近万字的Numpy总结——边学边练
Posted 神的孩子都在歌唱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了近万字的Numpy总结——边学边练相关的知识,希望对你有一定的参考价值。
前言:
作者:神的孩子在歌唱
大家好,我叫陈运智,大家可以叫我小智
一. Naddary结构总结
首先我们得导入包
import numpy as np
1.1 属性
使用以下函数可以打印出数组的属性
| 属性名字 | 属性解释 |
|---|---|
| ndarray.shape | 数组维度的元组 |
| ndarray.ndim | 数组维数 |
| ndarray.size | 数组中的元素数量 |
| ndarray.itemsize | 一个数组元素的长度(字节) |
| ndarray.dtype | 数组元素的类型 |
列:
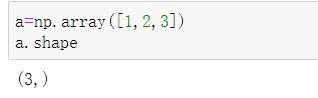
1.2 形状
这里说的形状就是他的维度
列:
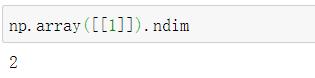
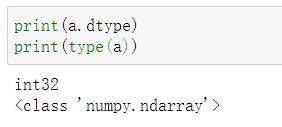
1.3类型
| 名称 | 描述 | 简写 |
|---|---|---|
| np.bool | 用一个字节存储的布尔类型(True或False) | ‘b’ |
| np.int8 | 一个字节大小,-128 至 127 | ‘i’ |
| np.int16 | 整数,-32768 至 32767 | ‘i2’ |
| np.int32 | 整数,-2 31 至 2 32 -1 | ‘i4’ |
| np.int64 | 整数,-2 63 至 2 63 - 1 | ‘i8’ |
| np.uint8 | 无符号整数,0 至 255 | ‘u’ |
| np.uint16 | 无符号整数,0 至 65535 | ‘u2’ |
| np.uint32 | 无符号整数,0 至 2 ** 32 - 1 | ‘u4’ |
| np.uint64 | 无符号整数,0 至 2 ** 64 - 1 | ‘u8’ |
| np.float16 | 半精度浮点数:16位,正负号1位,指数5位,精度10位 | ‘f2’ |
| np.float32 | 单精度浮点数:32位,正负号1位,指数8位,精度23位 | ‘f4’ |
| np.float64 | 双精度浮点数:64位,正负号1位,指数11位,精度52位 | ‘f8’ |
| np.complex64 | 复数,分别用两个32位浮点数表示实部和虚部 | ‘c8’ |
| np.complex128 | 复数,分别用两个64位浮点数表示实部和虚部 | ‘c16’ |
| np.object_ | python对象 | ‘O’ |
| np.string_ | 字符串 | ‘S’ |
| np.unicode_ | unicode类型 | ‘U’ |
二. 基本操作
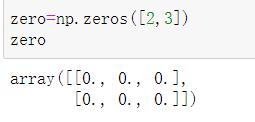
2.1 生成0和1的数组zeros,ones
- 生成0的数组
np.zeros(shape[, dtype, order])#里面输入维度
- 生成1的数组
np.ones(shape[, dtype, order])

2.2 转化现有的数组 array和asarray
- 创建新的索引
array=np.array(ones)
array
array([[1., 1., 1.],
[1., 1., 1.]])
- 引用之前数组
asarray=np.asarray(ones)
asarray
array([[1., 1., 1.],
[1., 1., 1.]])
- 测试
ones[1]=2
array,asarray
(array([[1., 1., 1.],
[1., 1., 1.]]),
array([[1., 1., 1.],
[2., 2., 2.]]))
总结:array是创建一个新的索引,asarray是引用之前的数组,原来的改变了他也得改变
array([[1., 1., 1.],
[1., 1., 1.]])
2.3 生成固定范围的数组 linspace
生成等间隔的序列:
np.linspace (start, stop, num, endpoint)
start序列的起始值
stop序列的终止值,
num要生成的等间隔样例数量,默认为50
endpoint序列中是否包含stop值,默认为ture
列:

2.4 生成随机数组 random
2.4.1 rand()
返回[0.0,1.0)内的一组均匀分布的数。
np.random.rand(d0, d1, ..., dn)
d0是一维,d1是二维
列:
rand=np.random.rand(2)
print(rand)
print()
rand_1=np.random.rand(1,2)
print(rand_1)
[0.20820084 0.42793728]
[[0.17072535 0.54934689]]
2.4.2 uniform()
- 功能:从一个均匀分布[low,high)中随机采样,注意定义域是左闭右开,即包含low,不包含high.
np.random.uniform(low=0.0, high=1.0, size=None)
- 参数介绍:
(1)low: 采样下界,float类型,默认值为0;
(2)high: 采样上界,float类型,默认值为1;
(3)size: 输出样本数目,为int或元组(tuple)类型,例如,size=(m,n,k), 则输出mnk个样本,缺省时输出1个值。
#左闭右开,可以包含low不能包含high
uniform=np.random.uniform(-1,1,5)#随机生成-1<=x<1的5个数
uniform
array([ 0.1210682 , -0.57715686, 0.13236878, 0.25356491, 0.23658474])
2.4.3 randint()
- 定义:从一个均匀分布中随机采样,生成一个整数或N维整数数组
np.random.randint(low, high=None, size=None, dtype='l')
- 取数范围:若
high不为None时,取[low,high)之间随机整数,否则取值[0,low)之间随机整数。
列:
randint=np.random.randint(-1,1,5)#生成的是整数
randint
array([ 0, 0, -1, -1, 0])
- 可以用画布看一下
import matplotlib.pyplot as plt
#生成随机数
uniform=np.random.uniform(-1,1,5)#随机生成-1<=x<1的5个数
randint=np.random.randint(-1,1,5)#生成的是整数
#创建画布
plt.figure(figsize=(10,10),dpi=100)
#绘制折线图
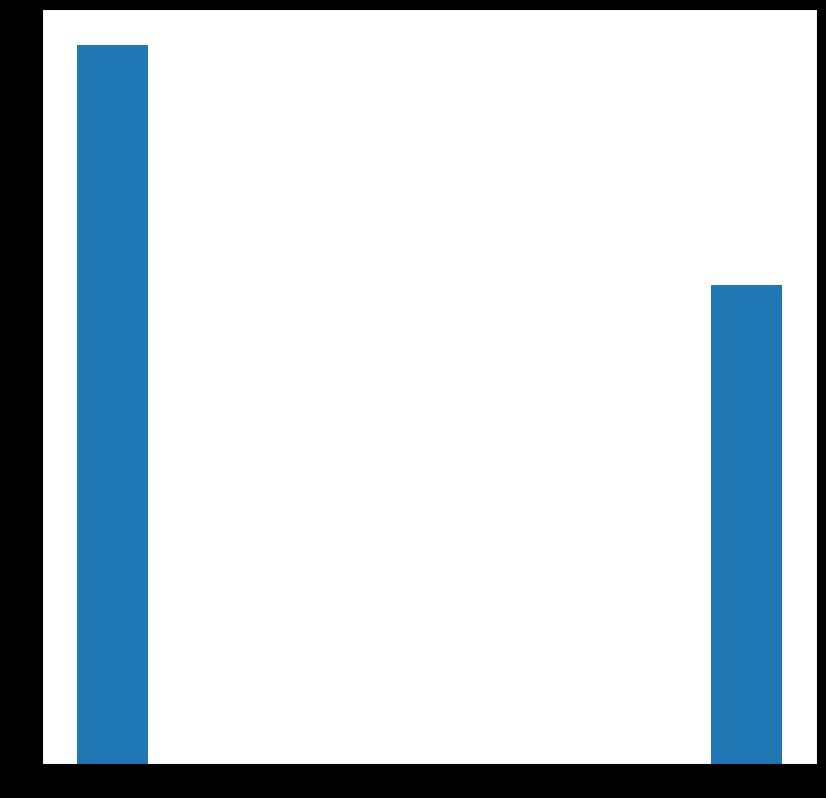
plt.hist(x=randint,bins=10)
#显示图像
plt.show()
三. 正态分布创建方式
正态分布是一种概率分布。正态分布是具有两个参数μ和σ的连续型随机变量的分布,第一参数μ是服从正态分布的随机变量的均值,第二个参数σ是此随机变量的方差,所以正态分布记作N(μ,σ )。
np.random.normal(loc=0.0, scale=1.0, size=None)
loc:float 此概率分布的均值(对应着整个分布的中心centre)
scale:float 此概率分布的标准差(对应于分布的宽度,scale越大越矮胖,scale越小,越瘦高)
size:int or tuple of ints 输出的shape,默认为None,只输出一个值
代码:

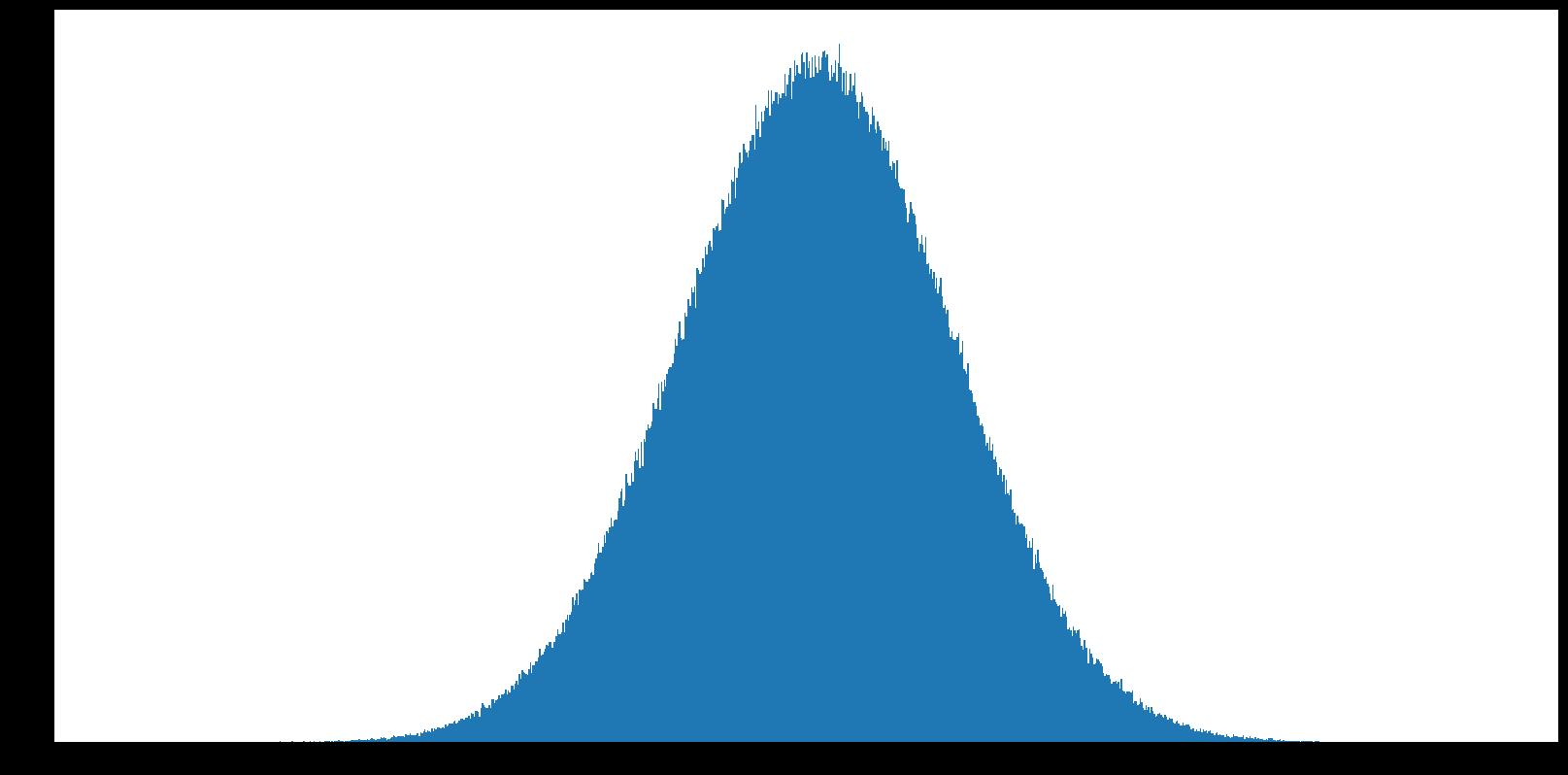
#我们弄个图来看看就知道了
normal=np.random.normal(0,1,1000000)#生成随机数
plt.figure(figsize=(20,10),dpi=100)
plt.hist(normal,1000)
plt.show()
#数据样本越多越平滑
四. 数组的索引和切片
#随机生成0~1内的一个二维数组
x=np.random.rand(3,4)
x
array([[0.49210879, 0.53267771, 0.31260445, 0.10365951],
[0.95440635, 0.79749711, 0.83076363, 0.45117356],
[0.58863855, 0.38651589, 0.32089043, 0.80523703]])
#获取第一列前两个数
x[0,0:2]
array([0.49210879, 0.53267771])
#来看看三维的
x1=np.random.rand(2,3,4)#创建一个三行四列的三维数组
x1
array([[[0.2535971 , 0.78289806, 0.19668332, 0.33726196],
[0.71314755, 0.6701532 , 0.00122882, 0.34245938],
[0.84117058, 0.51255648, 0.9877622 , 0.77474966]],
[[0.71203189, 0.09165988, 0.03920414, 0.20560316],
[0.69056241, 0.35672482, 0.61398699, 0.28555582],
[0.23272967, 0.03492783, 0.54847214, 0.07739248]]])
#获取第一个二行四列的数
x1[0,1,3]
0.342459375072406
4.1 形状修改 reshape 和 T
#创建一个二维数组
rand=np.random.rand(2,3)
rand
array([[0.76541987, 0.02147122, 0.37629224],
[0.11469583, 0.5610669 , 0.65114404]])
#修改rand为3行2列
rand.reshape([3,2])
array([[0.76541987, 0.02147122],
[0.37629224, 0.11469583],
[0.5610669 , 0.65114404]])
#可以将行设置为-1,表示待机算,就是随便取什么值都行
rand.reshape([-1,2])
array([[0.76541987, 0.02147122],
[0.37629224, 0.11469583],
[0.5610669 , 0.65114404]])
#数组的转置
print(rand.shape)
print(rand.T.shape)
(2, 3)
(3, 2)
4.2 类型修改 astype
rand.tostring()
b' B4\\xcfQ~\\xe8?`7tE\\x8d\\xfc\\x95?\\xa6\\x84V\\t,\\x15\\xd8?\\x08\\xff\\xd9\\xa7\\xb4\\\\\\xbd?\\t\\xa3V\\x94B\\xf4\\xe1?\\xb1.\\xca\\x07,\\xd6\\xe4?'
rand.astype(np.float32)
array([[0.76541984, 0.02147122, 0.37629223],
[0.11469582, 0.5610669 , 0.651144 ]], dtype=float32)
4.3 数组去重 unique
temp=np.array([[1,2,3],[1,3,4]])
np.unique(temp)
array([1, 2, 3, 4])
五. ndarray运算
5.1 逻辑运算
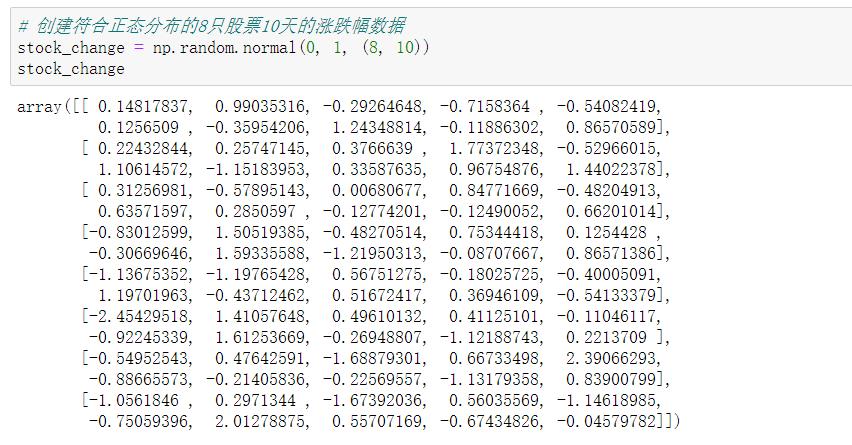
# 重新生成8只股票10个交易日的涨跌幅数据
stock_change=np.random.normal(0,1,(8,10))
stock_change=stock_change[0:5,0:5]#取前五行,和前五列个数
stock_change
array([[-1.52755746, -2.62057116, 0.592167 , -0.21291779, 2.32848585],
[ 0.07585879, -1.31915832, 0.17912436, 1.36065436, -0.59037947],
[ 0.12463083, -1.20308184, -0.75948532, 0.94894654, -0.75995878],
[-2.01017904, 0.99691299, 0.02376165, -0.27839167, 0.0081121 ],
[-3.51140042, -0.37608421, 1.62691763, 2.29858084, 1.71294573]])
# 逻辑判断, 如果涨跌幅大于0.5就标记为True 否则为False
stock_change>0.5
array([[False, False, True, False, True],
[False, False, False, True, False],
[False, False, False, True, False],
[False, True, False, False, False],
[False, False, True, True, True]])
#将大于0.5的设置为1
# BOOL赋值, 将满足条件的设置为指定的值-布尔索引
stock_change[stock_change > 0.5] = 1
stock_change
array([[-1.52755746, -2.62057116, 1. , -0.21291779, 1. ],
[ 0.07585879, -1.31915832, 0.17912436, 1. , -0.59037947],
[ 0.12463083, -1.20308184, -0.75948532, 1. , -0.75995878],
[-2.01017904, 1. , 0.02376165, -0.27839167, 0.0081121 ],
[-3.51140042, -0.37608421, 1. , 1. , 1. ]])
5.2 通用判断函数 np.all()相当于and ,np.any() 相当于or
# 判断stock_change[0:2, 0:5]是否全是上涨的,就是是否全部大于0
np.all(stock_change[0:2,0:5]>0)
False
# # 判断前5只股票这段期间是否有上涨的
np.any(stock_change[0:5, :] > 0 )
True
5.3 np.where(三元运算符)
## 判断前四个股票前四天的涨跌幅 大于0的置为1,否则为0
temp=stock_change[:4,:4]
temp
np.where(temp>0,1,0)#大于零就设置为1,小于就设置为0
array([[0, 0, 1, 0],
[1, 0, 1, 1],
[1, 0, 0, 1],
[0, 1, 1, 0]])
# 判断前四个股票前四天的涨跌幅 大于0.5并且小于1的,换为1,否则为0
# 判断前四个股票前四天的涨跌幅 大于0.5或者小于-0.5的,换为1,否则为0
np.where(np.logical_and(temp > 0.5, temp < 1), 1, 0)
np.where(np.logical_or(temp > 0.5, temp < -0.5), 1, 0)
array([[1, 1, 1, 0],
[0, 1, 0, 1],
[0, 1, 1, 1],
[1, 1, 0, 0]])
5.4 统计运算案列:股票涨跌幅
进行统计的时候,axis 轴的取值并不一定,Numpy中不同的API轴的值都不一样,在这里,axis 0代表列, axis
1代表行去进行统计
max:最大值
std:标准差
min:最小值
mean :平均值
argmax:最大下标
argmin:最小值的下标
stock_change=np.random.normal(0,1,(8,10))
stock_change
temp=stock_change[:4,:4]
temp
array([[-0.40505247, 0.92951889, 2.011763 , -0.53131927],
[ 0.0192382 , 0.99129611, 1.25257476, 1.11735188],
[-0.82399859, 1.23058116, -0.7239252 , -0.75130107],
[-0.34716124, 0.22839569, -0.75585576, 0.33319753]])
# 接下来对于这4只股票的4天数据,进行一些统计运算
# 指定行 去统计
print("前四只股票前四天的最大涨幅{}".format(np.max(temp, axis=1)))
#指定列
print("前四只股票前四天的最大涨幅{}".format(np.max(temp, axis=0)))
前四只股票前四天的最大涨幅[2.011763 1.25257476 1.23058116 0.33319753]
前四只股票前四天的最大涨幅[0.0192382 1.23058116 2.011763 1.11735188]
print("前四只股票前四天的波动程度{}".format(np.std(temp, axis=1)))
前四只股票前四天的波动程度[1.04314994 0.48568966 0.86549477 0.44208006]
# 获取股票指定哪一天的涨幅最大,
print("前四只股票前四天内涨幅最大{}".format(np.argmax(temp, axis=1)))
print("前四天一天内涨幅最大的股票{}".format(np.argmax(temp, axis=0)))
前四只股票前四天内涨幅最大[2 2 1 3]
前四天一天内涨幅最大的股票[1 2 0 1]
print("前四只股票前四天内涨幅最小{}".format(np.argmin(temp, axis=1)))
前四只股票前四天内涨幅最小[3 0 0 2]
六. 数组间的运算
arr=np.random.rand(1,3)
arr
array([[0.57502302, 0.71786717, 0.54316827]])
arr*3#每个乘3
array([[1.72506907, 2.15360151, 1.6295048 ]])
# 可以对比python列表的运算,看出区别#
a = [1, 2, 3, 4, 5]
a*3#列表加长了三倍
[1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5]
6.1 广播机制
-
执行
broadcast的前提在于,两个ndarray执行的是element-wise的运算,Broadcast机制的功能是为了方便不同形状的ndarray(numpy库的核心数据结构)进行数学运算。 -
运算要求:
(1)维度相等
(2)shape(其中相对应的一个地方为1)
#列数为1,且行数相等,或行数为一都行
arr1 = np.array([[1, 2, 3, 2, 1, 4], [5, 6, 1, 2, 3, 1]])
arr2 = np.array([[1], [3]])
arr1+arr2
array([[2, 3, 4, 3, 2, 5],
[8, 9, 4, 5, 6, 4]])
#shape要相等,不如下面维度和上面的不一样就报错
arr2 = np.array([[1], [3],[2]])
arr1+arr2
ValueError: operands could not be broadcast together with shapes (2,6) (3,1)
6.2 矩阵运算 matmul 和 dot
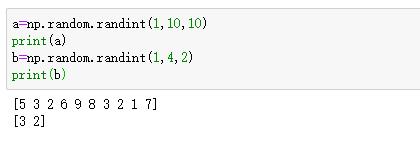
随机生成int类型的数
变换形状,具体可以看上面
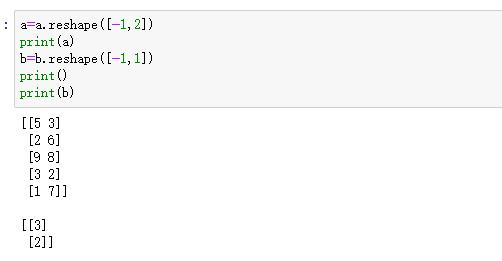
开始测试
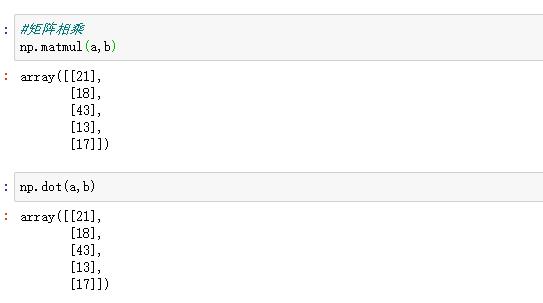
区别:np.matmul中禁止矩阵与标量的乘法。 在矢量乘矢量的內积运算中,np.matmul与np.dot没有区别。
本人csdn博客:https://blog.csdn.net/weixin_46654114
转载说明:跟我说明,务必注明来源,附带本人博客连接。
请给我点个赞鼓励我吧

以上是关于近万字的Numpy总结——边学边练的主要内容,如果未能解决你的问题,请参考以下文章