Path=/; Domain=baidu.com; Expires=Sun, 13 Jul 2031 14:10:34 GMT; Max-Age=315360000; HttpOnly; Secure; SameSite=None
Set-Cookie: BCLID_BFESS=8753206949358273838; Path=/; Domain=baidu.com; Expires=Sun, 13 Jul 2031 14:10:34 GMT; Max-Age=315360000; HttpOnly; Secure; SameSite=None
Set-Cookie: BDSFRCVID_BFESS=N44OJeC62xT867jjg8UtVJeC6EG0Ptf8g0f5; Path=/; Domain=baidu.com; Expires=Sun, 13 Jul 2031 14:10:34 GMT; Max-Age=315360000; HttpOnly; Secure; SameSite=None
Set-Cookie: H_BDCLCKIDbRM2MbgylRp8P3y0bb2DUA1y4vpKMP8bmTxoUJ2XMKVDq5mqfCWMR-ebPRiJPr9QgbqslQ7tt5W8ncFbT7l5hKpbt-q0x-jLTnhVn0MBCK0hI0ljj82e5PVKgTa54cbb4o2WbCQ5hPV8pcN2b5oQT84hxRyKx6KbgO4hnbmfn5vOIJTXpOUWfAkXpJvQnJjt2JxaqQ5rtKRTffjrnhPF3eMu3XP6-hnjy3bRkWJvO5lrHfbRHW-Oxe-LUyN3MWh3RymJ42-39LPO2hpRjyxv4bUn-5toxJpOJXaILWl52HlFWj43vbURvD-ug3-7qex5dtjTO2bc_5KnlfMQ_bf--QfbQ0hOhqP-jBRIEoK0hJC-2bKvPKITD-tFO5eT22-us2D3l2hcHMPoosIJXh4RobfC_5h54XP3nfITiaKJjBMbUoqRHXnJi0btQDPvxBf7p5208Ll5TtUJM_UKzhfoMqfTbMlJyKMnitIj9-pnKHlQrh459XP68bTkA5bjZKxtq3mkjbPbDfn028DKuDj-WDj3XjNR-etjK2CntsJOOaCvFMKbOy4oTj6Db3aAqt55-BJnO-p595UbUhCjsQq383MvB-fnu055CKjvvLPoaBnOoEJ5lQft20htIeMtjBbLLLbuL2n7jWhk2Dq72ybDVQlRX5q79atTMfNTJ-qcH0KQpsIJM5-DWbT8EjH62btt_tJADVx5; Path=/; Domain=baidu.com; Expires=Sun, 13 Jul 2031 14:10:34 GMT; Max-Age=315360000; HttpOnly; Secure; SameSite=None
Set-Cookie: __bsi=; max-age=3600; domain=m.baidu.com; path=/
Strict-Transport-Security: max-age=172800
Traceid: 1621685868544499838800941089
Transfer-Encoding: chunked
Vary: Accept-Encoding
关于HTML
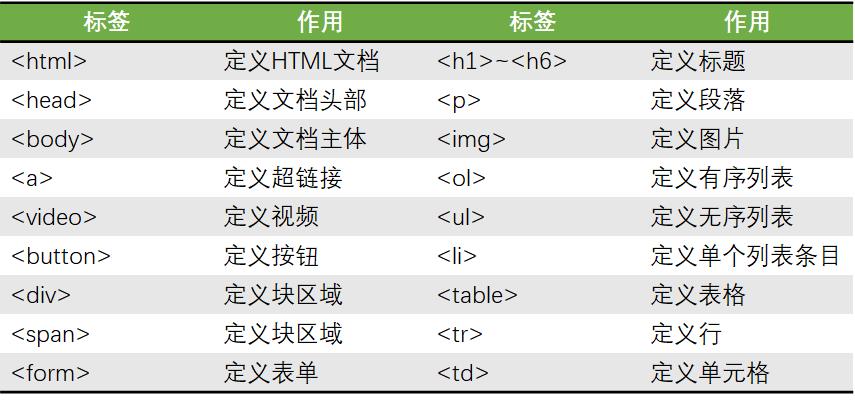
HTTP协议传输的超文本,超文本英文全称是Hyper Text Markup Language,也叫超文本标记语言,即HTML,其文档结构如下:

关于HTML常用标签如下:
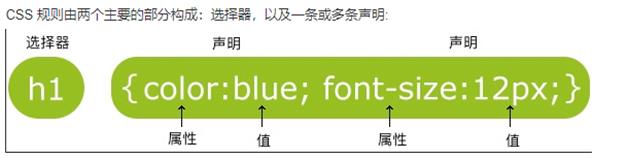
CSS
- 指层叠样式表 (Cascading Style Sheets)
- 使单纯的HTML页面变得美观
CSS样式
- 标签样式
- 类样式
- ID样式
爬虫的工作原理
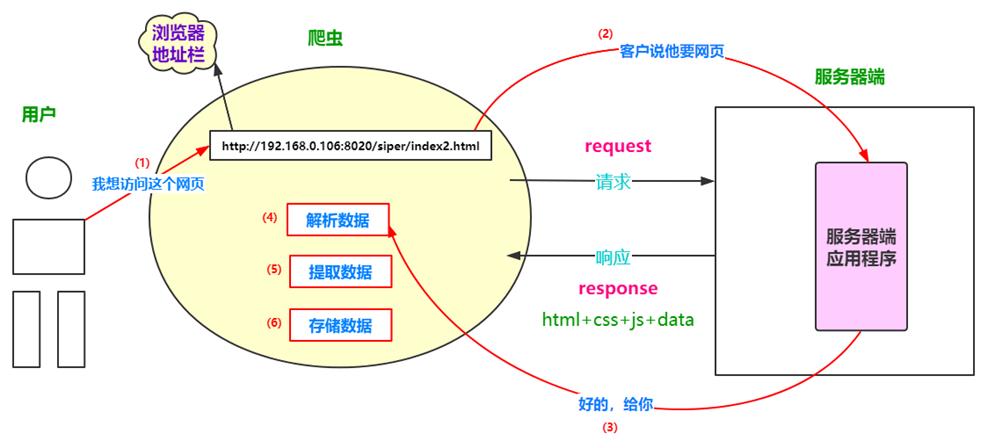
可以看出来爬虫实际上做的事情:模拟客户端向服务器端发送请求、接收服务器发送的响应、解析响应数据并对其进行存储。
简单一句话:网络爬虫是伪装成客户端与服务端进行数据交互的程序。
发送请求
有了上面内容的了解,下面步入正题,首先是模拟客户端向服务器发送请求:
利用第三方模块requests
- 安装方式: pip install requests
- 作用 : 向服务器发送请求获取响应结果(模拟浏览器)
- 用于发送请求的方法get() (相当于浏览器的地址栏)
requests.get(url)
响应结果为response对象
- 常见的响应状态码
- 200成功
- 403禁止访问
- 404找不到页面
- 500服务器内部代码错误
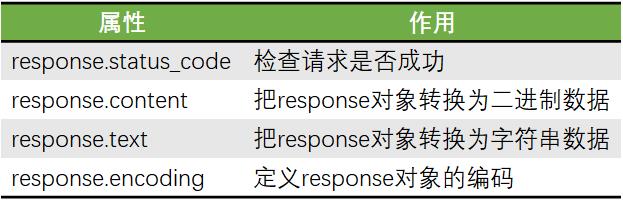
解析响应数据
BeautifulSoup,利用第三方模块bs4,通过pip install bs4进行安装
- 解析和提取数据的网页解析器
- 非Python标准模块,通过pip install bs4进行安装
- 使用语法:
bs = BeautifulSoup(resp_data, 'html.parser'),resp_data表示要解析的文本,html.parser表示解析器。
BeautifulSoup常用方法

Tag常用的属性和方法

代码示例
requests使用示例
from bs4 import BeautifulSoup
import requests
url = 'https://s.weibo.com/top/summary'
resp = requests.get(url) # 向服务器发送请求并获取响应结果
print(type(resp)) # <class 'requests.models.Response'>
print(resp.status_code) # 200正常成功
resp.encoding = 'utf-8' # 设置response对象的编码格式
print(resp.text) # 将response对象转成字符串类型
bs解析的使用示例
from bs4 import BeautifulSoup
html = '''<html>
<head>
<title>马士兵教育</title>
</head>
<body>
<div id="content">
<h1>hello world</h1>
</div>
<div class="bg">
<a href="http://www.mashibing.com">你好</a>
<a href="http://www.baidu.com">程序员</a>
</div>
</body>
</html>
'''
bs = BeautifulSoup(html, 'html.parser')
div_tag = bs.find('div', class_='bg')
print(div_tag)
print(type(div_tag))
print(div_tag.text)
a_tag = div_tag.find('a', href='http://www.mashibing.com')
print(a_tag.text)
print(a_tag['href'])
a_list = div_tag.find_all('a')
print(a_list)
for item in a_list:
print(item.text)
print(item['href'])
运行结果:
D:\\Anaconda\\envs\\pachong\\python.exe F:/homework/pachong/pachong2.py
<div class="bg">
<a href="http://www.mashibing.com">你好</a>
<a href="http://www.baidu.com">程序员</a>
</div>
<class 'bs4.element.Tag'>
你好
程序员
你好
http://www.mashibing.com
[<a href="http://www.mashibing.com">你好</a>, <a href="http://www.baidu.com">程序员</a>]
你好
http://www.mashibing.com
程序员
http://www.baidu.com
Process finished with exit code 0
关于http协议部分的参考链接:
https://blog.csdn.net/qq_44907926/article/details/118585030
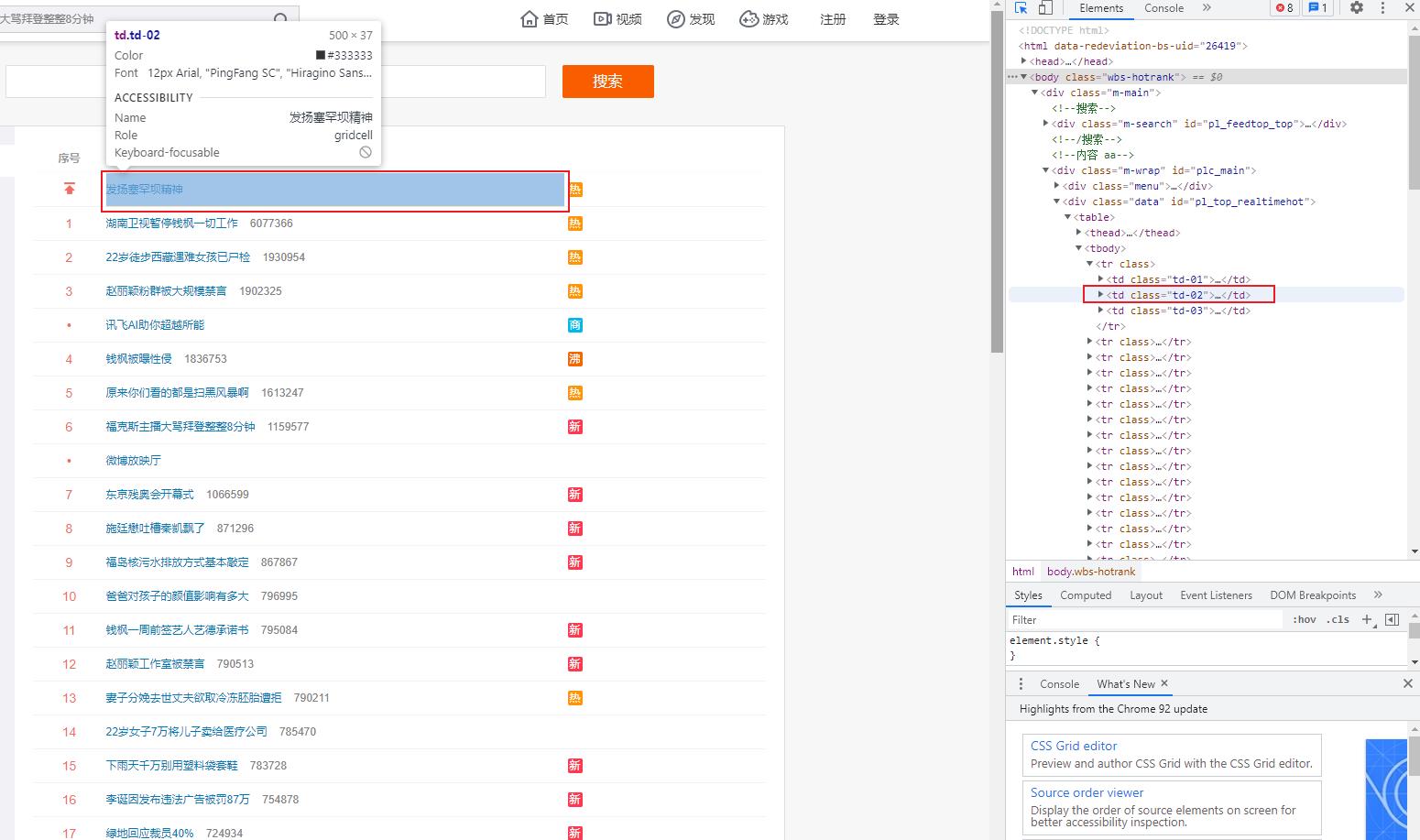
附1 选择网页中某个位置的元素进行检查
关于在网页中检查某个元素的html代码:
step1 :鼠标右键,点击检查
step2:使用快捷键ctrl+shift+c,然后选择相应的元素,或者直接点击下面的小箭头按钮
以上是关于从零到一学爬虫的主要内容,如果未能解决你的问题,请参考以下文章