《扫黑风暴》值不值得看?Pyhton爬取豆瓣短评数据告诉你答案(词云分析+情感分析可视化)
Posted Yunlord
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《扫黑风暴》值不值得看?Pyhton爬取豆瓣短评数据告诉你答案(词云分析+情感分析可视化)相关的知识,希望对你有一定的参考价值。
前言
最近一部根据真实案例改编的《扫黑风暴》刚开播就受到一致好评,全员演技在线,故事悬疑,惊悚又令人上头!
该剧顾名思义,聚焦全国扫黑除恶专项斗争,并致敬在雷霆行动中付出血与汗的当代英雄。这部剧是根据筛选的真实案例改编,讲述了中央扫黑除恶督导组进驻中江省绿藤市,将黑恶势力及保护伞成功抓获的故事。
今天我们就通过抓取豆瓣最近的短评,进行词云分析以及情感分析可视化,以此来观测其口碑走向,看看观众们对这部电视剧的评价究竟如何?

一、核心功能设计
总体来说,我们需要先从豆瓣网爬取《扫黑风暴》的短评数据,并将这些数据进行可视化分析展示。
拆解需求,大致可以整理出我们需要分为以下几步完成:
- 对豆瓣网页进行分析,确定爬虫策略;
- 通过爬虫获取豆瓣网的评论数据,包括用户名,评论内容,星级打分,推荐程度,评论时间,点赞数等,并保存成csv格式;
- 对获取的评论数据进行数据分析,通过词云绘制以及情感分析,最终进行可视化显示。
二、实现步骤
1. 豆瓣短评网页分析
首先我们打开《扫黑风暴》短评页面:
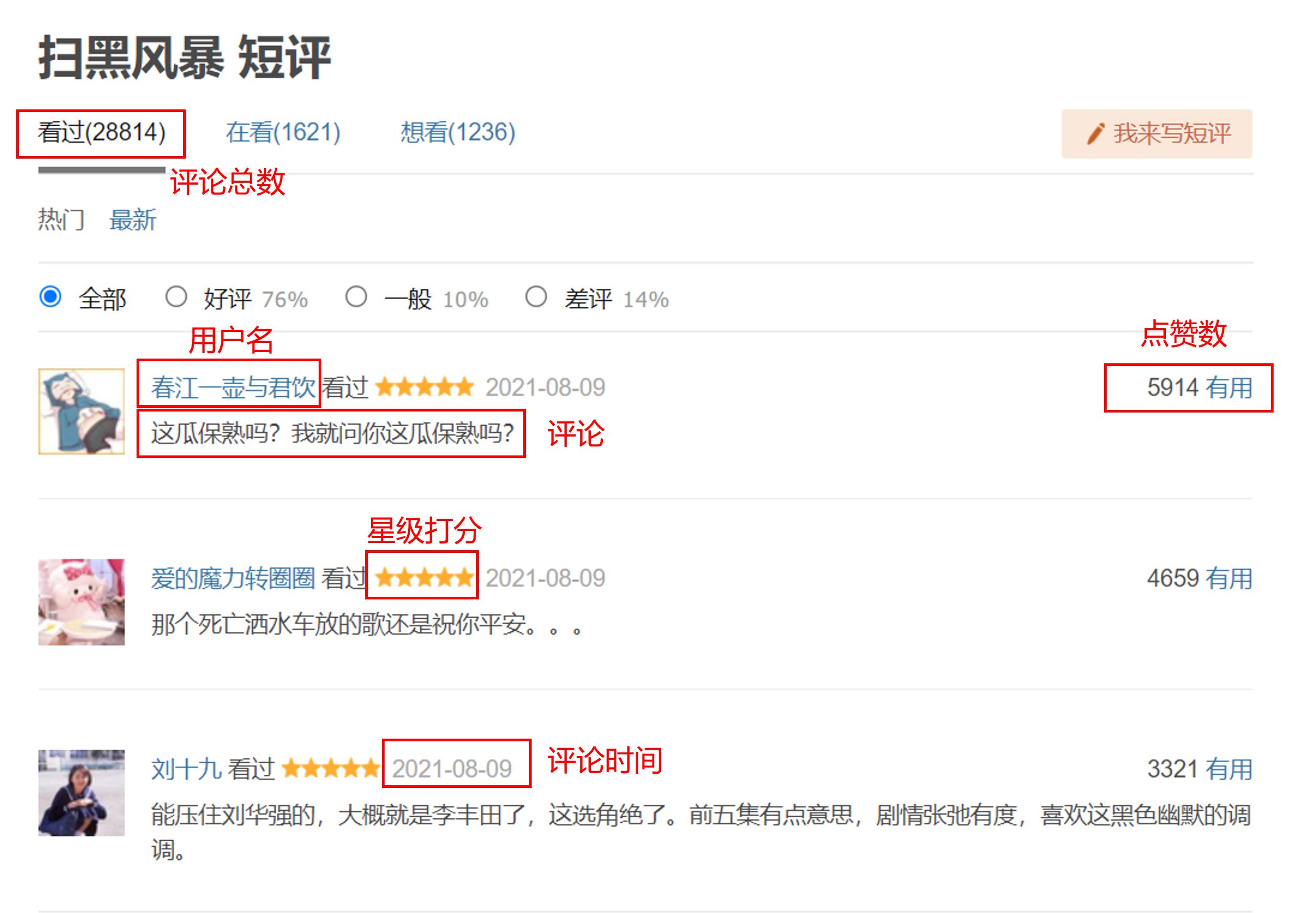
这里我们可以看到一共含有28814篇短评,以及我们所需要的用户名,评论内容,星级打分,推荐程度,评论时间,点赞数等。
接下来对数据分析,按F12,点all,然后F5刷新一下,发现有包名为review,点击response发现html源码:
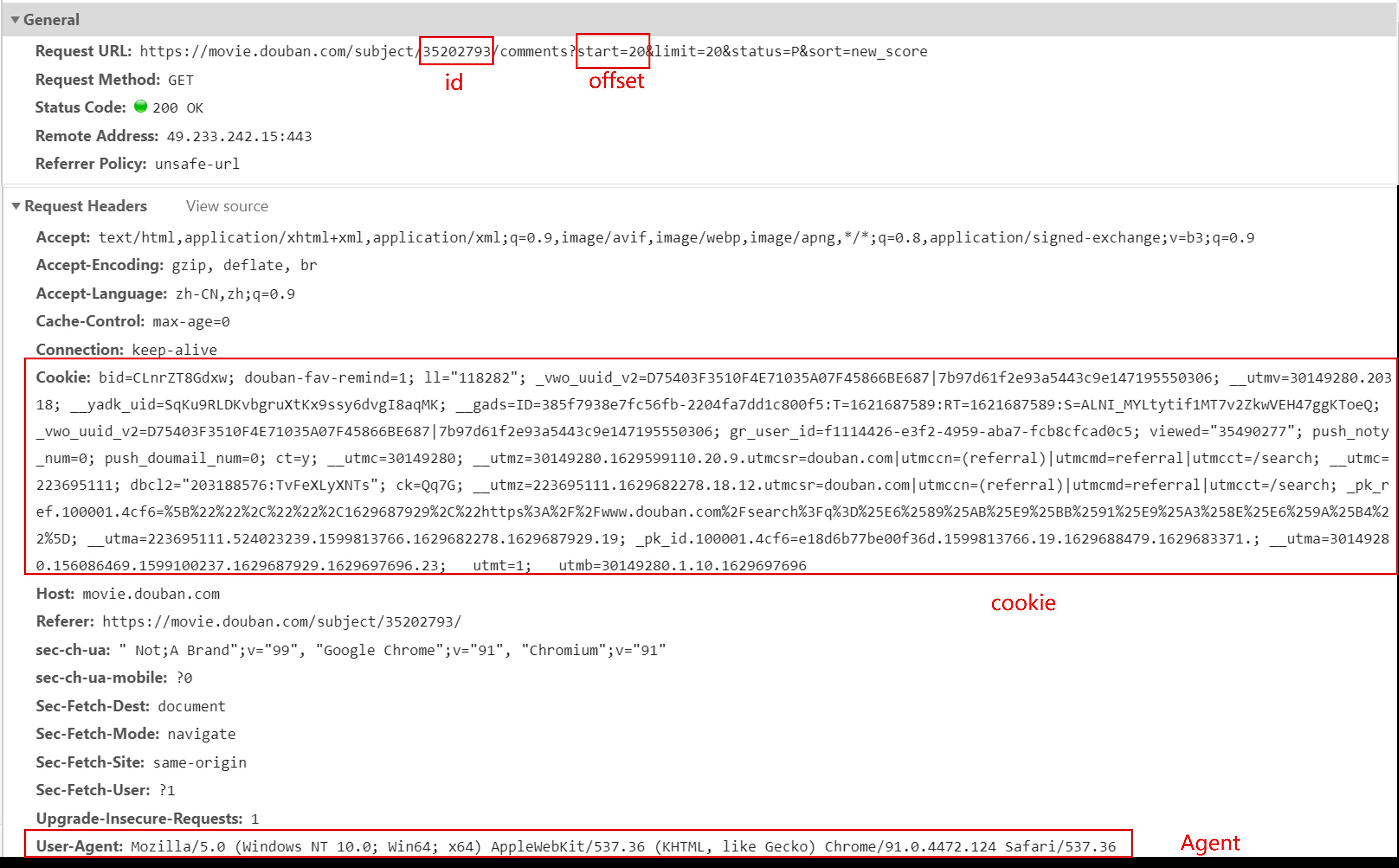 35202793就是代表《扫黑风暴》电视剧的id。
35202793就是代表《扫黑风暴》电视剧的id。
offset表示偏移量,发现 start 参数为20,这样我们可以得知,每页有20个影评。第二页参数是20,第三页参数是40。
点击 header ,查看request header项,将Cookie项全部复制下来保存到一个txt文件,后面代码直中会使用到。
2.爬取豆瓣短评数据
2.1 请求网页
def getHTML(url,movieid):
"""获取url页面"""
id = movieid
user_agents = list({
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Opera/8.0 (Windows NT 5.1; U; en)',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2 ',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14"})
headers = {
# 注意:使用登陆账号的cookie最多能爬取500条数据,使用不登录账号的cookie最多只能爬取200条数据
# 防止账号被永久封禁,请自行添加 IP 代理,或者不登陆账号,爬取少量数据做分析即可
# 'Cookie': '你保存的cookie'
'User-Agent': str(random.choice(user_agents)),
'Referer': 'https: // movie.douban.com / subject / ' + id + '/ comments?status = P',
'Connection': 'keep-alive'
}
proxy_list = [
{"http" : "41.59.90.92:80"},
{"http" : "112.126.65.193:88"},
{"http" : "115.29.98.139:9"},
{"http" : "122.96.59.184:82"},
]
proxy = random.choice(proxy_list)
httpproxy_handler = urllib.request.ProxyHandler(proxy)
opener = urllib.request.build_opener(httpproxy_handler)
request = urllib.request.Request(url,headers=headers)
response = opener.open(request)
return content
这个函数就是请求函数,输入是网页链接url和电视剧id,用来获得网页数据,但是需要你的user-agent和cookie,将之前保存cookie填入就好了。
需要注意的是使用登陆账号的cookie最多能爬取500条数据,使用不登录账号的cookie最多只能爬取200条数据,所以在这里用了代理IP,以及随机选择cookie和user-agnet。
2.2 获取总评论数
def get_quantity_page(movieid):
id = movieid
# url = 'https://movie.douban.com/subject/' + id + '/comments?start=' + str(0) + '&limit=20&sort=new_score&status=P'
url='https://movie.douban.com/subject/' + id + '/comments?'+'status=P'
html = getHTML(url,id)
bs = BeautifulSoup(html, 'html.parser')
see_string=bs.select(".is-active")[0].text
quantity=re.sub("\\D","",see_string)
return int(quantity)
由于之后我们需要爬取所有的评论数据,所以我们需要得到总评论数,用总评论数除以二十就是我们需要爬取的总页数。
2.3 影评爬取
def getComment(url,movieid):
html = getHTML(url,movieid)
bs = BeautifulSoup(html, 'html.parser')
# 评论作者
one_page_authors = []
authors = bs.select(".comment-info a")
for author in authors:
one_page_authors.append(author.text)
# 评论内容
one_page_comments = []
comments = bs.select(".comment .short")
for comment in comments:
# 去掉所有标点符号
content_str = ''.join(c for c in comment.text if c not in string.punctuation) \\
.replace(" ", "").replace("\\n", "")
one_page_comments.append(content_str)
# 评论评分
one_page_rates = []
rates = bs.select(".rating")
for rate in rates:
rate_str = str(rate.get("class")).split(" ")[0]
rate_score = int([int(i) for i in rate_str if i.isdigit()][0])
one_page_rates.append(rate_score)
# 评论title
one_page_titles = []
titles = bs.select(".rating")
for title in titles:
one_page_titles.append(title.get("title"))
# 评论日期
one_page_dates = []
dates = bs.select(".comment-time")
for date in dates:
one_page_dates.append(date.get("title"))
# 评论是否有用
one_page_uses = []
uses = bs.select(".votes")
for u in uses:
one_page_uses.append(u.text)
return [one_page_authors, one_page_comments, one_page_rates, one_page_titles, one_page_dates, one_page_uses]我们通过BeautifulSoup的select函数可以简单快速的定位到用户名,评论内容,星级打分,推荐程度,评论时间,点赞数等数据。
def main():
# file = open('movie.csv', mode="w", encoding="utf-8", newline="")
times = list(range(3, 8))
name='扫黑风暴'
movieid = str(35202793) #输入电影id号
# urls = generateURL(movieid)
quantity = get_quantity_page(movieid)
pages=math.ceil(quantity/20)
header=["authors","comments","rates","titles","dates","uses"]
table = pd.DataFrame(columns=header)
start=75
for i in tqdm(range(pages)):
url= 'https://movie.douban.com/subject/' + movieid + '/comments?start=' + str(i*20) + '&limit=20&sort=new_score&status=P'
if(i>=start):
[authors, comments, rates, titles, dates, uses] = getComment(url,movieid)
try:
for i in range(len(authors)):
a={"authors":authors[i],"comments":comments[i],"rates":rates[i],"titles":titles[i],"dates":dates[i],"uses":uses[i]}
table=table.append(a,ignore_index=True)
time.sleep(random.choice(times))
path=name+str(start)+'.csv'
table.to_csv(path,index=False,encoding="utf_8_sig")
except:
path=name+str(start)+'_'+str(i)+'.csv'
table.to_csv(path,index=False,encoding="utf_8_sig")
pass接下来将获得的数据通过Dataframe格式保存成csv格式,就大功告成了!!!这样我们就可以把需要用到的数据存储下来了,效果如下:

数据获取存储之后,接下来我们就需要进行数据分析以及可视化显示。
3.数据分析
3.1 星级评分
我们根据上面获取的观影数据,其中有一个rates属性代表评分,我们需要读取用户的评分进行一星至五星对应。
from pyecharts.charts import Pie
from pyecharts import options as opts
import collections
rates=data['rates']
c=collections.Counter(rates)
attr = ['五星', '四星', '三星', '二星', '一星']
rates=data['rates']
value = [c[5],c[4],c[3],c[2],c[1]]
pie = (
Pie()
.add("", [list(z) for z in zip(attr, value)])
.set_global_opts(title_opts=opts.TitleOpts(title="《扫黑风暴》评分比例饼图"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
)
pie.render_notebook()效果如下:

3.2 词云分析
首先我们需要准备工作,使用jieba库进行评论内容分词。jieba是一个基于Python的分词库,完美支持中文分词,功能强大。
还要安装wordcloud,一个基于Python的词云生成库,可以生成词云图。
准备工作完成之后,我们就可以根据存储的电影评论数据,绘制词云图了。
comments=data['comments']
import os
if not os.path.exists('data/stopWord.json'):
stopWord = requests.get("https://raw.githubusercontent.com/goto456/stopwords/master/cn_stopwords.txt")
with open("data/stopWord.json", "wb") as f:
f.write(stopWord.content)
# 读取下载的停用词表,并保存在列表中
with open("data/stopWord.json","r",encoding='utf-8') as f:
stopWords = f.read().split("\\n")
# 设置分词
comment_after_split = jieba.cut(str(comments), cut_all=False) # 非全模式分词,cut_all=false
words = ' '.join(comment_after_split) # 以空格进行拼接
# 设置词云参数,参数分别表示:画布宽高、背景颜色、背景图形状、字体、屏蔽词、最大词的字体大小
wc = wordcloud.WordCloud(width=1024, height=768, background_color='white', font_path='STKAITI.TTF',
stopwords=stopwords, max_font_size=400, random_state=50)
# 将分词后数据传入云图
wc.generate_from_text(words)
plt.imshow(wc)
plt.axis('off') # 不显示坐标轴
plt.show()
# 保存结果到本地
wc.to_file('词云图.jpg')效果如下:
3.3 (彩蛋)评分预测
小伙伴们还记得我上一篇《豆瓣评分预测——基于pytorch的 BERT中文文本分类》,突发奇想,想测一下根据爬取的短评实际评分与我预测的评分是否一致,于是我将爬取的这近五百条评论评分求了个平均,得到3.37分。
然后送入训练好的分类网络中预测评分,代码如下:
def final_predict(config, model, data_iter):
map_location = lambda storage, loc: storage
model.load_state_dict(torch.load(config.save_path, map_location=map_location))
model.eval()
predict_all = np.array([])
with torch.no_grad():
for texts, _ in data_iter:
outputs = model(texts)
pred = torch.max(outputs.data, 1)[1].cpu().numpy()
pred_label = [match_label(i, config) for i in pred]
predict_all = np.append(predict_all, pred_label)
return predict_all
def main(text):
config = Config()
model = Model(config).to(config.device)
test_data = load_dataset(text, config)
test_iter = build_iterator(test_data, config)
result = final_predict(config, model, test_iter)
k=0
for i, j in enumerate(result):
k=k+int(j)
ave=k/len(result)最后计算出来的评分是3.43分。

可以说与实际得分几乎一致,那么是不是可以在豆瓣评分保护机制不显示评分的时候,根据评论推测出该剧的评分呢!!!
总结
至此,《扫黑风暴》的豆瓣短评分析可视化就完成啦~~~
从分析可以看出,电视剧的整体口碑还是很不错的,最难得在于除了好看之外,它还让观众深吸一口凉气。剧情中展现的案件,是经过中央政法委筛选而出的,曾经的“操场埋尸案”和“孙小果案”都曾经引起整个社会的热议,剧集不仅将这两个案件融入其中,还融入了“网贷陷阱”等一系列社会问题,尺度之大,在近年国产剧中堪称罕见。
而剖开细节,深入好看和大尺度背后,还有一层信仰,才真正卷起观众心里的风暴。
为中国反贪扫黑点赞!!!
今天我们就到这里,明天继续努力!

如果该文章对您有所帮助,麻烦点赞,关注,收藏三连支持下!
创作不易,白嫖不好,各位的支持和认可,是我创作的最大动力!
如果本篇博客有任何错误,请批评指教,不胜感激 !!
参考:
以上是关于《扫黑风暴》值不值得看?Pyhton爬取豆瓣短评数据告诉你答案(词云分析+情感分析可视化)的主要内容,如果未能解决你的问题,请参考以下文章
“太敢拍了!”20万条弹幕告诉你,《扫黑风暴》为何能掀起收视热潮?