大数据Spark Dataset
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据Spark Dataset相关的知识,希望对你有一定的参考价值。
1 Dataset 是什么
Dataset是在Spark1.6中添加的新的接口,是DataFrame API的一个扩展,是Spark最新的数据抽象,结合了RDD和DataFrame的优点。
- 与RDD相比:保存了更多的描述信息,概念上等同于关系型数据库中的二维表;
- 与DataFrame相比:保存了类型信息,是强类型的,提供了编译时类型检查,调用Dataset的方法先会生成逻辑计划,然后被Spark的优化器进行优化,最终生成物理计划,然后提交到集群中运行;
Dataset是一个强类型的特定领域的对象,这种对象可以函数式或者关系操作并行地转换。

从Spark 2.0开始,DataFrame与Dataset合并,每个Dataset也有一个被称为一个DataFrame的类型化视图,这种DataFrame是Row类型的Dataset,即Dataset[Row]。
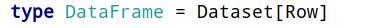
Dataset API是DataFrames的扩展,它提供了一种类型安全的,面向对象的编程接口。它是一个强类型,不可变的对象集合,映射到关系模式。在数据集的核心 API是一个称为编码器的新概念,它负责在JVM对象和表格表示之间进行转换。表格表示使用Spark内部Tungsten二进制格式存储,允许对序列化数据进行操作并提高内存利用率。Spark 1.6支持自动生成各种类型的编码器,包括基本类型(例如String,Integer,Long),Scala案例类和Java Bean。针对Dataset数据结构来说,可以简单的从如下四个要点记忆与理解:

Spark 框架从最初的数据结构RDD、到SparkSQL中针对结构化数据封装的数据结构DataFrame,最终使用Dataset数据集进行封装,发展流程如下。
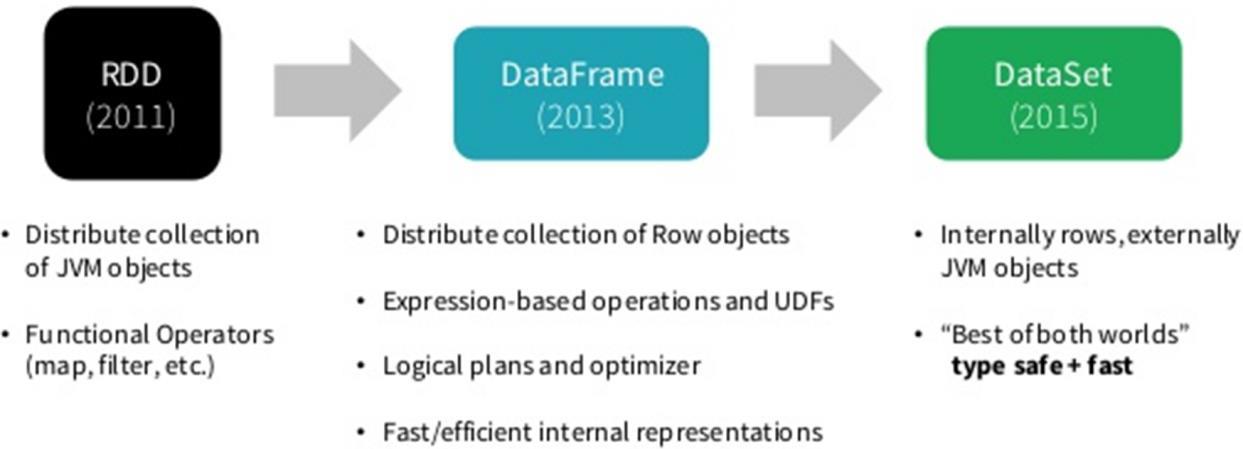
所以在实际项目中建议使用Dataset进行数据封装,数据分析性能和数据存储更加好。
2 对比DataFrame
Spark在Spark 1.3版本中引入了Dataframe,DataFrame是组织到命名列中的分布式数据集合,
但是有如下几点限制:
- 编译时类型安全:
- Dataframe API不支持编译时安全性,这限制了在结构不知道时操纵数据。
- 以下示例在编译期间有效。但是,执行此代码时将出现运行时异常。

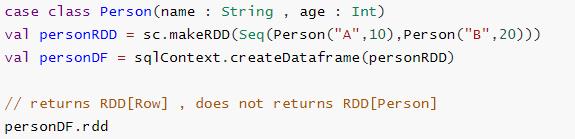
- 无法对域对象(丢失域对象)进行操作:
- 将域对象转换为DataFrame后,无法从中重新生成它;
- 下面的示例中,一旦我们从personRDD创建personDF,将不会恢复Person类的原始RDD
(RDD [Person]);
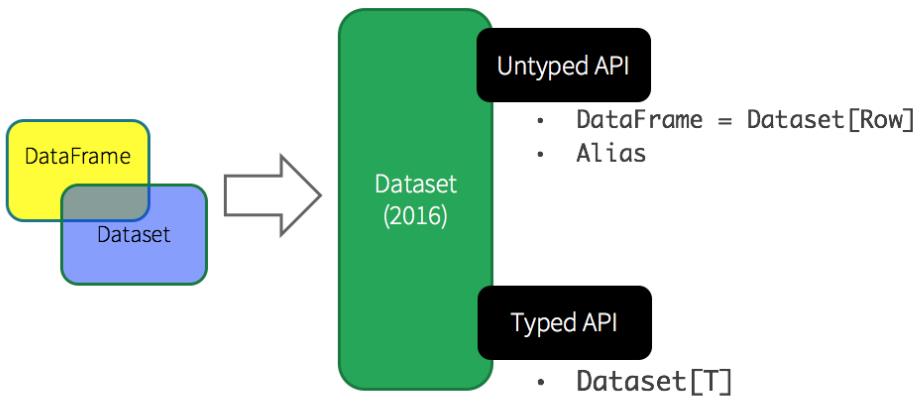
基于上述的两点,从Spark 1.6开始出现Dataset,至Spark 2.0中将DataFrame与Dataset合并,其中DataFrame为Dataset特殊类型,类型为Row。
针对RDD、DataFrame与Dataset三者编程比较来说,Dataset API无论语法错误和分析错误在编译时都能发现,然而RDD和DataFrame有的需要在运行时才能发现。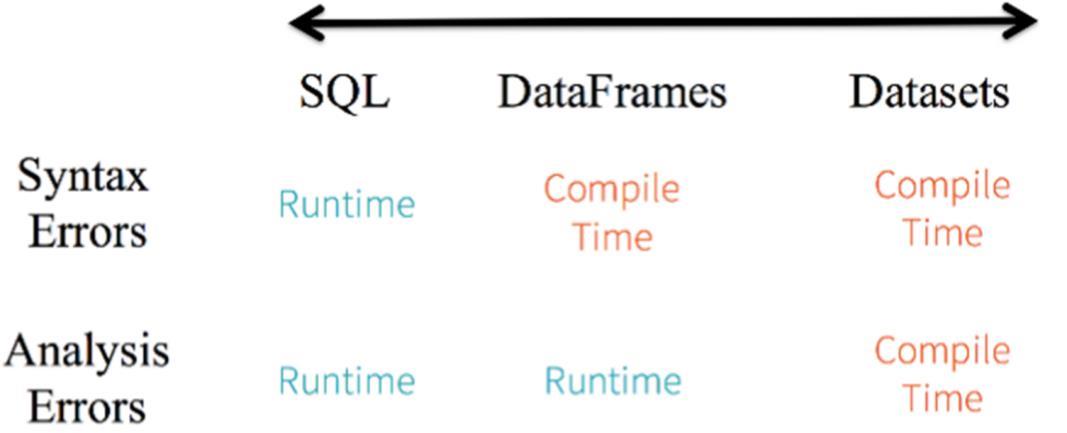
此外RDD与Dataset相比较而言,由于Dataset数据使用特殊编码,所以在存储数据时更加节省内存。
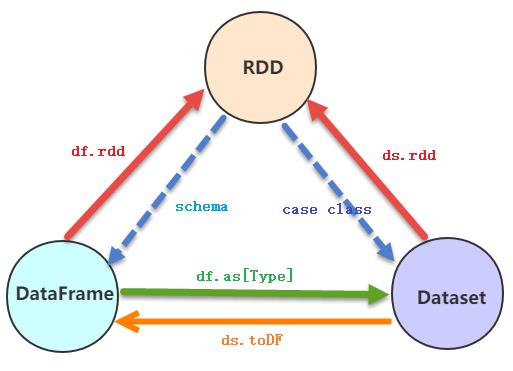
3 RDD、DF与DS转换
实际项目开发中,常常需要对RDD、DataFrame及Dataset之间相互转换,其中要点就是Schema约束结构信息。
- 1)、RDD转换DataFrame或者Dataset
- 转换DataFrame时,定义Schema信息,两种方式
- 转换为Dataset时,不仅需要Schema信息,还需要RDD数据类型为CaseClass类型
- 2)、Dataset或DataFrame转换RDD
- 由于Dataset或DataFrame底层就是RDD,所以直接调用rdd函数即可转换
- dataframe.rdd 或者dataset.rdd
- 3)、DataFrame与Dataset之间转换
- 由于DataFrame为Dataset特例,所以Dataset直接调用toDF函数转换为DataFrame
- 当将DataFrame转换为Dataset时,使用函数as[Type],指定CaseClass类型即可。
范例演示:分别读取people.txt文件数据封装到RDD、DataFrame及Dataset,查看区别及相互转换。
- 第一步、加载文件数据,封装不同数据结构
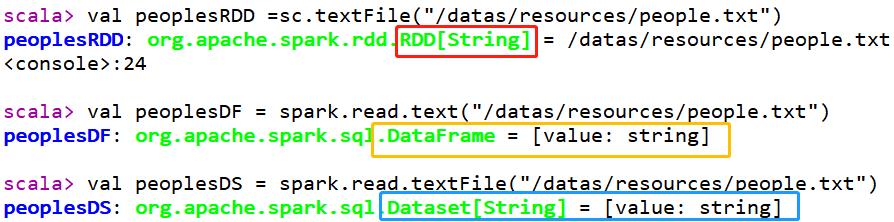
Dataset转换为RDD和DataFrame:
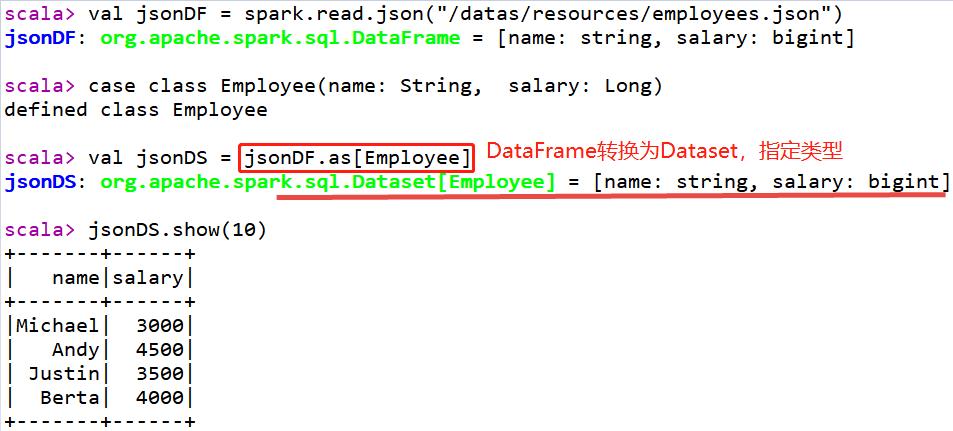
- 第二步、加载JSON数据,将DataFrame转换为Dataset
完整演示代码如下:
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
/**
* 官方案例演示Dataset是什么:
* http://spark.apache.org/docs/2.4.5/sql-getting-started.html#creating-datasets
*/
object SparkDatasetExample {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象
val spark: SparkSession = SparkSession
.builder() // 使用建造者模式构建对象
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
.getOrCreate()
import spark.implicits._
// 演示案例一:加载文本数据,分别封装到RDD、DataFrame和Dataset中
// 其一、SparkContext加载,封装RDD
val peoplesRDD: RDD[String] = spark.sparkContext
.textFile("datas/resources/people.txt")
// 其二、调用text函数,封装DataFrame
val peoplesDF: DataFrame = spark.read.text("datas/resources/people.txt")
// 其三、调用textFile函数,封装Dataset
val peoplesDS: Dataset[String] = spark.read.textFile("datas/resources/people.txt")
// DataFrame转换为RDD
peoplesDF.rdd
// Dataset转换为RDD或者DataFrame
peoplesDS.toDF()
peoplesDS.rdd
// 演示案例二:加载Json格式数据,DataFrame转换为Dataset
val jsonDF: DataFrame = spark.read.json("datas/resources/employees.json")
jsonDF.printSchema()
val jsonDS: Dataset[Employee] = jsonDF.as[Employee]
jsonDS.show(10)
// 应用结束,关闭资源
spark.stop()
}
}
4 面试题:如何理解RDD、DataFrame和Dataset
SparkSQL中常见面试题:如何理解Spark中三种数据结构RDD、DataFrame和Dataset关系?
- 第一、数据结构RDD:
- RDD(Resilient Distributed Datasets)叫做弹性分布式数据集,是Spark中最基本的数据
抽象,源码中是一个抽象类,代表一个不可变、可分区、里面的元素可并行计算的集合。 - 编译时类型安全,但是无论是集群间的通信,还是IO操作都需要对对象的结构和数据进行
序列化和反序列化,还存在较大的GC的性能开销,会频繁的创建和销毁对象。
- 第二、数据结构DataFrame:
- 与RDD类似,DataFrame是一个分布式数据容器,不过它更像数据库中的二维表格,除了
数据之外,还记录这数据的结构信息(即schema)。 - DataFrame也是懒执行的,性能上要比RDD高(主要因为执行计划得到了优化)。
- 由于DataFrame每一行的数据结构一样,且存在schema中,Spark通过schema就能读懂
数据,因此在通信和IO时只需要序列化和反序列化数据,而结构部分不用。 - Spark能够以二进制的形式序列化数据到JVM堆以外(off-heap:非堆)的内存,这些内
存直接受操作系统管理,也就不再受JVM的限制和GC的困扰了。但是DataFrame不是类
型安全的。
- 第三、数据结构Dataset:
- Dataset是DataFrame API的一个扩展,是Spark最新的数据抽象,结合了RDD和DataFrame
的优点。 - DataFrame=Dataset[Row](Row表示表结构信息的类型),DataFrame只知道字段,但
是不知道字段类型,而Dataset是强类型的,不仅仅知道字段,而且知道字段类型。 - 样例类CaseClass被用来在Dataset中定义数据的结构信息,样例类中的每个属性名称直接
对应到Dataset中的字段名称。 - Dataset具有类型安全检查,也具有DataFrame的查询优化特性,还支持编解码器,当需
要访问非堆上的数据时可以避免反序列化整个对象,提高了效率。
RDD、DataFrame和DataSet之间的转换如下,假设有个样例类: case class Emp(name: String), 相互转换
RDD转换到DataFrame:rdd.toDF(“name”)
RDD转换到Dataset:rdd.map(x => Emp(x)).toDS
DataFrame转换到Dataset:df.as[Emp]
DataFrame转换到RDD:df.rdd
Dataset转换到DataFrame:ds.toDF
Dataset转换到RDD:ds.rdd
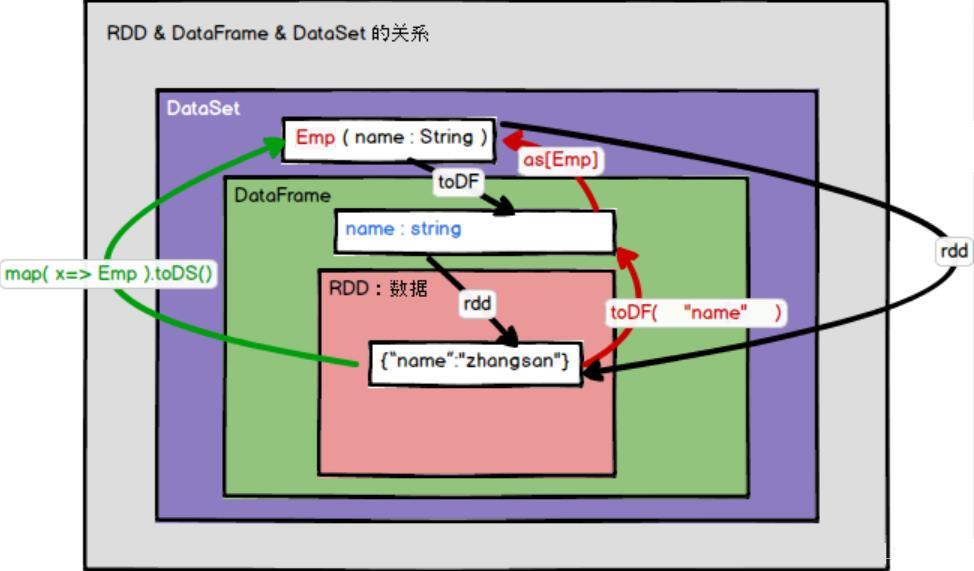
RDD与DataFrame或者DataSet进行操作,都需要引入隐式转换import spark.implicits._,其中的spark是SparkSession对象的名称!
以上是关于大数据Spark Dataset的主要内容,如果未能解决你的问题,请参考以下文章