LeetCode-Mysql练习1(175/176/177/178/184/185)(排名函数)
Posted Zephyr丶J
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LeetCode-Mysql练习1(175/176/177/178/184/185)(排名函数)相关的知识,希望对你有一定的参考价值。
mysql练习
昨天笔试除了个mysql,忘了咋写了,每天来练一道巩固一下
175. 组合两个表
题目描述
表1: Person
+-------------+---------+
| 列名 | 类型 |
+-------------+---------+
| PersonId | int |
| FirstName | varchar |
| LastName | varchar |
+-------------+---------+
PersonId 是上表主键
表2: Address
+-------------+---------+
| 列名 | 类型 |
+-------------+---------+
| AddressId | int |
| PersonId | int |
| City | varchar |
| State | varchar |
+-------------+---------+
AddressId 是上表主键
编写一个 SQL 查询,满足条件:无论 person 是否有地址信息,都需要基于上述两表提供 person 的以下信息:
FirstName, LastName, City, State
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/combine-two-tables
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
思路
select p.FirstName, p.LastName, a.City, a.State
from Person p
left join Address a
on p.PersonId = a.PersonId;
176. 第二高的薪水
题目描述
编写一个 SQL 查询,获取 Employee 表中第二高的薪水(Salary) 。
+----+--------+
| Id | Salary |
+----+--------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+----+--------+
例如上述 Employee 表,SQL查询应该返回 200 作为第二高的薪水。如果不存在第二高的薪水,那么查询应返回 null。
+---------------------+
| SecondHighestSalary |
+---------------------+
| 200 |
+---------------------+
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/second-highest-salary
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
思路
按薪资降序,然后限制返回第一行开始第一条记录,但是可能出现null
distinct是去除重复的
注意:limit x offset y 跳过前y条返回x条
limit x,y 从第x行开始,返回y条记录
两个不一样
select distinct Salary SecondHighestSalary
from Employee
order by Salary desc
limit 1 offset 1;
处理为null的情况,变成子查询可以
select
(select distinct Salary
from Employee
order by Salary desc
limit 1 offset 1) SecondHighestSalary;
或者用ifnull
ifnull(a,b)函数解释:
如果value1不是空,结果返回a
如果value1是空,结果返回b
SELECT
IFNULL(
(SELECT DISTINCT Salary
FROM Employee
ORDER BY Salary DESC
LIMIT 1,1), NULL) AS SecondHighestSalary
也可以先找最大的,然后再比最大的小的里面找最大的,就是第二大的
select max(distinct Salary) SecondHighestSalary
from Employee
where Salary <
(select max(distinct Salary)
from Employee);
177. 第N高的薪水
题目描述
编写一个 SQL 查询,获取 Employee 表中第 n 高的薪水(Salary)。
+----+--------+
| Id | Salary |
+----+--------+
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
+----+--------+
例如上述 Employee 表,n = 2 时,应返回第二高的薪水 200。如果不存在第 n 高的薪水,那么查询应返回 null。
+------------------------+
| getNthHighestSalary(2) |
+------------------------+
| 200 |
+------------------------+
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/nth-highest-salary
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
思路
和刚刚一样,只不过这次变成了变量
这里注意limt里面不能运算,所有需要先set,这个是mysql里面函数的问题,应该不会考察
排名第N高意味着要跳过N-1个薪水,由于无法直接用limit N-1,所以需先在函数开头处理N为N=N-1。
注:这里不能直接用limit N-1是因为limit和offset字段后面只接受正整数(意味着0、负数、小数都不行)或者单一变量(意味着不能用表达式),也就是说想取一条,limit 2-1、limit 1.1这类的写法都是报错的。
这里没有加null的处理也通过了,说明函数会直接处理null的情况
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
set N := N - 1;
RETURN (
# Write your MySQL query statement below.
select distinct Salary
from Employee
order by Salary desc
limit N, 1
);
END
178. 分数排名
题目描述
编写一个 SQL 查询来实现分数排名。
如果两个分数相同,则两个分数排名(Rank)相同。请注意,平分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”。
+----+-------+
| Id | Score |
+----+-------+
| 1 | 3.50 |
| 2 | 3.65 |
| 3 | 4.00 |
| 4 | 3.85 |
| 5 | 4.00 |
| 6 | 3.65 |
+----+-------+
例如,根据上述给定的 Scores 表,你的查询应该返回(按分数从高到低排列):
+-------+------+
| Score | Rank |
+-------+------+
| 4.00 | 1 |
| 4.00 | 1 |
| 3.85 | 2 |
| 3.65 | 3 |
| 3.65 | 3 |
| 3.50 | 4 |
+-------+------+
重要提示:对于 MySQL 解决方案,如果要转义用作列名的保留字,可以在关键字之前和之后使用撇号。例如 `Rank`
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/rank-scores
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
思路
先学排名函数:
首先给出数据:
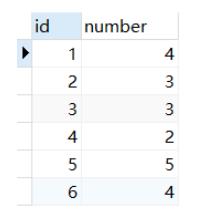
1.row_number():是序号 连续 不重复,即使遇到表中的两个一样的数值亦是如此
select *,row_number() OVER(order by number ) as row_num
from num
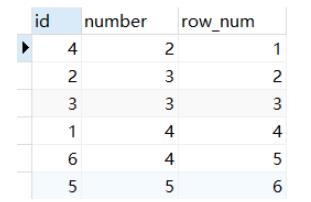
2.rank() 函数会把要求排序的值相同的归为一组且每组序号一样,排序不会连续执行
select *,rank() OVER(order by number ) as row_num
from num
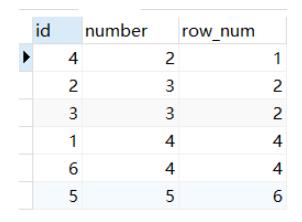
3.dense_rank():排序是连续的,也会把相同的值分为一组且每组排序号一样
select *,dense_rank() OVER(order by number ) as row_num
from num
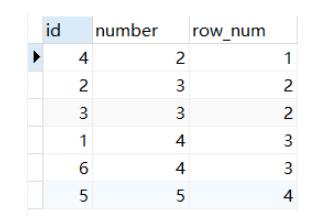
4.ntile() Ntile(group_num) 将所有记录分成group_num个组,每组序号一样
select *,ntile(2) OVER(order by number ) as row_num
from num
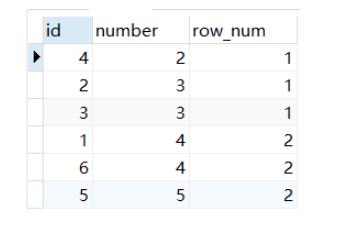
所以这里用dense_rank():
select Score, dense_rank() over(order by score desc) as `Rank` from Scores;
再看个不用排名函数写的:
# 查询每个分数比多少个分数小,就是自己的排名,太秒了;这里主要是用到了自联,思路很好
select a.Score as Score,
(select count(distinct b.Score) from Scores b where b.Score >= a.Score) as `Rank`
from Scores a
order by Score desc;
184. 部门工资最高的员工
题目描述
Employee 表包含所有员工信息,每个员工有其对应的 Id, salary 和 department Id。
+----+-------+--------+--------------+
| Id | Name | Salary | DepartmentId |
+----+-------+--------+--------------+
| 1 | Joe | 70000 | 1 |
| 2 | Jim | 90000 | 1 |
| 3 | Henry | 80000 | 2 |
| 4 | Sam | 60000 | 2 |
| 5 | Max | 90000 | 1 |
+----+-------+--------+--------------+
Department 表包含公司所有部门的信息。
+----+----------+
| Id | Name |
+----+----------+
| 1 | IT |
| 2 | Sales |
+----+----------+
编写一个 SQL 查询,找出每个部门工资最高的员工。对于上述表,您的 SQL 查询应返回以下行(行的顺序无关紧要)。
+------------+----------+--------+
| Department | Employee | Salary |
+------------+----------+--------+
| IT | Max | 90000 |
| IT | Jim | 90000 |
| Sales | Henry | 80000 |
+------------+----------+--------+
解释:
Max 和 Jim 在 IT 部门的工资都是最高的,Henry 在销售部的工资最高。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/department-highest-salary
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
思路
虽然已经很久不做了,但是还是能勉强写出来
先找到每个部门最高的工资,作为子表
然后再找工资和最高工资相同,且部门相同的人,然后连接上部门表(不能外连接,因为部门表可能为null)
select d.Name as Department, ee.Name as Employee, ee.Salary as Salary
from Employee ee
join
(select e.DepartmentId as Did, max(e.Salary) as Sal
from Employee e
group by e.DepartmentId) as e2
on ee.DepartmentId = e2.Did and ee.Salary = e2.Sal
join Department d
on ee.DepartmentId = d.Id;
看了下官解,差不多,用的是in,没想到in还可以联合查询
select d.Name as Department, e.Name as Employee, Salary
from Employee e
join Department d
on e.DepartmentId = d.Id
where (e.DepartmentId, e.Salary) in
(select ee.DepartmentId, max(ee.Salary) from Employee ee group by ee.DepartmentId);
185. 部门工资前三高的所有员工
题目描述
Employee 表包含所有员工信息,每个员工有其对应的工号 Id,姓名 Name,工资 Salary 和部门编号 DepartmentId 。
+----+-------+--------+--------------+
| Id | Name | Salary | DepartmentId |
+----+-------+--------+--------------+
| 1 | Joe | 85000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
| 5 | Janet | 69000 | 1 |
| 6 | Randy | 85000 | 1 |
| 7 | Will | 70000 | 1 |
+----+-------+--------+--------------+
Department 表包含公司所有部门的信息。
+----+----------+
| Id | Name |
+----+----------+
| 1 | IT |
| 2 | Sales |
+----+----------+
编写一个 SQL 查询,找出每个部门获得前三高工资的所有员工。例如,根据上述给定的表,查询结果应返回:
+------------+----------+--------+
| Department | Employee | Salary |
+------------+----------+--------+
| IT | Max | 90000 |
| IT | Randy | 85000 |
| IT | Joe | 85000 |
| IT | Will | 70000 |
| Sales | Henry | 80000 |
| Sales | Sam | 60000 |
+------------+----------+--------+
解释:
IT 部门中,Max 获得了最高的工资,Randy 和 Joe 都拿到了第二高的工资,Will 的工资排第三。销售部门(Sales)只有两名员工,Henry 的工资最高,Sam 的工资排第二。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/department-top-three-salaries
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
思路
首先要求出每个部门前3高的薪水
很容易就想到了分组,和上一个题一样,但是写就会发现,因为没有一个函数可以和找出最大值一样直接找出前三的值,所以不行
然后去看了答案,发现是用这样一种方式:
select e1.Name as 'Employee', e1.Salary
from Employee e1
where 3 >
(
select count(distinct e2.Salary)
from Employee e2
where e2.Salary > e1.Salary
);
这个很难理解:

最后,能满足这个条件的,就是当e1.Salary = 6 7 8 的时候
# 公司里前 3 高的薪水意味着有不超过 3 个工资比这些值大。
select d.Name as Department, e1.Name as Employee, e1.Salary
from Employee e1
join Department d
on e1.DepartmentId = d.Id
where 3 >
(select count(distinct e2.Salary)
from Employee e2
where e1.Salary < e2.Salary and e1.DepartmentId = e2.DepartmentId);
以上是关于LeetCode-Mysql练习1(175/176/177/178/184/185)(排名函数)的主要内容,如果未能解决你的问题,请参考以下文章