[保姆级万字教程]打造最迷人的S曲线----带你从零手撕基于Huffman编码的文件压缩项目
Posted 程序猿是小贺
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[保姆级万字教程]打造最迷人的S曲线----带你从零手撕基于Huffman编码的文件压缩项目相关的知识,希望对你有一定的参考价值。
基于Huffman编码的文件压缩
- 开发环境:Windows
- 使用工具:VS2013,查看并且对比两个二进制文件 Ultra Edit
- 语言:C++
- 技术栈:Huffman树,堆排序,文件操作
- 项目源码:源码点这里!
作者的碎碎念:本篇文章的宗旨在于可以帮助大家从0开始手撕一个属于自己的项目,建议大家在学习之前可以花一分钟时间阅读一下目录,熟悉一下开发流程,以便于接下来更好地理解 ,废话不必多说直接进入正题。
1.文件压缩

1.1 什么是文件压缩?
文件压缩是指在不丢失有用信息的前提下,缩减数据量以减少存储空间,提高其传输、存储和处理效率,或按照一定的算法对文件中数据进行重新组织,减少数据的冗余和存储的空间的一种技术方法。
1.2 为什么需要压缩
1.紧缩数据存储容量,减少存储空间
2. 可以提高数据传输的速度,减少带宽占用量,提高通讯效率
3. 对数据的一种加密保护,增强数据在传输过程中的安全性
1.3 压缩的分类
有损压缩
有损压缩是利用了人类对图像或声波中的某些频率成分不敏感的特性,允许压缩过程中损失一定的信息;虽然不能完全恢复原始数据,但是所损失的部分对理解原始图像的影响缩小,却换来了大得多的压缩比,即指使用压缩后的数据进行重构,重构后的数据与原来的数据有所不同,但不影响人对原始资料表达的信息造成误解。
无损压缩
对文件中数据按照特定的编码格式进行重新组织,压缩后的压缩文件可以被还原成与源文件完全相同的格式,不会影响文件内容,对于数码图像而言,不会使图像细节有任何损失。
- 压缩的本质:让文件占用的空间小一点
1.4 压缩方法
- 专有名词采用的固定短语
比如:北京大学,简称北大,就可以提到压缩的目的,但只能针对于大家所熟知的专有名词。 - 缩短文件中重复的数据
比如文件中存放数据为:mnoabczxyuvwabc123456abczxydefgh,对文件中重复数据使用(距离,长度)对进行替换,压缩之后的结果为:mnoabczxyuvw(9,3)123456(18, 6)defgh - 给文件中每个字节找一个更短的编码
比如文件中存放数据为:ABBBCCCCCDDDDDDD
| 字符 | 静态等长编码 | 动态不等长编码 |
|---|---|---|
| A | 00 | 100 |
| B | 01 | 101 |
| C | 10 | 11 |
| D | 11 | 0 |
采用静态等长编码压缩: 00010101 10101010 10000000 00000000
采用动态不等长编码压缩:10010110 11011111 11111100 00000000
源文件16个字节,压缩完成之后占4个字节,可以起到压缩的目的。
2. huffman编码的文件压缩
2.1 构建Huffman树
2.1.1 哈夫曼树,也称最优树。
给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
2.1.2 哈夫曼树的构建
假设有n个权值,则构造出的哈夫曼树有n个叶子结点。 n个权值分别设为 w1、w2、…、wn,则哈夫曼树的构造规则为:
(1) 将w1、w2、…,wn看成是有n 棵树的森林(每棵树仅有一个结点);
(2) 在森林中选出两个根结点的权值最小的树合并,作为一棵新树的左、右子树,且新树的根结点权值为其左、右子树根结点权值之和;
(3)从森林中删除选取的两棵树,并将新树加入森林;
(4)重复(2)、(3)步,直到森林中只剩一棵树为止,该树即为所求得的哈夫曼树。
- 构建Huffman树
//自定义比较规则
template <class H>
struct Com
{
typedef HuffmanTreeNode<H> Node; //别名
//自己实现比较方式,默认比较方式是按照地址来比
//使用仿函数来按照权值进行比较
bool operator()(const Node* left, const Node* right)
{
return left->weight > right->weight;
}
};
//创建哈夫曼树
void CreateHTree(const H arr[], size_t size,const H& invalid)
{
//要用小堆,但是优先级队列默认大堆方式,所以要修改其比较规则为大于
std::priority_queue<Node*,vector<Node*>,Com<H>> q;
//1.使用权值创建只有根节点的二叉树森林
for (size_t i = 0; i < size; ++i)
{
if (arr[i]!=invalid)
q.push(new Node(arr[i]));
}
//2.循环,直到二叉树森林中只剩一棵二叉树为止
while (q.size()>1)
{
//从二叉树森林中取权值最小的两棵二叉树
Node* left = q.top();
q.pop();
Node* right = q.top();
q.pop();
//将left和right作为新节点的左右子树构造二叉树
//并且新二叉树的权值为左右子树的权值和
Node* parent = new Node(left->weight + right->weight);
parent->left = left;
parent->right = right;
left->parent = parent;
right->parent = parent;
//将新生成的二叉树插入二叉树森林
q.push(parent);
}
root = q.top();
}
2.2 获取Huffman编码
获取编码的实质就是对二叉树进行遍历,获取的方式有很多,我接下来采用的是在走到叶子节点的位置之后 再进行获取,把获取到的编码保存下来,当然我们也可以在遍历过程中进行获取
编码方式如下:

1.以字符串中每个字符出现的总次数为权值构建huffman树
2.令huffman树中左分支用0代替,右分支用1代替
3.所有权值节点都在叶子位置,遍历每条到叶子节点的路径获取字符的编码
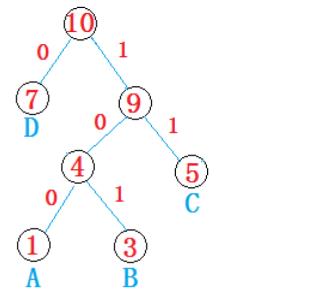

2.3 压缩
我们首先需要明白的是,文件在磁盘上是以字节方式进行存储的。
2.3.1 获取源文件中每个字节出现的频次信息
2.3.2 根据获取到的频次信息构建Huffman树
2.3.3 通过Huffman树获取每个字节对应的编码
//遍历Huffman树获取编码,递归获取
void FileCompress::GetHuffmanCode(HuffmanTreeNode<ByteInfo>* root)
{
if (nullptr == root)
{
return;
}
//huffman树中所有有效的权值都在叶子节点的位置
//当遍历到叶子节点时,即为该权值对应的编码
if (root->left == nullptr &&root->right == nullptr)
{
HuffmanTreeNode<ByteInfo>* cur = root;
HuffmanTreeNode<ByteInfo>* parent = cur->parent;
string& strCode = fileByteInfo[cur->weight.ch].strCode;
while (parent)
{
if (cur == parent->left)
strCode+= '0';
else
strCode+= '1';
cur = parent;
parent = cur->parent;
}
reverse(strCode.begin(), strCode.end());
}
GetHuffmanCode(root->left);
GetHuffmanCode(root->right);
}
2.3.4 写解压缩时需要用到的信息
4.1获取源文件后缀
4.2构建字节频次信息,统计有效字符总行数
4.3写入信息
void FileCompress::WriteHead(FILE* fOut, const string& filePath)
{
//1.获取源文件后缀
string postFix = filePath.substr(filePath.rfind('.'));
postFix += "\\n";
::fwrite(postFix.c_str(), 1, postFix.size(), fOut);
//2.构造字节的频次信息并且统计有效字节总行数
string chAppearCount="";
size_t lineCount = 0;
for (size_t i = 0; i < 256; ++i)
{
if (fileByteInfo[i].appearCount > 0)
{
chAppearCount += fileByteInfo[i].ch;//字符
chAppearCount += ':';//用冒号隔开
chAppearCount += to_string(fileByteInfo[i].appearCount); //次数
chAppearCount += "\\n";
lineCount++;
}
}
//3.写总行数与频次信息
string totalLine = to_string(lineCount); //总行数
totalLine += "\\n";
::fwrite(totalLine.c_str(), 1, totalLine.size(), fOut);
::fwrite(chAppearCount.c_str(), 1, chAppearCount.size(), fOut);
}
2.3.5 使用字节编码重新改写源文件
此时因为之前获取文件时,文件指针已经指向了文件的末尾,所以在此需要将文件指针恢复,重新指向文件起始位置
- 源码展示
bool FileCompress::CompressFile(const string& filePath) //压缩
{
// 1.统计源文件中每个字节出现的次数并保存
FILE* pf = fopen(filePath.c_str(), "rb");
if (pf == nullptr)
{
cout << "打开待压缩文件失败!" << endl;
return false;
}
//此时还不知道文件大小,则需要循环读取,出口条件即为读到文件末尾
uchar readBuff[1024];
while (true)
{
//最多一次性读取1024字节,实际读取rdsize字节
size_t rdsize = fread(readBuff,1,1024,pf); //读取
if (rdsize == 0)
{
//读取到文件末尾
break;
}
//统计
for (size_t i = 0; i < rdsize; i++)
{
//利用哈希中的直接定制法---以字符的ASCII值作为数组的下标进行统计
fileByteInfo[readBuff[i]].appearCount++;
}
}
///
// 2.根据统计的结果创建huffman树
// 注意:在创建huffman树时,需要将出现次数为0的字节删除
HuffmanTree<ByteInfo> ht;
ByteInfo invalid;
ht.CreateHTree(fileByteInfo, 256, invalid);
//3.借助huffman树获取每个字节的编码
GetHuffmanCode(ht.GetRoot());
/
// 4. 写入解压缩时需要使用的信息
FILE* fOut = fopen("2.hxd", "wb"); //将压缩结果写入2.hxd
WriteHead(fOut, filePath);
//5.使用字节编码重新改写源文件
//注意:统计文件中字节出现的次数时文件指针已经指向末尾
//fseek(pf,0,SEEK_SET);
rewind(pf); //让文件指针指向起始位置
//FILE* fOut = fopen("2.hxd", "w"); //将压缩结果写入2.hxd
uchar ch = 0;
uchar bitCount = 0;
while (true)
{
size_t rdsize = fread(readBuff, 1, 1024, pf);
if (rdsize == 0)
break;
//用编码改写这些字节--改写的结果需要放在压缩结果文件中
for (size_t i = 0; i < rdsize; i++)
{
//
string& strCode = fileByteInfo[readBuff[i]].strCode;
//将字符串格式的二进制编码往字节中存放
for (size_t j = 0; j < strCode.size(); j++)
{
ch <<= 1; //高位丢弃,低位补0
if ('1' == strCode[j])
ch |= 1;
//当ch中的8个比特位填充满则将该字节写入压缩文件
bitCount++;
if (bitCount == 8)
{
fputc(ch, fOut);
bitCount = 0;
}
}
}
}
//ch最后一次要是不够8比特位,实际是没有写进去的
if (bitCount>0 &&bitCount < 8)
{
ch <<= (8 - bitCount);
fputc(ch, fOut);
}
fclose(pf);
fclose(fOut);
return true;
}
2.4 解压缩
方法一:可以逐比特位获取,然后进行查表比对,如果表中存在则解压缩,不存在则获取下一个比特位继续进行比对。
弊端:要不断地进行查找,效率低
**方法二:**使用Huffman树进行解压缩
2.4.1 从压缩文件中获取源文件的后缀
// 读取源文件后缀
string postFix;
GetLine(fIn, postFix);
string strContent;
GetLine(fIn, strContent);
size_t lineCount = atoi(strContent.c_str());
strContent = "";
2.4.2 从压缩文件中获取字符次数的总行数
//按行获取文件
void FileCompress::GetLine(FILE* fIn, string& strContent)
{
uchar ch;
while (!feof(fIn))
{
ch = fgetc(fIn);
if (ch == '\\n')
break;
strContent += ch;
}
}
2.4.3 获取每个字符出现的次数
//循环读取lineCount行,获取字节的频次信息
for (size_t i = 0; i < lineCount; i++)
{
GetLine(fIn, strContent);
if ("" == strContent)
{
//说明刚读取到的为\\n
strContent += "\\n";
GetLine(fIn, strContent);
}
//fileByteInfo[strContent[0]].ch = strContent[0];
fileByteInfo[(uchar)strContent[0]].appearCount = atoi(strContent.c_str() + 2);
strContent = "";
}
2.4.4 重建huffman树
//2.恢复Huffman树
HuffmanTree<ByteInfo> ht;
ByteInfo invalid;
ht.CreateHTree(fileByteInfo, 256, invalid);
2.4.5 解压压缩数据
a. 从压缩文件中读取一个字节的获取压缩数据ch
b. 从根节点开始,按照ch的8个比特位信息从高到低遍历huffman树:
- 该比特位是0,取当前节点的左孩子,否则取右孩子,直到遍历到叶子节点位置,该字符就被解析成功
- 将解压出的字符写入文件
- 如果在遍历huffman过程中,8个比特位已经比较完毕还没有到达叶子节点,从a开始执行
c. 重复以上过程,直到所有的数据解析完毕。
//3.读取压缩数据并结合Huffman树进行解压缩
string filename("3");
filename += postFix;
FILE* fOut = fopen(filename.c_str(), "wb");
uchar readBuff[1024];
uchar bitCount = 0;
HuffmanTreeNode<ByteInfo>* cur = ht.GetRoot();
const int fileSize = cur->weight.appearCount;// 源文件字节数大小
int compressSize = 0; //解压缩字节数大小
while (true)
{
size_t rdsize = fread(readBuff, 1, 1024, fIn);
if (0 == rdsize)
{
break;
}
for (size_t i = 0; i < rdsize; ++i)
{
uchar ch = readBuff[i];
bitCount = 0;
while (bitCount < 8)
{
if (ch & 0x80)
cur = cur->right;
else
cur = cur->left;
if (cur->left == nullptr && cur->right == nullptr)
{
fputc(cur->weight.ch, fOut);
cur = ht.GetRoot();
compressSize++;
if (compressSize == fileSize)
{
break;
}
}
bitCount++;
ch <<= 1;
}
}
}
3. 在开发过程中遇到的问题以及解决方法
3.1如果在解压缩时,最后一个字节的压缩数据不满8个比特位,则在解压缩过程中如何处理?
**方法一:**在压缩过程中可以把最后一个字节占用的比特位传入压缩文件,则在解压缩时直接读取即可
方法二:根据所创建的Huffman树我们可以了解到,根节点的权值即为源文件的总大小,当解压缩成功的字节数等于源文件大小时,解压缩结束。
3.2在解压缩过程中会出现乱码,怎么处理?
首先应该注意到是的乱码出现的原因:
1.文件中存在汉字,而汉字的编码对应ASCII表可能是使用多个字节来编码一个汉字,但是在解码过程中是逐字节获取,这就导致了该字节在表中对应一个负数
解决方法:
将程序中所有的char类型修改为unsigned char,值得注意的是fileByteInfo[(uchar)strContent[0]].appearCount = atoi(strContent.c_str() + 2);
解压缩过程中这里需要强制类型转化为unsigned char,因为在C++中string也是无符号类型,要是不强转的话,乱码情况还是会出现,而且排错时很难找出这个问题。
2.文件中包含多行文本时解压缩出现乱码
最直接的排错方式:查看压缩与解压缩时使用的Huffman树是否相同,相当于比较压缩与解压缩时所使用的字节频次信息是否相同,遇到换行时,直接开始下一次循环,以至于最后的循环少一次。
3.3 解压缩文件大小小于源文件大小,没有解压缩完全如何解决?
一、如何判断解压缩文件是否正确
1.利用一些工具来进行对比,我在这里使用的是Ultar Edit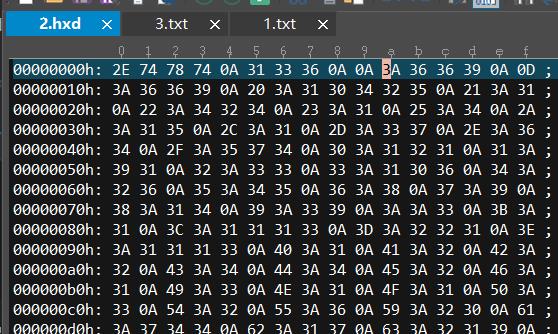
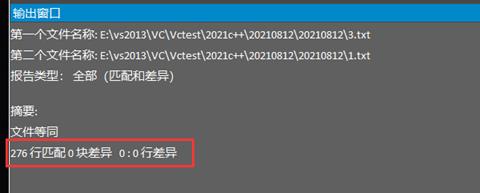
2.也可以使用代码进行模拟,将源文件与解压缩文件分别读入内存,然后逐字节进行比对
二、文件读取时,”r"文本方式读入,读取时遇到-1就会结束,所以在此处要采用二进制方式进行读写“rb”
3.4 还有一个极小的细节
我这里没有对文件的路径进行封装,有想法的铁子可以试着自己封装一下,不过也无伤大雅
4.测试
4.1对于不同文件的压缩率对比
文本文件:
1.字符文本

字符文本压缩率:15/25*100 = 60%
2.汉字与字符文本

汉字与字符文本压缩率:15/17*100%=88.24%
二进制文件
1.图片

图片压缩率:87/88*100% =98.8%
2.音频与视频
压缩率都超过了100%,在这里就不演示了
结论:
文本文件的压缩率比二进制文件的压缩率更好,因为文本文件的编码相比于二进制文件的编码相对更简单,导致了文件压缩率的差距较大
4.2如果对压缩结果二次或者多次压缩,会不会每次都变小?
答案是肯定不会,对压缩文件再次压缩就相当于在进行一次Huffman编码的基础上再进行编码,结果不一定
4.3Huffman压缩有无出现压缩结果变大的可能?
有,在文件中如果字节的种类非常多,而且出现次数比较均衡的情况下,变大的可能性就越大,Huffman树在越接近平衡二叉树的情况下,压缩结果越不理想,字节的编码长度都差不多,比如压缩音频以及视频文件
- 判断压缩结果变大或者变小?
如果编码的长度小于8比特位的总数 < 编码长度大于8比特位的字节总数,则压缩结果变大;反之变小
4.4 与其他压缩工具的横向对比
在此我采用的是对比zip压缩和tar.gz压缩方式
压缩二进制文件

压缩文本文件

总结:各方面被人家完虐,就没有可比性了已经

以上就是本次项目的所有内容,今天就到此结束了哈,由于作者创作能力有限,可能总结的内容或多或少会有差错,欢迎大家及时帮我指正,有的知识我写的很浅薄很片面,如果大佬们有不同的观点欢迎大家赏光私我哈,本着相互进步的原则,希望大家能多多向我提意见,如果你真的从文章中学到了一些新东西并且觉得写的还不错,还请您收藏点赞支持一下,也可以分享给您的好朋友一起进步,最后谢谢您的支持,爱你们哦~~

以上是关于[保姆级万字教程]打造最迷人的S曲线----带你从零手撕基于Huffman编码的文件压缩项目的主要内容,如果未能解决你的问题,请参考以下文章