一条SQL语句是怎么执行之“步步惊心”过程详解与案例分析
Posted ShenLiang2025
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一条SQL语句是怎么执行之“步步惊心”过程详解与案例分析相关的知识,希望对你有一定的参考价值。
SQL逻辑执行过程详解
表与数据
-- 1 创建 HR.Employees表
CREATE TABLE HR.Employees
(
empid INT NOT NULL IDENTITY,
lastname NVARCHAR(20) NOT NULL,
firstname NVARCHAR(10) NOT NULL,
title NVARCHAR(30) NOT NULL,
titleofcourtesy NVARCHAR(25) NOT NULL,
birthdate DATE NOT NULL,
hiredate DATE NOT NULL,
address NVARCHAR(60) NOT NULL,
city NVARCHAR(15) NOT NULL,
region NVARCHAR(15) NULL,
postalcode NVARCHAR(10) NULL,
country NVARCHAR(15) NOT NULL,
phone NVARCHAR(24) NOT NULL,
mgrid INT NULL,
CONSTRAINT PK_Employees PRIMARY KEY(empid),
CONSTRAINT FK_Employees_Employees FOREIGN KEY(mgrid)
REFERENCES HR.Employees(empid),
CONSTRAINT CHK_birthdate CHECK(birthdate <= CAST(SYSDATETIME() AS DATE))
);
CREATE NONCLUSTERED INDEX idx_nc_lastname ON HR.Employees(lastname);
CREATE NONCLUSTERED INDEX idx_nc_postalcode ON HR.Employees(postalcode);
-- 2 初始化数据
SET IDENTITY_INSERT HR.Employees ON;
INSERT INTO HR.Employees(empid, lastname, firstname, title, titleofcourtesy, birthdate, hiredate, address, city, region, postalcode, country, phone, mgrid)
VALUES(1, N'Davis', N'Sara', N'CEO', N'Ms.', '19681208', '20130501', N'7890 - 20th Ave. E., Apt. 2A', N'Seattle', N'WA', N'10003', N'USA', N'(206) 555-0101', NULL);
INSERT INTO HR.Employees(empid, lastname, firstname, title, titleofcourtesy, birthdate, hiredate, address, city, region, postalcode, country, phone, mgrid)
VALUES(2, N'Funk', N'Don', N'Vice President, Sales', N'Dr.', '19720219', '20130814', N'9012 W. Capital Way', N'Tacoma', N'WA', N'10001', N'USA', N'(206) 555-0100', 1);
INSERT INTO HR.Employees(empid, lastname, firstname, title, titleofcourtesy, birthdate, hiredate, address, city, region, postalcode, country, phone, mgrid)
VALUES(3, N'Lew', N'Judy', N'Sales Manager', N'Ms.', '19830830', '20130401', N'2345 Moss Bay Blvd.', N'Kirkland', N'WA', N'10007', N'USA', N'(206) 555-0103', 2);
INSERT INTO HR.Employees(empid, lastname, firstname, title, titleofcourtesy, birthdate, hiredate, address, city, region, postalcode, country, phone, mgrid)
VALUES(4, N'Peled', N'Yael', N'Sales Representative', N'Mrs.', '19570919', '20140503', N'5678 Old Redmond Rd.', N'Redmond', N'WA', N'10009', N'USA', N'(206) 555-0104', 3);
INSERT INTO HR.Employees(empid, lastname, firstname, title, titleofcourtesy, birthdate, hiredate, address, city, region, postalcode, country, phone, mgrid)
VALUES(5, N'Mortensen', N'Sven', N'Sales Manager', N'Mr.', '19750304', '20141017', N'8901 Garrett Hill', N'London', NULL, N'10004', N'UK', N'(71) 234-5678', 2);
INSERT INTO HR.Employees(empid, lastname, firstname, title, titleofcourtesy, birthdate, hiredate, address, city, region, postalcode, country, phone, mgrid)
VALUES(6, N'Suurs', N'Paul', N'Sales Representative', N'Mr.', '19830702', '20141017', N'3456 Coventry House, Miner Rd.', N'London', NULL, N'10005', N'UK', N'(71) 345-6789', 5);
INSERT INTO HR.Employees(empid, lastname, firstname, title, titleofcourtesy, birthdate, hiredate, address, city, region, postalcode, country, phone, mgrid)
VALUES(7, N'King', N'Russell', N'Sales Representative', N'Mr.', '19800529', '20150102', N'6789 Edgeham Hollow, Winchester Way', N'London', NULL, N'10002', N'UK', N'(71) 123-4567', 5);
INSERT INTO HR.Employees(empid, lastname, firstname, title, titleofcourtesy, birthdate, hiredate, address, city, region, postalcode, country, phone, mgrid)
VALUES(8, N'Cameron', N'Maria', N'Sales Representative', N'Ms.', '19780109', '20150305', N'4567 - 11th Ave. N.E.', N'Seattle', N'WA', N'10006', N'USA', N'(206) 555-0102', 3);
INSERT INTO HR.Employees(empid, lastname, firstname, title, titleofcourtesy, birthdate, hiredate, address, city, region, postalcode, country, phone, mgrid)
VALUES(9, N'Doyle', N'Patricia', N'Sales Representative', N'Ms.', '19860127', '20151115', N'1234 Houndstooth Rd.', N'London', NULL, N'10008', N'UK', N'(71) 456-7890', 5);
SET IDENTITY_INSERT HR.Employees OFF;
SQL实例
/*
要求:统计员工表里2014年1月1号及之后入职的员工所在国家、所属年份、人数,
过滤条件:以上信息里每个过国家和年份至少要对应有两条记录
排序:排序时按照国家和年份降序排列。
*/
SELECT country, YEAR(hiredate) AS yearhired, COUNT(*) AS numemployees
FROM HR.Employees
WHERE hiredate >= ‘20140101‘
GROUP BY country, YEAR(hiredate)
HAVING COUNT(*) > 1
ORDER BY country, yearhired DESC;
执行过程
SQL不像程序语言顺序去执行代码,它有自己的执行顺序。一般我们先从表和视图开始,然后是记录的WHERE过滤,再是分组和分组过滤,然后是SELECT列表,最后是ORDER BY排序。即对应:
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
- ORDER BY
过程分解
1 FROM
Step1: 首先锁定FROM后的表HR.Employees,此时的员工表有9条记录:
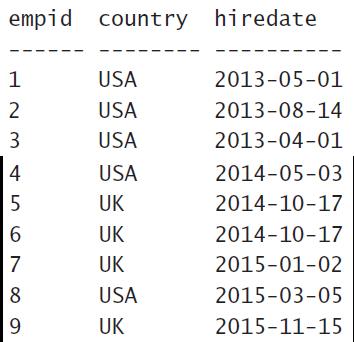
2 WHERE
Step2:接着通过WHERE关键字去Filter(过滤或者筛选) hiredate(入职时间)晚于2014年1月1日的记录。这里用到到了算数表达式“≥”(大于等于)。因为针对时间类型,如果我们给的是字符串并且它是时间格式的。比如:20140101、2014-01-01、2014/01/01等,那么数据库会将该字符串饮隐式(自动)转成时间类型以进行时间的比较。所以过滤后的结果为:
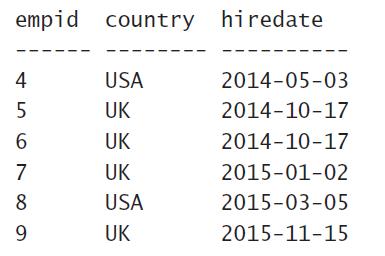
注:
初学时我们会犯如下的错误:

即在WHERE后直接用SELECT里字段的别名,如:
SELECT country, YEAR(hiredate) AS yearhired
FROM HR.Employees
WHERE yearhired >= 2014;这显然是错误,那是因为当前还没有执行到SELECT环节,所以不知道别名yearhired。
3 GROUP BY
Step3:然后我们开始做分组了,这里要使用个函数Year来取hiredate(入职时间)里的年份。我们知道日期类型有“年月日”构成,当前需求是按照年这个维度进行统计,所以需要使用这个函数,而country(国家)字段我们放在GROUP BY之后即可。分组之后的数据长这样:
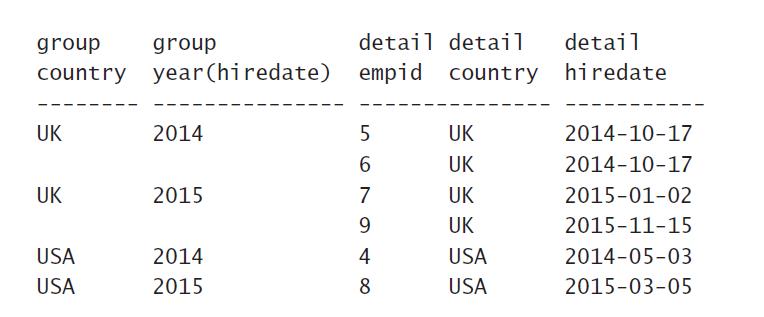
4 HAVING
Step4:通过观察Step3里的结果我们返现国家是USA、年份是2014、2015的两类数据,每类只有1条,也就是说2014年、USA仅有1人入职;2015年、USA仅有1人入职,这个不是想要的,需求是每个分(类)组数据至少得有2条。这种对分组进行过滤的关键字就是HAVING,所以我们加上语句HAVING(COUNT(*))>1,即每个分类(组)的个数得是1以上。此时的结果长这样: 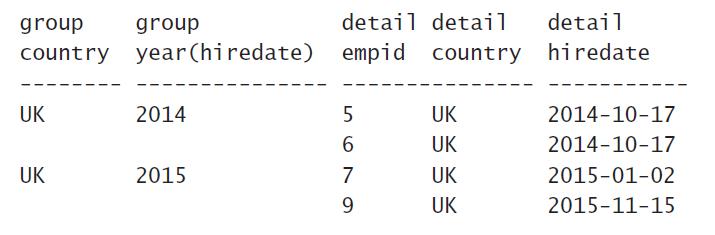
5 SELECT
Step5:目前Step4里的字段较多,而我们只想要COUNTRY(国家)、yearhired(年份)、numemployees(员工数),所以我们在结果集的返回列表里通过SELECT关键字往后依次写上这些字段(列)或者这些字段相关的函数,那么此时的结果为:
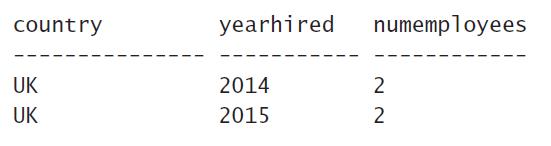
注:类似在WHERE里引用SELECT里的字段别名,在SELECT环节,我们同样不能引用字段的别名。即如下写法是报错的:
SELECT empid, country, YEAR(hiredate) AS yearhired, yearhired - 1 AS prevyear
FROM HR.Employees;
原因是SELECT后里的语句、字段、别名是在一个批次里执行的,所以无法引用别名。但放在下一步的ORDER BY是可以的。
6 ORDER BY
Step6:结果和目标很接近了,再看看需求,我们需要对年份字段要按照逆序(降序)排列,即如果是数字、时间类型的,大的在前,小的在后;如果是字符串(以英文字母为例)类型的则z到a,反之正序(升序)则反过来。所以我们需要用到ORDER BY关键字,后跟字段或者字段的函数以及DESC(降序)、ASC(升序,可省略)来定义排序规则。所以得到最终结果:
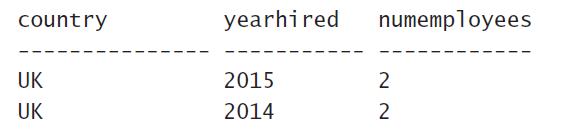
以上是关于一条SQL语句是怎么执行之“步步惊心”过程详解与案例分析的主要内容,如果未能解决你的问题,请参考以下文章