19推荐系统9Wide&Deep
Posted 炫云云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了19推荐系统9Wide&Deep相关的知识,希望对你有一定的参考价值。
文章目录
1、Wide&Deep模型——记忆能力和泛化能力的综合
本节介绍的是自提出以来就在业界发挥着巨大影响力的模型–谷歌于2016年提出的 Wide&Deep模型 。Wide&Deep模型的主要思路正如其名,是由单层的 Wide部分和多层的 Deep部分组成的混合模型。其中,Wide部分的主要作用是让模型具有较强的“记忆能力”( memorization );Deep部分的主要作用是让模型具有“泛化能力”( generalization ),正是这样的结构特点,使模型兼具了逻辑回归和深度神经网络的优点——能够快速处理并记忆大量历史行为特征,并且具有强大的表达能力,不仅在当时迅速成为业界争相应用的主流模型,而且衍生出了大量以 Wide&Deep模型为基础结构的混合模型,影响力一直延续至今。
2、模型的记忆能力与泛化能力
Wide&Deep模型的设计初衷和其最大的价值在于同时具备较强的“记忆能力”和“泛化能力”。
“记忆能力"可以被理解为模型直接学习并利用历史数据中物品或者特征的“共现频率"的能力。一般来说,协同过滤、逻辑回归等简单模型有较强的“记忆能力”。由于这类模型的结构简单,原始数据往往可以直接影响推荐结果,产生类似于“如果点击过A,就推荐B”这类规则式的推荐,这就相当于模型直接记住了历史数据的分布特点,并利用这些记忆进行推荐。
因为Wide&Deep是由谷歌应用商店(Google Play)推荐团队提出的,所以这里以 App推荐的场景为例,解释什么是模型的“记忆能力”。
假设在 Google Play推荐模型的训练过程中,设置如下组合特征:AND(user_installed_app=netflix, impression_app=pandora)(简称netflix&pandora ),它代表用户已经安装了netflix这款应用,而且曾在应用商店中看到过pandora这款应用。如果以“最终是否安装pandora”为数据标签( label ),则可以轻而易举地统计出netflix&pandora这个特征和安装pandora这个标签之间的共现频率。假设二者的共现频率高达10%(全局的平均应用安装率为1%),这个特征如此之强,以至于在设计模型时,希望模型一发现有这个特征,就推荐pandora这款应用(就像一个深刻的记忆点一样印在脑海里),这就是所谓的模型的“记忆能力”。像逻辑回归这类简单模型,如果发现这样的“强特征”,则其相应的权重就会在模型训练过程中被调整得非常大,这样就实现了对这个特征的直接记忆。相反,对于多层神经网络来说,特征会被多层处理,不断与其他特征进行交叉,因此模型对这个强特征的记忆反而没有简单模型深刻。
“泛化能力”可以被理解为模型传递特征的相关性,以及发掘稀疏甚至从未出现过的稀有特征与最终标签相关性的能力。矩阵分解比协同过滤的泛化能力强,因为矩阵分解引人了隐向量这样的结构,使得数据稀少的用户或者物品也能生成隐向量,从而获得有数据支撑的推荐得分,这就是非常典型的将全局数据传递到稀疏物品上,从而提高泛化能力的例子。再比如,深度神经网络通过特征的多次自动组合,可以深度发掘数据中潜在的模式,即使是非常稀疏的特征向量输人,也能得到较稳定平滑的推荐概率,这就是简单模型所缺乏的“泛化能力”。
3、 Wide&Deep模型的结构
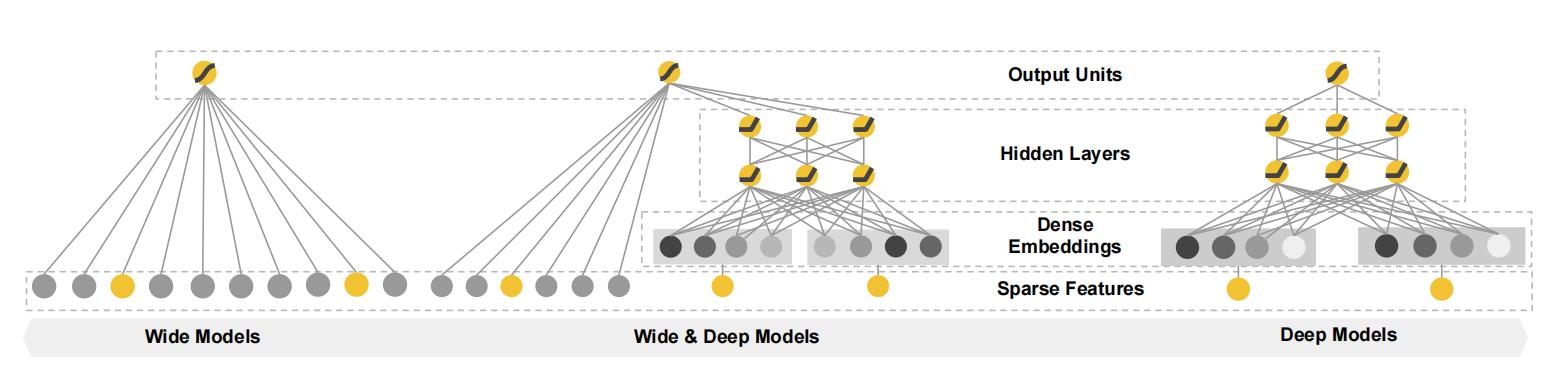
既然简单模型的“记忆能力”强,深度神经网络的“泛化能力”强,那么设计Wide&Deep模型的直接动机就是将二者融合,具体的模型结构如图1所示。
图
1
:
W
i
d
e
&
D
e
e
p
模
型
图1:Wide \\& Deep模型
图1:Wide&Deep模型
Wide&Deep模型把单输入层的 Wide部分与由Embedding层和多隐层组成的Deep部分连接起来,一起输入最终的输出层。单层的 Wide部分善于处理大量稀疏的id类特征;Deep部分利用神经网络表达能力强的特点,进行深层的特征交叉,挖掘藏在特征背后的数据模式。最终,利用逻辑回归模型,输出层将 Wide部分和 Deep部分组合起来,形成统一的模型。
图
2
:
推
荐
系
统
概
述
图2:推荐系统概述
图2:推荐系统概述
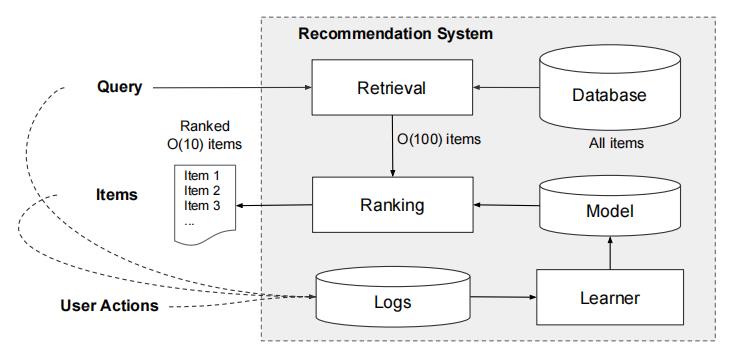
和大多数推荐系统类似,Google Play推荐系统主要分Retrieve和Ranking两个阶段。(youtube论文的Matching和Ranking)
Retrieve阶段负责召回候选集,缩减待排序item数据,文中是O(10)数量级。Ranking进行精排序,即最终展示的app list 顺序。 Query包括用户画像,上下文特征等内容;Item就是App。交互行为特征可能是点击和购买。
3.1、 Wide部分
Wide部分是广义线性模型
y
=
w
T
x
+
b
y=\\mathbf{w}^{T} \\mathbf{x}+b
y=wTx+b,如图1(左)所示。
y
y
y 是预测值,
x
=
[
x
1
,
x
2
,
…
,
x
d
]
\\mathbf{x}=\\left[x_{1}, x_{2}, \\ldots, x_{d}\\right]
x=[x1,x2,…,xd] 是
d
d
d特征向量,
w
=
\\mathbf{w}=
w=
[
w
1
,
w
2
,
…
,
w
d
]
\\left[w_{1}, w_{2}, \\ldots, w_{d}\\right]
[w1,w2,…,wd] 为模型参数,
b
b
b为偏差。特征集包括原始输入特征和转换后的特征,最重要的转换之一是交叉乘积转换,组合了“已经安装应用”和“曝光应用”,定义为
ϕ
k
(
x
)
=
∏
i
=
1
d
x
i
c
k
i
c
k
i
∈
{
0
,
1
}
(1)
\\phi_{k}(\\mathbf{x})=\\prod_{i=1}^{d} x_{i}^{c_{k i}} \\quad c_{k i} \\in\\{0,1\\}\\tag{1}
ϕk(x)=i=1∏dxickicki∈{0,1}(1)
c
k
i
c_{k i}
cki 是一个布尔变量,如果第
i
i
i个特征是第
k
k
k个变换
ϕ
k
\\phi_{k}
ϕk的部分则为1,反之为0.
对于二元特征,当且仅当组成特征(“gender=female”和“language=en”)均为1,交叉乘积变换(例如,“AND(gender=female, language=en”)”为1,否则为0时。这捕获了二元特征之间的相互作用,并将非线性添加到广义线性模型中。
3.2、 Deep部分
Deep部分是前馈神经网络,如图1(右)所示。对于分类特性,原始输入是特性字符串(例如," language=en ")。这些稀疏的、高维的分类特征首先被转换成一个低维的、密集的实值向量,通常称为embedding 向量。嵌入的向量通常在
O
(
10
)
O(10)
O(10)到
O
(
100
)
O(100)
O(100)的量级。在模型训练过程中,对嵌入向量进行随机初始化,然后对其进行训练,使最终损失函数最小。这些低维密集的嵌入向量在前向传递中被输入到神经网络的隐藏层中。具体来说,每个隐藏层执行以下计算:
a
(
l
+
1
)
=
f
(
W
(
l
)
a
(
l
)
+
b
(
l
)
)
(2)
a^{(l+1)}=f\\left(W^{(l)} a^{(l)}+b^{(l)}\\right)\\tag{2}
a(l+1)=f(W(l)a(l)+b(l))(2)
其中
l
l
l是层数,
f
f
f是ReLU激活函数,
a
(
l
)
,
b
(
l
)
a^{(l)}, b^{(l)}
a(l),b(l),和
W
(
l
)
W^{(l)}
W(l)为第
l
l
l层的激活、偏差和模型权值。
3.3、 Wide部分和Deep部分的结合
将wide部分和deep部分用它们的输出对数概率的加权和作为预测,然后将其输入到联合训练的一个共同的逻辑损失函数。请注意,联合训练和集成训练是有区别的。
- 集成训练中,每个模型是独立训练的,而且他们的预测是在推理时合并而不是在训练时合并。
- 联合训练在训练时同时考虑wide和deep模型以及它们的加权和来优化所有参数。
对模型大小也有影响:对于集成学习,由于训练是独立的,每个单独的模型大小通常需要更大(例如,有更多的特征和转换),以达到合理的精度。相比之下,对于联合训练,wide部分只需要通过少量的交叉乘积变换来弥补deep 部分的不足,而不需要全尺寸wide模型。
这个联合模型如图1(中)所示。对于逻辑回归问题,模型的预测是:
P
(
Y
=
1
∣
x
)
=
σ
(
w
w
i
d
e
T
[
x
,
ϕ
(
x
)
]
+
w
d
e
e
p
T
a
(
l
f
)
+
b
)
(2)
P(Y=1 \\mid \\mathbf{x})=\\sigma\\left(\\mathbf{w}_{w i d e}^{T}[\\mathbf{x}, \\phi(\\mathbf{x})]+\\mathbf{w}_{d e e p}^{T} a^{\\left(l_{f}\\right)}+b\\right)\\tag{2}
P(Y=1∣x)=σ(wwideT[x,ϕ(x)]+wdeepTa(lf)+b)(2)
其中
Y
Y
Y是二进制类标签,
σ
(
⋅
)
\\sigma(\\cdot)
σ(⋅)是sigmoid函数,
ϕ
(
x
)
\\phi(\\mathbf{x})
ϕ(x)是原始特征
x
\\mathbf{x}
x的叉乘变换,
b
b
b是偏差项。
w
wide
\\mathbf{w}_{\\text {wide}}
wwide是所有wide模型权值的向量,而
w
deep
\\mathbf{w}_{\\text {deep}}
wdeep是应用于最终激活
a
(
l
f
)
a^{\\left(l_{f}\\right)}
a(lf)的权值 。
3.4、 特征工程
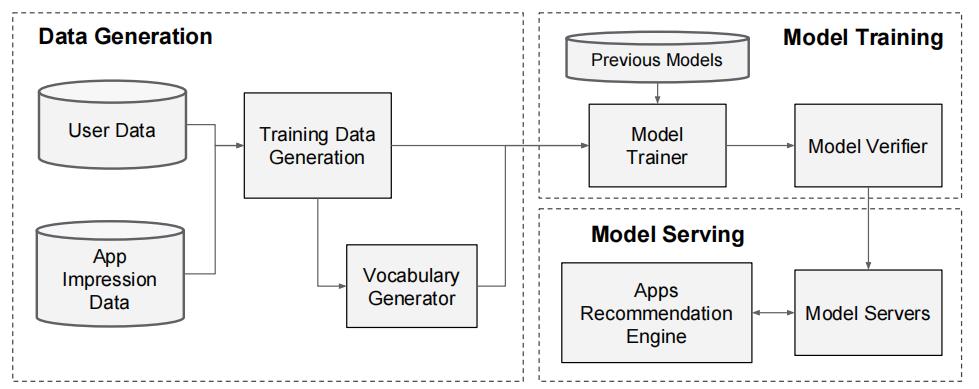
如图3所示,应用推荐管道的实现包括三个阶段:数据生成、模型训练和模型服务
图
3
:
A
p
p
推
荐
管
道
概
述
图3:App推荐管道概述
图3:App推荐管道概述
3.4.1、数据生成
在这个阶段,使用一段时间内的用户和app曝光数据来生成训练数据。每个例子对应一个曝光。标签是应用获取:如果应用程序已经安装,则为1,否则为0。
词汇表(将分类特性字符串映射到整数id的表)也在这个阶段生成。系统计算出现次数超过最小次数的所有字符串特性的ID空间。通过将特征值 x x x映射到其累积分布函数 P ( x ≤ x ) P(x \\leq x) P(x≤x),将连续实值特征归一化为 [ 0 , 1 ] [0,1] [0,1],将其分解为 n q n_{q} nq分位数。对于 i i i -th分位数中的值,归一化的值是 i − 1 n q − 1 \\frac{i-1}{n_{q}-1} nq−1i−1。分位数边界是在数据生成期间计算的。
3.4.2、模型训练
<以上是关于19推荐系统9Wide&Deep的主要内容,如果未能解决你的问题,请参考以下文章