大数据之kafka简介
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据之kafka简介相关的知识,希望对你有一定的参考价值。
🌟已经2个星期没写博客啦,今天接上,我们今天来介绍大数据实时同步中一个非常重要的部分——消息队列kafka,在实时处理领域,kafka可谓是出名至极,在介绍它之前,我们先来介绍一些基础知识。来看看我们今天需要学习的内容👇:
1.分布式的用户
在计算机网络中,我们都知道,每一台机器都有自己的ip地址,而IP地址也是我们找到服务器的依据,由于IP地址过于难记,我们就有了域名(www.baidu.com),将IP地址与域名一一对应,通过域名解析,即可找到合适的服务器,可是一台服务器上的服务有很多,我们到底是访问哪个服务呢,我们就需要在IP地址后面加上服务的端口号(127.127.0.1:80),有些时候是不需要填写端口号,因为有默认端口号80。
1.1 分布式用户初级

如上图所示:我们说一下分布式的发展吧!
- 最开始的服务是用户直接和服务器相连,随着用户增多我们需要增加服务器数量,可是服务器一增加,端口号就不一样,我们就不知道访问哪一台服务器。
- 于是出现了负载均衡器,使用户间接和服务器进行交流,通过负载均衡器来调度用户连接哪台服务器。
- 问题又出现了,用户与服务器之间的数据存储出现问题,用户第一次访问第一台服务器存储了数据,第二次访问第二台服务器时,数据不存在,于是,人们就将数据这一部分单独拿出来,做成了一个缓存服务器,用来和服务器进行连接,这样数据存储在公共的缓存服务器上就可以随时提供给任何一台服务器使用。这样就使性能得到了提高。
1.2 分布式用户中级
不知道大家有没有发现分布式初级的缺点——负载均衡器的工作负担太重,用户过多容易出现问题。

如上图,我们发现了一种新的架构:我解释一下。
- 主要变化的地方就是将负载均衡器换成了注册中心,以前是负载均衡器来调度,现在注册中心只负责传输服务器的端口号,不进行调度。
- 返回端口号给用户后,用户通过自己的主机进行调度,你的机器快,你就快,这样子就解决了负载均衡器的压力,然后用户再去访问服务器。
- zookeeper就是这样一个原理。
2.分布式的系统
最原始的系统就是下图的样子,一个服务中有多个功能系统,原始的系统中多个功能在一个服务器上,这样当多个用户访问一个功能时,占据的资源会使得另外的功能组件运行缓慢。

于是就有了下图的版本,将不同功能的系统放在不同服务上,这样的话,当多个用户访问一个服务时,该服务占据的计算机资源会影响到另外的服务。(也不太好)

有人会说,那就将不同的系统放在不同的主机服务上,每个系统都属于不同主机的服务,当有多人访问一个系统时,有会出现一个问题,它们使用的是一个网络,多人访问一个系统时,同一个网络中的其他服务就会变慢。
于是又有同学说,把它们放在不同的网络,不同的主机,不同的服务上,问题又来了,订单系统和送货系统是需要数据交互的,你把它们分的这么开,系统功能之间的交互就会出现困难。
经过多种的尝试,于是有了最终的形式:
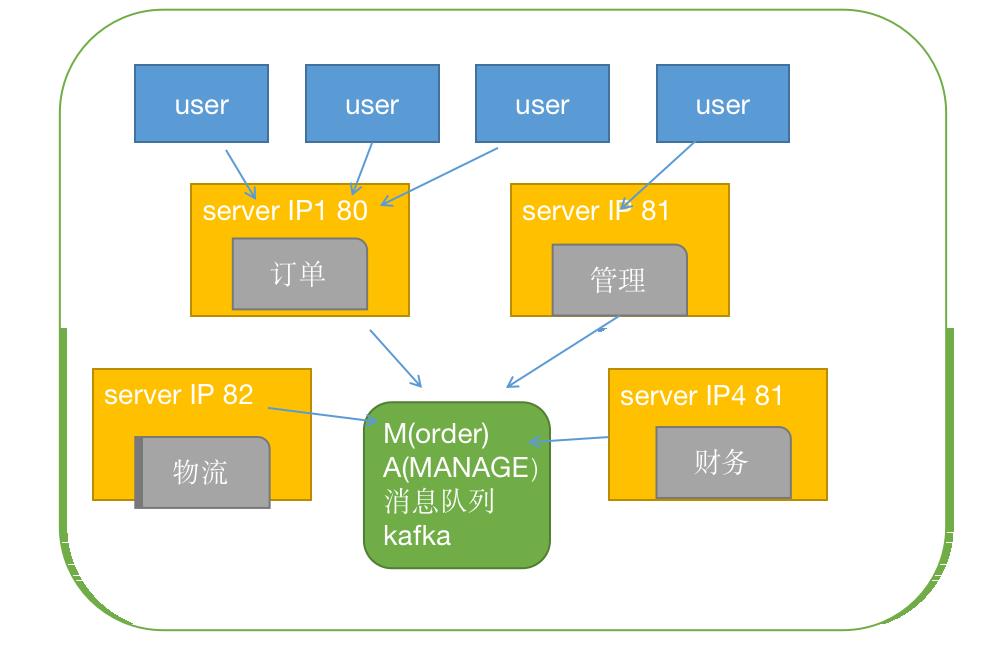
最终的形式如上图所示:我们来解释一下:
- 各服务可以在一台主机上,也可以在不同主机上,可以在同一网络中,也可以在不同网络中。
- 数据的交互不再是单个系统之间两两交互,而是统一存储在一个消息队列中,这个消息队列可以将各个系统的数据存储起来并给每条数据一个标记。
- 各个系统需要数据时从消息队列中进行获取,根据标记选择自己需要的数据进行拉取即可。
3. flume的缺陷
Flume 是一个从可以收集例如日志,事件等数据资源,并将这些数量庞大的数据从各项数据资源中集中起来存储的工具/服务,或者数集中机制。flume具有高可用,分布式,配置工具,其设计的原理也是基于将数据流,如日志数据从各种网站服务器上汇集起来存储到HDFS,HBase等集中存储器中。
缺陷:
- 数据都保存在内存中,数据容易丢失。
- 增加消费者不容易。
- 数据无法长时间保存。
感兴趣的同学可以查看这篇博客: Flume概念与原理、与Kafka优势对比.
4. kafka架构
4.1 消息队列
下图是消息队列的原理图:
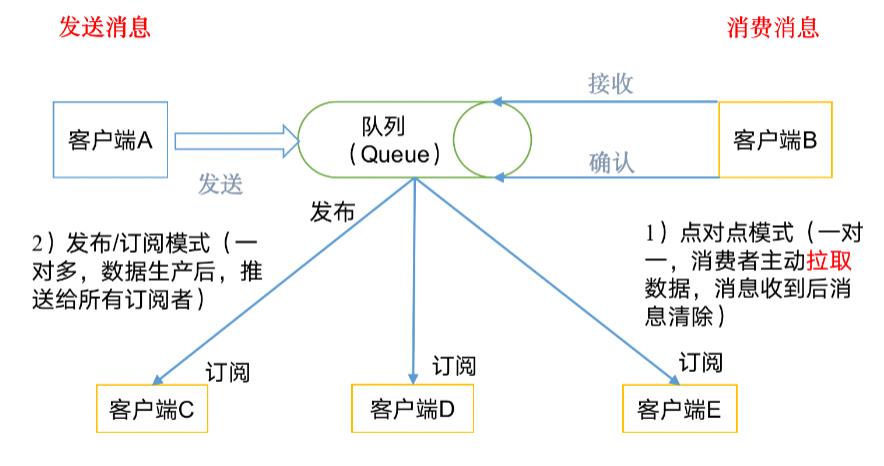
主要有两种模式:
- 点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
- 发布/订阅模式(一对多,数据生产后,推送给所有订阅者)
4.2 kafka
下图是kafka的结构图:

- producer:就是消息的生产者,向kafka broker发消息的客户端。
- consumer:消息消费者,向kafka broker取消息的客户端。
- topic:可以理解为一个队列(有主题的队列)。
- consumer group(CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。
- broker:一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic
- partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
- offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka。
5.总结
- 流式处理:比如spark streaming和storm
- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
- 消息系统:解耦和生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作
以上是关于大数据之kafka简介的主要内容,如果未能解决你的问题,请参考以下文章