sklearn 笔记:数据归一化(StandardScaler)
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sklearn 笔记:数据归一化(StandardScaler)相关的知识,希望对你有一定的参考价值。
1 StandardScaler原理
去均值和方差归一化。且是针对每一个特征维度来做的,而不是针对样本。
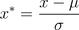 ,其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
,其中μ为所有样本数据的均值,σ为所有样本数据的标准差。
2 用sklearn 实现数据归一化
from sklearn.preprocessing import StandardScaler # 标准化工具
import numpy as np
x_np = np.array([[100, -1., 2.],
[2., 0., 0.],
[-1,-2,1]])
scaler = StandardScaler()
x_train = scaler.fit_transform(x_np)
print(x_train)
'''
[[ 1.4137317 0. 1.22474487]
[-0.67489704 1.22474487 -1.22474487]
[-0.73883466 -1.22474487 0. ]]
'''3 fit_transform 和transform的区别
- fit_transform是fit和transform的组合。相当于先fit,再tranform(先拟合数据,再标准化)
- fit(x,y)传两个参数的是有监督学习的算法,fit(x)传一个参数的是无监督学习的算法(比如降维、特征提取、标准化)
- fit和transform没有任何关系,之所以出来这么个函数名,仅仅是为了写代码方便,所以会发现transform()和fit_transform()的运行结果是一样的。
- 运行结果一模一样不代表这两个函数可以互相替换,绝对不可以!transform函数是一定可以替换为fit_transform函数的,fit_transform函数不能替换为transform函数!
以上是关于sklearn 笔记:数据归一化(StandardScaler)的主要内容,如果未能解决你的问题,请参考以下文章