小白都能看懂的分布式事务与2PC
Posted 神技圈子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小白都能看懂的分布式事务与2PC相关的知识,希望对你有一定的参考价值。
分布式事务的原子性
一提到到事务,一般就会想到它的ACID特性,其中A(atomic)其实就是指事务的原子性。那么什么是原子性呢,简单来说原子性就是要求事务只有两个状态:
- 一是成功,也就是所有操作全部成功
- 二是失败,任何操作没有被执行,即使过程中已经执行了部分操作,也要保证回滚这些操作。
其实要做到原子性并不容易,因为多数情况下事务是由多个操作构成的序列。而分布式事务原子性的表现与普通的事务原子性一致。分布式事务要涉及多个物理节点,而且还增加了网络这个不确定因素,使得要满足分布式事务的原子性问题更加复杂。
那么,如何协调内部的多项操作从而对外表现出统一的成功或者失败呢?这需要一系列的算法或者协议来保证。下面我们就来说一下最重要的2PC协议。
什么是2PC
2PC(Two-phase Commitment Protocal)。作为数据库领域最常用的协议,首次提出是Jim Gray在1977年发表的一份文稿中提出的。但是,2PC在工程中的应用其实还要早几年。
2PC可以应用在分布式事务,保证了分布式事务提交的原子性,并在不损坏日志的情况下.实现快速故障恢复,提高分布式数据库系统的可靠性。
在分布式事务中,把分布式事务的某一个代理(根代理)指定为协调者(coodinator),所有其他代理称为参与者(Participants)。只有协调者才有掌握提交或撤销事务的决定权,而其他参与者各自负责在其本地数据库中执行写操作,并向协调者提出撤销或提交子事务的意向。
其实在生活中2PC的例子有很多。下面通过一个例子来讲解2PC的原理。某班要组织一个同学聚会活动,该活动的前提条件是所有参与者(participant)同意才能举行,任意一个人不同意则取消该活动。那么该怎么举办这次活动呢?
第一阶段(phase1)
组织者(coordinator)打电话给所有参与者(participant),同时告知他们参与者列表(请注意这个参与者列表非常重要)。
proposal:提出周六2pm-5pm举办活动
vote:参与者需要投票给组织者accept 或者reject
block:如果参与者都accept,则组织者锁住2pm-5pm的时间,不再接受其它请求。
第二阶段(phase2)
commit:如果所有参与者都同意,则组织者(coordinator)通知所有参与者commit,否则通知abort,组织者解除绑定
这种提交方式也是有失败的可能性的,失败情况总结起来分为以下两种:
1.参与者失败(Participant failure):
任一参与者无响应,coordinator直接执行abort
2.(协调者失败)Coordinator failure:
Takeover: 如果participant一段时间没收到cooridnator确认(commit/abort),则认为coordinator不在了。这时候可切换自动成为Coordinator备份(watchdog)
Query: watchdog根据phase 1接收到的参与者列表发起query
Vote: 所有participant回复vote结果给watchdog, accept or reject。
Commit: 如果所有都同意,则commit, 否则abort。
2PC提交事务的过程
所以通过上节的例子,总结起来2PC把事务的提交过程分为两个阶段
1.第一阶段是表决阶段,目的是形成一个共同的决定。
2.第二阶段是执行阶段,目的是实现这个决定。根据协调者的指令。参与者或者提交事务,或者撤销事务,并给协调者发送确认消息。此时,协调者在日志中写入一条事务结束记录并终止事务。
协调者与参与者两阶段提交过程如下图所示
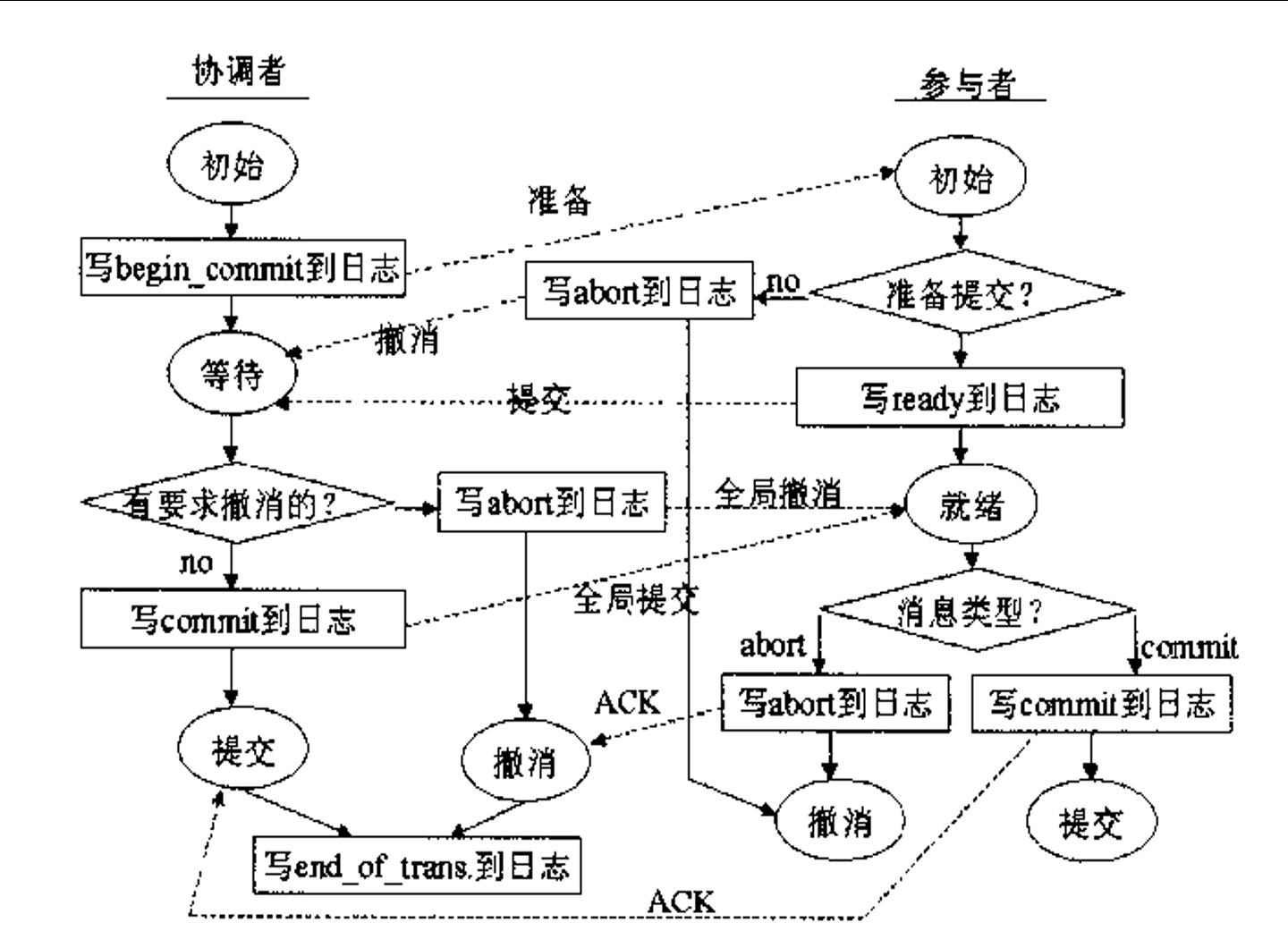
2PC的全局提交规则
1.只要有一个参与者撤销事务,协调者就必须做出全局撤销决定。
2.只有所有参与者都同意提交事务,协调者才能做出全局提交决定。
注:协调者和参与者可能进入某些相互等待对方发送消息的状态。为了确保它们能够从这些状态中退出并终止,要使用定时器。
每个进程进入一个状态时都要设置定时器。如果所期待的消息在定时器超时之前没有到来,定时器向进程报警,进程于是调用它自己的超时协议。
2PC通信架构
集中式2PC通信架构
集中式两阶段提交协议,通信只发生在协调者和参与者之间,参与者之间不交换消息。
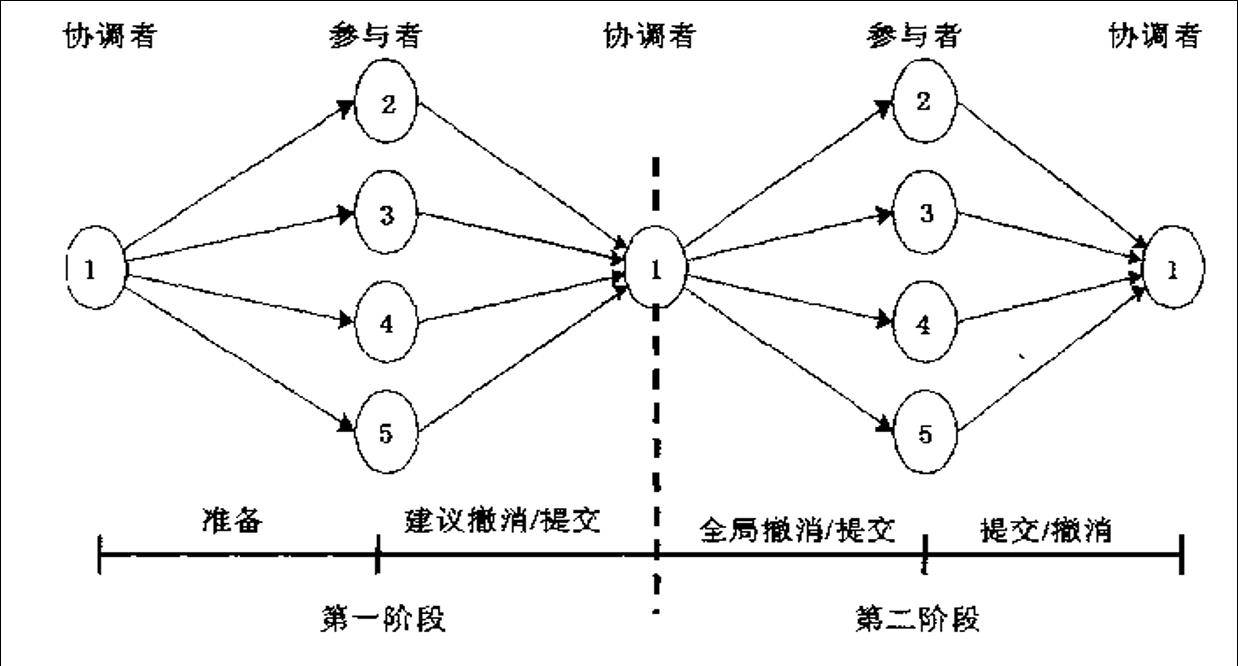
分层2PC通信架构
在协调者和参与者之间的通信不用直接广播的方法进行,而是使报文在树中上下传播
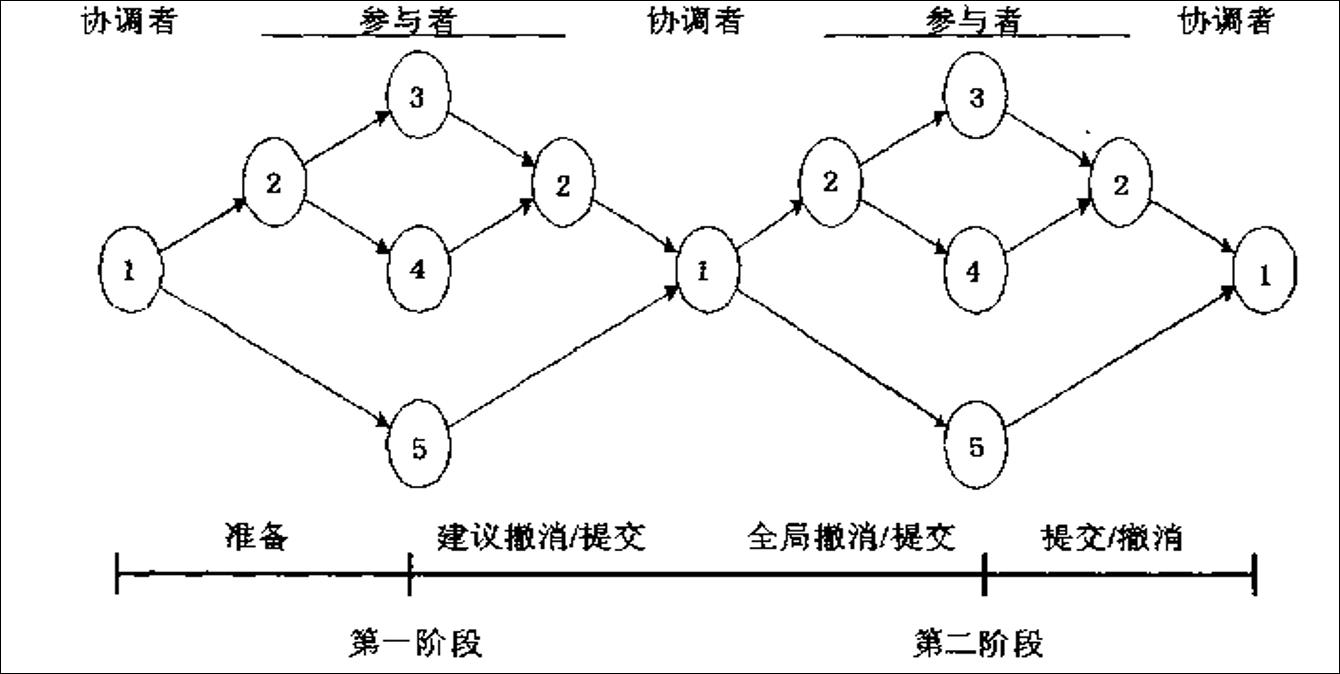
线性2PC通信架构
在线性两阶段提交协议中,参与者之间可以相互通信。为了通信,系统中的站点之间要进行排序。假设参与事务执行的站点之间的顺序是1到N,协调者就是序列中的第一个。
实现两阶段提交协议时,在第一阶段使用了向前通信方式,从协调者(No.1)到N;在第二阶段使用了向后通信方式,即从N到协调者。
线性2PC产生较少的消息.但是不提供任何并行。因此,它增加了响应时间,降低了性能。
故障恢复
故障类型一般分为站点故障、报文丢失两种。下面来讲讲该如何恢复
站点故障
1.一参与者在把就绪记录写入运行记录以前出现故障。在这种情况下,协调者超时机制满期,它将采取撤消的决定。所有的参与者都撤销它们的子事务。当发生该故障的参与者恢复时,重启动过程简单地撤销该事务即可.不需要过问其它站点的情况。
2.一参与者在把就绪记录写入运行记录以后发生故障。在这种情况下,其它参与者的站点终止该事务(提交或撤消)。当故障站点恢复时,重启动过程不得不询问协调者或别的某个参与者关于该事务的结果(提交或撤消),然后执行相应的动作(提交或撤消)。这种情况下需要访问远程的恢复信息。
3.协调者在把预备记录写入运行记录以后,而在写入global-commit或global-abort记录以前发生故障。这种情况下所有已经回答READY的参与者必须等待协调者恢复。协调者的重启动过程从头开始恢复提交协议,从预备记录(在运行记录中)读取参与者的标识,再次把PREPARE(预备)报文发送给它们。每个就绪的参与者必须要识别出该新的PREPARE报文是前一个PREPARE的重复报文。
4.协调者在运行中写入global-commit或global-abort记录以后而在写入完成记录以前发生故障。这种情况下,协调者在重启动时必须再次给所有参与者发送其决定,未曾收到此命令的所有参与者不得不等待到协调者恢复为止。和以前一样,参与者不应因收到该命令报文两次而受到影响。
5.协调者在运行记录中写入完成以后发生故障。这种情况下,该事物已经结束,在重启动时不需任何动作。
报文丢失
1.来自一个参与者的回答报文(READY或ABORT)被丢失。在这种情况下,协调者的超时满期,整个事务被撤销。要注意,只由协调者来发现这种故障,而从协调者的观点来看,它完全好像是一参与者的故障。但是.从参与者的观点来看情况就不同了,该参与者并不认为自己有故障,因而不会执行重启动过程。
2.丢失一个PREPARE报文。这种情况下该参与者仍停在等待状态。因为协调者并没有收到回答,所以其全局结果和前一种情况相同。
3.丢失一个命令报文(commit或abort)。参与者对此命令处于不肯定状态。在参与者中引入超时机制就可简单地消除这个问题;从回答起在超时后仍末收到任何报文的话,就发送—请求再发送该命令。
4.丢失一个ACK报文。协调者对参与者有无收到该报文处于不肯定状态。可以在协调者中引入超时机制就可简单地消除这个问题;如果从发出命令起到超时后仍未受到任何ACK报文,协调者就再次发送该命令。在参与者站点处理这种情况的最好办法是再次发送ACK报文,即使该子事务在那期间已经完成并不再活动也要重发。
总结
事实上,大多数分布式数据库都是在2PC协议基础上改进来保证分布式事务的原子性。下一篇将介绍两个有代表性的改进模型,它们分别来自两大阵营NewSQL和PGXC。
以上是关于小白都能看懂的分布式事务与2PC的主要内容,如果未能解决你的问题,请参考以下文章