大数据Spark DataFrame
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据Spark DataFrame相关的知识,希望对你有一定的参考价值。
1 DataFrame是什么
DataFrame它不是Spark SQL提出来的,而是早期在R、Pandas语言就已经有了的。就易用性而言,对比传统的MapReduce API,说Spark的RDD API有了数量级的飞跃并不为过。然而,对于没有MapReduce和函数式编程经验的新手来说,RDD API仍然存在着一定的门槛。另一方面,数据科学家们所熟悉的R、Pandas等传统数据框架虽然提供了直观的API,却局限于单机处理,无法胜任大数据场景。为了解决这一矛盾,Spark SQL 1.3.0在原有SchemaRDD的基础上提供了与R和Pandas风格类似的DataFrame API。新的DataFrame AP不仅可以大幅度降低普通开发者的学习门槛,同时还支持Scala、Java与Python三种语言。更重要的是,由于脱胎自SchemaRDD,DataFrame天然适用于分布式大数据场景。在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame与RDD的主要区别在于,前者带有schema元信息,即DataFrame所表示的二维表
数据集的每一列都带有名称和类型。

使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行针对性的优化,最终达到大幅提升运行时效率。反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单、通用的流水线优化。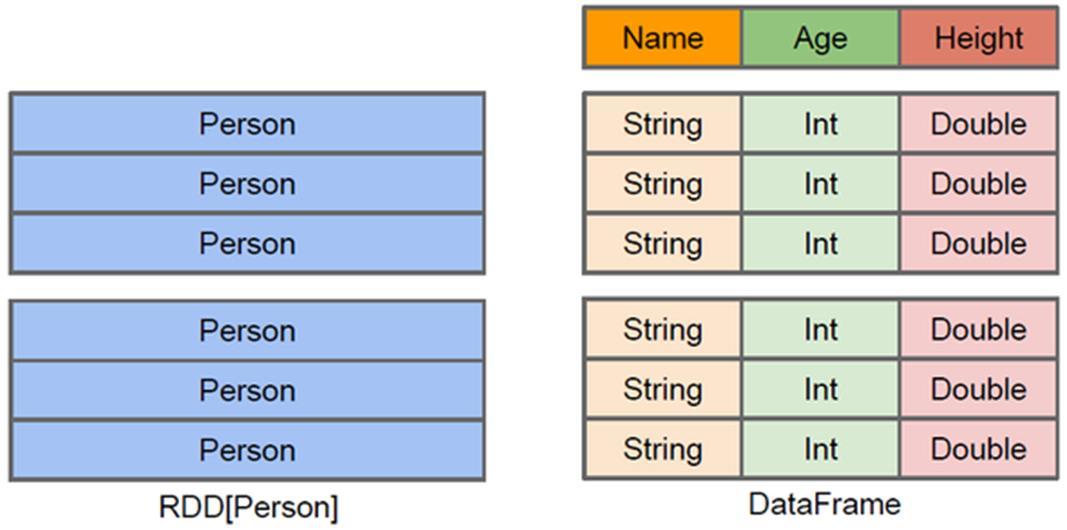
上图中左侧的RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,每列的名称和类型各是什么。了解了这些信息之后,Spark SQL的查询优化器就可以进行针对性的优化。后者由于在编译期有详尽的类型信息,编译期就可以编译出更加有针对性、更加优化的可执行代码。官方定义:
- Dataset:A DataSet is a distributed collection of data. (分布式的数据集)
- DataFrame: A DataFrame is a DataSet organized into named columns.(以列(列名,列类型,列值)的形式构成的分布式的数据集,按照列赋予不同的名称)
DataFrame有如下特性:
1)、分布式的数据集,并且以列的方式组合的,相当于具有schema的RDD;
2)、相当于关系型数据库中的表,但是底层有优化;
3)、提供了一些抽象的操作,如select、filter、aggregation、plot;
4)、它是由于R语言或者Pandas语言处理小数据集的经验应用到处理分布式大数据集上;
5)、在1.3版本之前,叫SchemaRDD;
范例演示:加载json格式数据
-
第一步、上传官方测试数据$SPARK_HOME/examples/src/main/resources至HDFS目录/datas
-
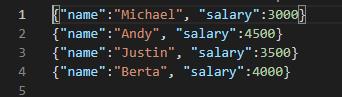
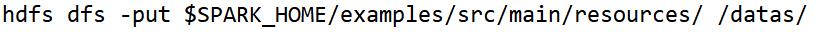
查看HDFS上数据文件,其中雇员信息数据【employees.json】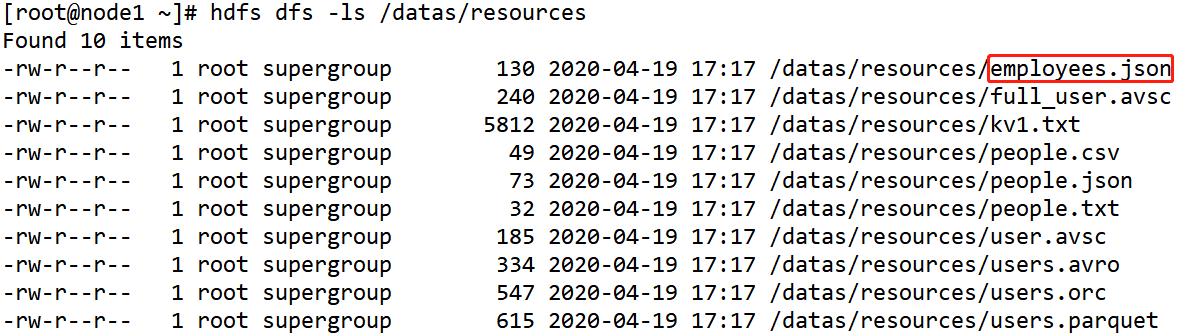
-
第二步、启动spark-shell命令行,采用本地模式localmode运行
-
第三步、读取雇员信息数据
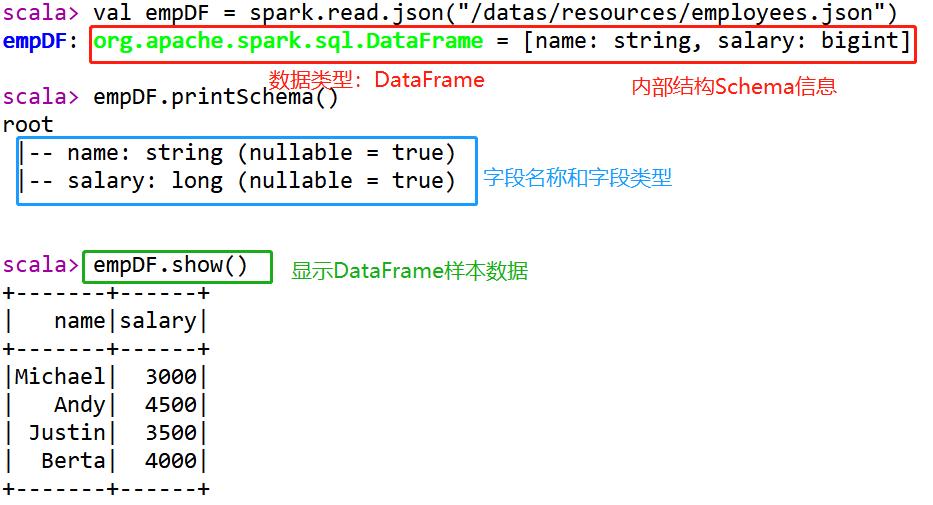
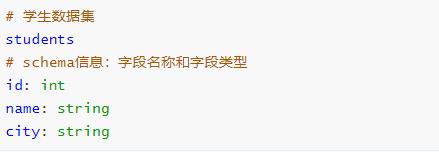
2 Schema 信息
查看DataFrame中Schema是什么,执行如下命令:
可以看出Schema信息封装在StructType中,包含很多StructField对象,查看源码。
-
其一、StructType 定义,是一个样例类,属性为StructField的数组

-
其二、StructField 定义,同样是一个样例类,有四个属性,其中字段名称和类型为必填

自定义Schema结构,官方提供实例代码:

3 Row
DataFrame中每条数据封装在Row中,Row表示每行数据,具体哪些字段位置,获取DataFrame中第一条数据。

如何构建Row对象:要么是传递value,要么传递Seq,官方实例代码:
import org.apache.spark.sql._
// Create a Row from values.
Row(value1, value2, value3, ...)
// Create a Row from a Seq of values.
Row.fromSeq(Seq(value1, value2, ...))
如何获取Row中每个字段的值呢????
- 方式一:下标获取,从0开始,类似数组下标获取

- 方式二:指定下标,知道类型

- 方式三:通过As转换类型, 此种方式开发中使用最多

4 RDD转换DataFrame
实际项目开发中,往往需要将RDD数据集转换为DataFrame,本质上就是给RDD加上Schema信息,官方提供两种方式:类型推断和自定义Schema。
官方文档: http://spark.apache.org/docs/2.4.5/sql-getting-started.html#interoperating-with-rdds

范例演示说明:使用经典数据集【电影评分数据u.data】,先读取为RDD,再转换为DataFrame。

字段信息:user id 、 item id、 rating 、 timestamp。
4.1 反射类型推断
当RDD中数据类型CaseClass样例类时,通过反射Reflecttion获取属性名称和类型,构建
Schema,应用到RDD数据集,将其转换为DataFrame。
- 第一步、定义CaseClass样例类,封装电影评分数据
/**
* 封装电影评分数据
*
* @param userId 用户ID
* @param itemId 电影ID
* @param rating 用户对电影评分
* @param timestamp 评分时间戳
*/
case class MovieRating(
userId: String,
itemId: String,
rating: Double,
timestamp: Long
)
- 第二步、SparkContext读取电影评分数据封装到RDD中,转换数据类型
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 采用反射的方式将RDD转换为DataFrame和Dataset
*/
object SparkRDDInferring {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象
val spark: SparkSession = SparkSession
.builder() // 使用建造者模式构建对象
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
.getOrCreate()
import spark.implicits._
// 读取电影评分数据u.data, 每行数据有四个字段,使用制表符分割
// user id | item id | rating | timestamp.
val rawRatingsRDD: RDD[String] = spark.sparkContext
.textFile("datas/ml-100k/u.data", minPartitions = 2)
// 转换数据
val ratingsRDD: RDD[MovieRating] = rawRatingsRDD
.filter(line => null != line && line.trim.split("\\t").length == 4)
.mapPartitions{iter =>
iter.map{line =>
// 拆箱操作, Python中常用
val Array(userId, itemId, rating, timestamp) = line.trim.split("\\t")
// 返回MovieRating实例对象
MovieRating(userId, itemId, rating.toDouble, timestamp.toLong)
}
}
// 将RDD转换为DataFrame和Dataset
val ratingsDF: DataFrame = ratingsRDD.toDF()
/*
root
|-- userId: string (nullable = true)
|-- itemId: string (nullable = true)
|-- rating: double (nullable = false)
|-- timestamp: long (nullable = false)
*/
ratingsDF.printSchema()
ratingsDF.show(10)
// 应用结束,关闭资源
spark.stop()
}
}
此种方式要求RDD数据类型必须为CaseClass,转换的DataFrame中字段名称就是CaseClass中
属性名称。
4.2 自定义Schema
依据RDD中数据自定义Schema,类型为StructType,每个字段的约束使用StructField定义,具
体步骤如下:
- 第一步、RDD中数据类型为Row:RDD[Row];
- 第二步、针对Row中数据定义Schema:StructType;
- 第三步、使用SparkSession中方法将定义的Schema应用到RDD[Row]上;
范例演示代码:
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types._
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* 自定义Schema方式转换RDD为DataFrame
*/
object SparkRDDSchema {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象
val spark: SparkSession = SparkSession
.builder() // 使用建造者模式构建对象
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
.getOrCreate()
import spark.implicits._
// 读取电影评分数据u.data, 每行数据有四个字段,使用制表符分割
// user id | item id | rating | timestamp.
val ratingsRDD: RDD[String] = spark
.sparkContext.textFile("datas/ml-100k/u.data", minPartitions = 2)
// a. RDD[Row]
val rowsRDD: RDD[Row] = ratingsRDD.mapPartitions{ iter =>
iter.map{line =>
// 拆箱操作, Python中常用
val Array(userId, itemId, rating, timestamp) = line.trim.split("\\t")
// 返回Row实例对象
Row(userId, itemId, rating.toDouble, timestamp.toLong)
}
}
// b. schema
val rowSchema: StructType = StructType(
Array(
StructField("userId", StringType, nullable = true),
StructField("itemId", StringType, nullable = true),
StructField("rating", DoubleType, nullable = true),
StructField("timestamp", LongType, nullable = true)
)
)
// c. 应用函数createDataFrame
val ratingDF: DataFrame = spark.createDataFrame(rowsRDD, rowSchema)
ratingDF.printSchema()
ratingDF.show(10, truncate = false)
// 应用结束,关闭资源
spark.stop()
}
}
此种方式可以更加体会到DataFrame = RDD[Row] + Schema组成,在实际项目开发中灵活的
选择方式将RDD转换为DataFrame。
3.5 toDF函数
除了上述两种方式将RDD转换为DataFrame以外,SparkSQL中提供一个函数:toDF,通过指
定列名称,将数据类型为元组的RDD或Seq转换为DataFrame,实际开发中也常常使用。

范例演示:将数据类型为元组的RDD或Seq直接转换为DataFrame。
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 隐式调用toDF函数,将数据类型为元组的Seq和RDD集合转换为DataFrame
*/
object SparkSQLToDF {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象,通过建造者模式创建
val spark: SparkSession = SparkSession
.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
.getOrCreate()
import spark.implicits._
// TODO: 1、构建RDD,数据类型为三元组形式
val usersRDD: RDD[(Int, String, Int)] = spark.sparkContext.parallelize(
Seq(
(10001, "zhangsan", 23),
(10002, "lisi", 22),
(10003, "wangwu", 23),
(10004, "zhaoliu", 24)
)
)
// 将RDD转换为DataFrame
val usersDF: DataFrame = usersRDD.toDF("id", "name", "age")
usersDF.printSchema()
usersDF.show(10, truncate = false)
println("========================================================")
val df: DataFrame = Seq(
(10001, "zhangsan", 23),
(10002, "lisi", 22),
(10003, "wangwu", 23),
(10004, "zhaoliu", 24)
).toDF("id", "name", "age")
df.printSchema()
df.show(10, truncate = false)
// TODO: 应用结束,关闭资源
spark.stop()
}
}
运行程序结果如下截图:

以上是关于大数据Spark DataFrame的主要内容,如果未能解决你的问题,请参考以下文章