19推荐系统4DeeoCrossing
Posted 炫云云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了19推荐系统4DeeoCrossing相关的知识,希望对你有一定的参考价值。
1、前言
相比 AutoRec模型过于简单的网络结构带来的一些表达能力不强的问题,Deep Crossing模型完整地解决了从特征工程、稀疏向量稠密化、多层神经网络进行优化目标拟合等一系列深度学习在推荐系统中的应用问题,为后续的研究打下了良好的基础。
Deep Crossing对单个特征进行多种组合, 组合特征有时称为cross features或者multi-way features,并且当作后续学习器的输入。更具体地说,它采用了诸如文本,分类,ID和数字特征之类的单个特征,并根据特定任务自动搜索最佳组合特征。
2、应用场景
Deep Crossing模型的应用场景是微软搜索引擎Bing中的搜索广告推荐场景。用户在搜索引擎中输入搜索词之后,搜索引擎除了会返回相关结果,还会返回与搜索词相关的广告。尽可能地增加搜索广告的点击率,准确地预测广告点击率,并以此作为广告排序的指标之一,是非常重要的工作,也是Deep Crossing模型的优化目标。
微软使用的特征如下表1所示,这些特征可以分为三类:
- 一类是可以被处理成one-hot或者multi-hot向量的类别型特征,包括用户搜索词(query)、广告关键词(keyword)、广告标题(title)、落地页(landing page)、匹配类型(match type);
- 一类是数值型特征,微软称其为计数型特征,包括点击率、预估点击率(click prediction);
- 一类是需要进一步处理的特征,包括广告计划(campaign)、曝光计划(impression)、点击样例(click)等。
严格地说,这些都不是独立的特征,而是一个特征的组别,需要进一步处理。例如,可以将广告计划中的预算( budget)作为数值型特征,而广告计划的id则可以作为类别型特征。

表
1
:
D
e
e
p
C
r
o
s
s
i
n
g
模
型
使
用
的
特
征
表1:Deep~~ Crossing模型使用的特征
表1:Deep Crossing模型使用的特征
类别型特征可以通过one-hot或multi-hot编码生成特征向量,数值型特征则可以直接拼接进特征向量中,在生成所有输入特征的向量表达后,Deep Crossing模型利用该特征向量进行CTR预估。深度学习网络的特点是可以根据需求灵活地对网络结构进行调整,从而达成从原始特征向量到最终的优化目标的端到端的训练目的。
单个特征 X i X_i Xi可以通过向量进行表示,例如搜索词等文本特征,通过embedding表示。组合特征由单个特征组合而成,单个特征 X i ∈ R n i X_{i} \\in \\mathbb{R}^{n_{i}} Xi∈Rni, X j ∈ R n j X_{j} \\in \\mathbb{R}^{n_{j}} Xj∈Rnj,组合特征 X i , j ∈ R n i × R n j X_{i,j}∈\\mathbb{R}^{n_i} \\times \\mathbb{R}^{n_j} Xi,j∈Rni×Rnj 。Deep Crossing解决特征工程中特征组合的难题,与之前介绍的FNN、PNN不同的是,Deep Crossing并没有采用显式交叉特征的方式,而是利用残差网络结构挖掘特征间的关系。Deep Crossing模型可以通过调整神经网络的深度进行特征之间的“深度交叉”,这也是Deep Crossing名称的由来。
下面通过剖析Deep Crossing模型的网络结构,探索深度学习是如何通过对特征的层层处理,最终准确地预估点击率的。
3、模型结构
为完成端到端的训练,Deep Crossing模型要在其内部网络中解决如下回题。
( 1)离散类特征编码后过于稀疏,不利于直接输入神经网络进行训练,如何解决稀疏特征向量稠密化的问题。
(2)如何解决特征自动交叉组合的问题。
(3)如何在输出层中达成问题设定的优化目标。
图
1
:
D
e
e
p
C
r
o
s
s
i
n
g
模
型
的
结
构
图
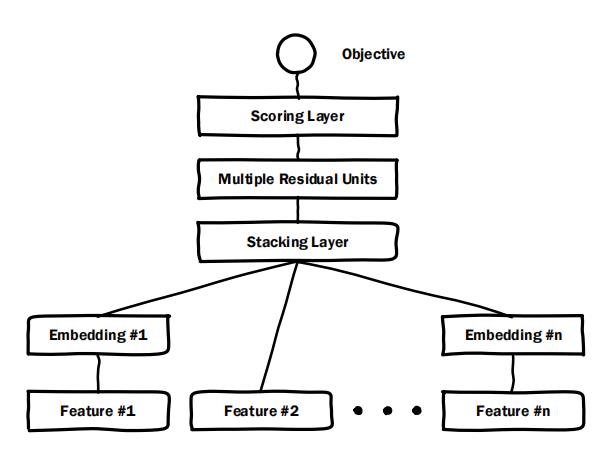
图1:Deep~ Crossing模型的结构图
图1:Deep Crossing模型的结构图
主要分为embedding layer,stacking layer,residual unit 和scoring layer。
deep crossing模型中输入的部分用得是原始的单个特征,不进行手动特征组合,完全靠模型自己去学。
Embedding层:Embedding层将稀疏的类别型特征转换成稠密的Embedding向量。Embedding层由单层神经网络构成,一般形式为:
X
j
O
=
max
(
0
,
W
j
X
j
I
+
b
j
)
X_{j}^{O}=\\max \\left(\\mathbf{0}, \\mathbf{W}_{j} X_{j}^{I}+\\mathbf{b}_{j}\\right)
XjO=max(0,WjXjI+bj)
b
∈
R
n
j
\\mathbf{b} \\in \\mathbb{R}^{n_{j}}
b∈Rnj,
X
j
I
∈
R
n
j
X_{j}^{I} \\in \\mathbb{R}^{n_{j}}
XjI∈Rnj 是第
j
j
j个输入特征,并且已经过one-hot编码表示,
W
j
W_{j}
Wj是第
j
j
j个特征对应filed的
m
j
×
n
j
m_j×n_j
mj×nj 参数矩阵, 通过将特征分成不同的field,来减少embedding层的参数。公式中的
m
a
x
max
max 操作等价于使用
r
e
l
u
relu
relu 激活函数。
对于维度非常高的特征,比如CampaignID(一个ID是一个推广计划,一个推广计算中有若干个广告)有数万种,其对应的 W j W_j Wj 仍然十分庞大。为此作者提出,针对这些高基数特征构造衍生特征,具体操作如下。根据CampaignID的历史点击率从高到低选择Top1000个,编号从0到999,将剩余的ID统一编号为1000。同时构建其衍生特征,将所有ID对应的历史点击率组合成1001维的稠密矩阵,各个元素分别为对应ID的历史CTR,最后一个元素为剩余ID的平均CTR。通过降维引入衍生特征的方式,可以有效的减少高基数特征带来的参数量剧增问题。
Embedding的大小对模型的整体大小有着重大的影响。Figure1中的Feature#2代表了数值型特征,可以看到,数值型特征不需要经过Embedding层,直接进入了Stacking层。特征embedding为256维.
Stacking层:Stacking层的作用是将Embedding的输出特征和数值型特征拼接在一起,形成新的包含全部特征的特征向量, X O = [ X 0 O , X 1 O , ⋯ , X K O ] X^{O}=\\left[X_{0}^{O}, X_{1}^{O}, \\cdots, X_{K}^{O}\\right] XO=[X0O,X1O,⋯,XKO], K K K为输入特征的数量。该层通常也被称为连接层。
Multiple Residual Units层:该层的主要结构是多层感知机,相比标准的以感知机为基本单元的神经网络,Deep Crossing模型采用了多层残差网络作为MLP的具体实现。通过多层残差网络对特征向量各个维度进行充分的交叉组合,使模型能够抓取到更多的非线性特征和组合特征的信息,进而增强特征提取能力。
残差层由如下图的残差单元构造而成。
图
2
:
残
差
单
元
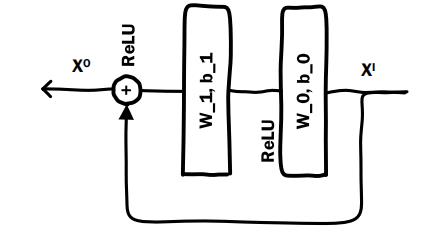
图2:残差单元
图2:残差单元
Deep Crossing简单的修改了残差单元,不适用卷积核。残差单元的独特之处在于两个,
- 它是将原输入特征通过两层以ReLU为激活函数的全连接层后,生成输出向量 。
- 输入可以通过一个快捷连接与输出向量进行元素加操作,生成最终的输出向量。
在这样的结构下,残差单元中的两层ReLU网络其实拟合的是输出和输入之间的“残差”(
x
o
−
x
i
x^o-x^i
xo−xi),这就是残差神经网络名称的由来。表达式为
X
O
=
F
(
X
I
,
{
W
0
,
W
1
}
,
{
b
0
,
b
1
}
)
+
X
I
X^{O}=F\\left(X^{I},\\left\\{W_{0}, W_{1}\\right\\},\\left\\{b_{0}, b_{1}\\right\\}\\right)+X^{I}
XO=F(XI,{W0,W1},{b0,b1})+XI
Scoring层:Scoring层作为输出层,就是为了拟合优化目标而存在的。对于CTR预估这类二分类问题,Scoring层往往使用的是逻辑回归模型,而对于图像分类等多分类问题,Scoring层往往采用softmax模型。该层利用交叉熵作为损失函数,可以替换为其他任意的损失函数
logloss
=
−
1
N
∑
i
=
1
N
(
y
i
log
(
p
i
)
+
(
1
−
y
i
)
log
(
1
−
p
i
)
)
\\text {logloss}=-\\frac{1}{N} \\sum_{i=1}^{N}\\left(y_{i} \\log \\left(p_{i}\\right)+\\left(1-y_{i}\\right) \\log \\left(1-p_{i}\\right)\\right) \\\\
logloss=−N1i=1∑N(yilog(pi)+(1−yi)log(1−pi))
以上就是Deep Crossing的模型结构,在此基础上采用梯度反向传播的方法进行训练,最终得到基于Deep Crossing的CTR预估模型。
Early Crossing vs. Late Crossing
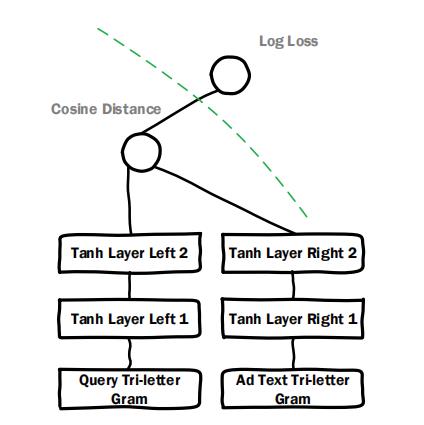
在paper中,作者针对特征交叉的时间点先后的问题进行试验对比。在DeepCrossing中,特征是在Embedding之后就开始进行交叉,但是有一些模型如DSSM,是在各类特征单独处理完成之后再进行交叉计算,这类模型的结构如下所示:
图
3
:
D
S
S
M
模
型
图3:DSSM模型
图3:DSSM模型
文中提到,DSSM更擅长文本处理,设计文本处理相关实验,DeepCrossing比DSSM表现更优异。作者认为,DeepCrossing表现优异主要来源于:1)残差结构;2)及早的特征交叉处理;
参考
《深度学习推荐系统》王喆
以上是关于19推荐系统4DeeoCrossing的主要内容,如果未能解决你的问题,请参考以下文章