SpringCloud升级之路2020.0.x版-20. 启动一个 Eureka Server 集群
Posted 干货满满张哈希
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SpringCloud升级之路2020.0.x版-20. 启动一个 Eureka Server 集群相关的知识,希望对你有一定的参考价值。

本系列代码地址:https://github.com/HashZhang/spring-cloud-scaffold/tree/master/spring-cloud-iiford

我们的业务集群结构是这样的:
- 不同 Region,使用不同的 Eureka 集群管理,不同 Region 之间不互相访问。
- 同一 Region 内,可能有不同的业务集群,不同业务集群之间也不互相访问,共用同一套业务集群。
- 同一业务集群内可以随意访问,同时同一业务集群会做跨可用区的容灾。
- 在我们这里的抽象中,zone 代表不同集群,而不是实际的不同可用区。
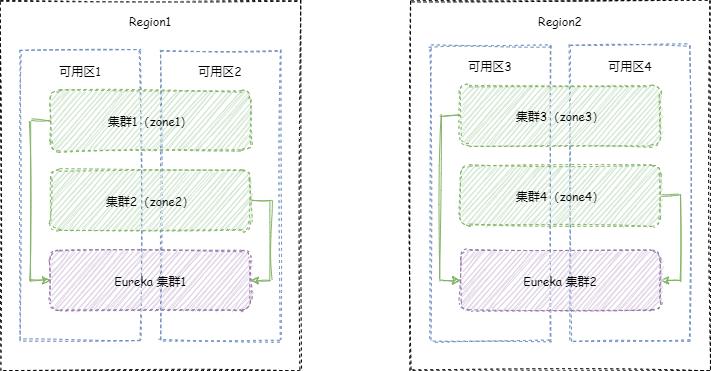
在这里,我们提供一个 Eureka Server 的集群模板,供大家参考。

首先,项目依赖是:
<dependencies>
<dependency>
<groupId>com.github.hashjang</groupId>
<artifactId>spring-cloud-iiford-spring-cloud-webmvc</artifactId>
<version>${project.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
</dependencies>
其实就是包含之前我们定义的所有同步微服务的依赖,以及 eureka-server 的相关依赖。
编写启动类,其实核心就是添加注解 @EnableEurekaServer
package com.github.hashjang.spring.cloud.iiford.eureka.server;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@SpringBootApplication
@EnableEurekaServer
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}
我们准备启动一个两个 Eureka Server 实例的集群,首先编写两个实例公共的配置,放入 application.yml:
spring:
application:
name: eureka-server
eureka:
server:
#主动检查服务实例是否失效的任务执行间隔,默认是 60s
eviction-interval-timer-in-ms: 1000
#这个配置在两个地方被使用:
#如果启用用了自我保护,则会 renewal-threshold-update-interval-ms 指定的时间内,收到的心跳请求个数是否小于实例个数乘以这个 renewal-percent-threshold
#定时任务检查过期实例,每次最多过期 1 - renewal-percent-threshold 这么多比例的实例
renewal-percent-threshold: 0.85
#注意,最好所有的客户端实例配置的心跳时间相关的配置,是相同的。这样使用自我保护的特性最准确。
#关闭自我保护
#我们这里不使用自我保护,因为:
#自我保护主要针对集群中网络出现问题,导致有很多实例无法发送心跳导致很多实例状态异常,但是实际实例还在正常工作的情况,不要让这些实例不参与负载均衡
#启用自我保护的情况下,就会停止对于实例的过期
#但是,如果出现这种情况,其实也代表很多实例无法读取注册中心了。
#并且还有一种情况就是,Eureka 重启。虽然不常见,但是对于镜像中其他的组件更新我们还是很频繁的
#我倾向于从客户端对于实例缓存机制来解决这个问题,如果返回实例列表为空,则使用上次的实例列表进行负载均衡,这样既能解决 Eureka 重启的情况,又能处理一些 Eureka 网络隔离的情况
#自我保护模式基于每分钟需要收到 renew (实例心跳)请求个数,如果启用了自我保护模式,只有上一分钟接收到的 renew 个数,大于这个值,实例过期才会被注销
enable-self-preservation: false
# 增量实例队列实例过期时间,默认 3 分钟
retention-time-in-m-s-in-delta-queue: 180000
# 增量实例队列过期任务间隔,默认 30s
delta-retention-timer-interval-in-ms: 30000
# 响应缓存中有两个主要元素,一个是 readOnlyCacheMap,另一个是 readWriteCacheMap
# 是否使用 readOnlyCacheMap,默认为 true
# 如果为是,则从 readOnlyCacheMap 读取,否则直接读取 readWriteCacheMap
use-readonly-response-cahce: true
# 初始 readWriteCacheMap 大小,默认 1000
initial-capacity-of-response-cache: 1000
# LoadingCache 缓存过期时间,默认 180s
response-cache-auto-expiration-in-seconds: 9
# 定时从 LoadingCache 同步到只读缓存的间隔时间,默认为 30s
response-cache-update-interval-ms: 3000
client:
service-url:
# 默认eureka集群,这里必须是defaultZone,不能用-替换大写,与其他的配置不一样,因为实在EurekaClientConfigBean里面写死的
defaultZone: 'http://127.0.0.1:8211/eureka/,http://127.0.0.1:8212/eureka/'
# 是否从 eureka 上面拉取实例, eureka server 不调用其他微服务,所以没必要拉取
fetch-registry: false
# 是否将自己注册到 eureka 上面,eureka server 不参与负载均衡,所以没必要注册
register-with-eureka: false
server:
undertow:
# 以下的配置会影响buffer,这些buffer会用于服务器连接的IO操作
# 如果每次需要 ByteBuffer 的时候都去申请,对于堆内存的 ByteBuffer 需要走 JVM 内存分配流程(TLAB -> 堆),对于直接内存则需要走系统调用,这样效率是很低下的。
# 所以,一般都会引入内存池。在这里就是 `BufferPool`。
# 目前,UnderTow 中只有一种 `DefaultByteBufferPool`,其他的实现目前没有用。
# 这个 DefaultByteBufferPool 相对于 netty 的 ByteBufArena 来说,非常简单,类似于 JVM TLAB 的机制
# 对于 bufferSize,最好和你系统的 TCP Socket Buffer 配置一样
# `/proc/sys/net/ipv4/tcp_rmem` (对于读取)
# `/proc/sys/net/ipv4/tcp_wmem` (对于写入)
# 在内存大于 128 MB 时,bufferSize 为 16 KB 减去 20 字节,这 20 字节用于协议头
buffer-size: 16364
# 是否分配的直接内存(NIO直接分配的堆外内存),这里开启,所以java启动参数需要配置下直接内存大小,减少不必要的GC
# 在内存大于 128 MB 时,默认就是使用直接内存的
directBuffers: true
threads:
# 设置IO线程数, 它主要执行非阻塞的任务,它们会负责多个连接, 默认设置每个CPU核心一个读线程和一个写线程
io: 4
# 阻塞任务线程池, 当执行类似servlet请求阻塞IO操作, undertow会从这个线程池中取得线程
# 它的值设置取决于系统线程执行任务的阻塞系数,默认值是IO线程数*8
worker: 128
# http post body 大小,默认为 -1B ,即不限制
max-http-post-size: -1B
# 是否在启动时创建 filter,默认为 true,不用修改
eager-filter-init: true
# 限制路径参数数量,默认为 1000
max-parameters: 1000
# 限制 http header 数量,默认为 200
max-headers: 200
# 限制 http header 中 cookies 的键值对数量,默认为 200
max-cookies: 200
# 是否允许 / 与 %2F 转义。/ 是 URL 保留字,除非你的应用明确需要,否则不要开启这个转义,默认为 false
allow-encoded-slash: false
# 是否允许 URL 解码,默认为 true,除了 %2F 其他的都会处理
decode-url: true
# url 字符编码集,默认是 utf-8
url-charset: utf-8
# 响应的 http header 是否会加上 'Connection: keep-alive',默认为 true
always-set-keep-alive: true
# 请求超时,默认是不超时,我们的微服务因为可能有长时间的定时任务,所以不做服务端超时,都用客户端超时,所以我们保持这个默认配置
no-request-timeout: -1
# 是否在跳转的时候保持 path,默认是关闭的,一般不用配置
preserve-path-on-forward: false
options:
# spring boot 没有抽象的 xnio 相关配置在这里配置,对应 org.xnio.Options 类
socket:
SSL_ENABLED: false
# spring boot 没有抽象的 undertow 相关配置在这里配置,对应 io.undertow.UndertowOptions 类
server:
ALLOW_UNKNOWN_PROTOCOLS: false
# access log相关配置
accesslog:
# 存放目录,默认为 logs
dir: ./logs/${server.port}
# 是否开启
enabled: true
# 格式,各种占位符后面会详细说明
pattern: '{
"transportProtocol":"%{TRANSPORT_PROTOCOL}",
"scheme":"%{SCHEME}",
"protocol":"%{PROTOCOL}",
"method":"%{METHOD}",
"reqHeaderUserAgent":"%{i,User-Agent}",
"reqHeaderUserId":"%{i,uid}",
"traceId":"%{i,X-B3-TraceId}",
"spanId":"%{i,X-B3-SpanId}",
"queryString": "%q",
"uri": "%U",
"thread": "%I",
"hostPort": "%{HOST_AND_PORT}",
"localIp": "%A",
"localPort": "%p",
"localServerName": "%v",
"remoteIp": "%a",
"bytesSent": "%b",
"time":"%{time,yyyy-MM-dd HH:mm:ss.S}",
"status":"%s",
"reason":"%{RESPONSE_REASON_PHRASE}",
"timeUsed":"%Dms"
}'
# 文件前缀,默认为 access_log
prefix: access.
# 文件后缀,默认为 log
suffix: log
# 是否另起日志文件写 access log,默认为 true
# 目前只能按照日期进行 rotate,一天一个日志文件
rotate: true
management:
endpoint:
health:
show-details: always
endpoints:
jmx:
exposure:
exclude: '*'
web:
exposure:
include: '*'
除了同步微服务 undertow 的配置以及 actuator 的配置,Eureka 配置中,由于 Eureka Server 感知其他实例,仅仅通过 eureka.client.service-url 这个配置读取,所以不需要 eureka server 注册到 eureka server 或者读取 eureka server 上面的实例,因此这里我们配置不注册也不读取。然后,我们这里按照之前分析的,关闭了自我保护,开启了定时过期任务,并且将相关的定时任务时间间隔都调低了不少,因为我们的集群不是万个实例级别的,而是一千左右,所以可以调高这些任务频率。
之后,我们编写两个实例特定 profile 的配置,其实就是提供服务的端口不一样,即:
application-eureka1.yml
server:
port: 8211
application-eureka2.yml
server:
port: 8212
之后,我们通过 IDEA 的环境变量配置,第一个 Eureka Server 的环境变量指定 spring.profiles.active=eureka1,第二个 Eureka Server 的环境变量指定 spring.profiles.active=eureka2,分别启动。即可成为一个 Eureka 集群。大家可以尝试往其中一个实例注册一个服务实例,看另一个实例上是否被同步了这个服务实例。

我们这一节给大家提供一个配置模板,启动一个 Eureka Server 集群。下一节,我们将开始分析并使用我们项目中的负载均衡器 Spring Cloud Loadbalancer
微信搜索“我的编程喵”关注公众号,每日一刷,轻松提升技术,斩获各种offer:

以上是关于SpringCloud升级之路2020.0.x版-20. 启动一个 Eureka Server 集群的主要内容,如果未能解决你的问题,请参考以下文章
SpringCloud升级之路2020.0.x版-7.从Bean到SpringCloud
SpringCloud升级之路2020.0.x版-44.避免链路信息丢失做的设计
SpringCloud升级之路2020.0.x版-41. SpringCloudGateway 基本流程讲解
SpringCloud升级之路2020.0.x版-22.Spring Cloud LoadBalan