B-/B+树作为Mysql索引数据结构的区别
Posted 这瓜保熟么
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了B-/B+树作为Mysql索引数据结构的区别相关的知识,希望对你有一定的参考价值。
一、mysql索引原理详解
1、背景
使用mysql最多的就是查询,我们迫切的希望mysql能查询的更快一些,我们经常用到的查询有:
按照id查询唯一一条记录
按照某些个字段查询对应的记录
查找某个范围的所有记录(between and)
对查询出来的结果排序
mysql的索引的目的是使上面的各种查询能够更快。
2:什么是索引?
索引的本质:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺
序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
磁盘中数据的存取
以机械硬盘来说,先了解几个概念。
- 扇区:磁盘存储的最小单位,扇区一般大小为512Byte。
- 磁盘块:文件系统与磁盘交互的的最小单位(计算机系统读写磁盘的最小单位),一个磁盘块由连续几个(2^n)扇区组成,块一般大小一般为4KB。
磁盘读取数据磁盘读取数据靠的是机械运动,每次读取数据花费的时间可以分为寻道时间、旋转延迟、传输时间三个部分,
- 寻道时间指的是:磁臂移动到指定磁道所需要的时间,主流磁盘一般在5ms以下;
- 旋转延迟就是:我们经常听说的磁盘转速,比如一个磁盘7200转,表示每分钟能转7200次,也就是说1秒钟能转120次,旋转延迟就是1/120/2 = 4.17ms;(旋转延迟用磁盘旋转一周所需时间的一半来表示。例如转速为5400转/分,则它的平均旋转延迟为60/5400*0.5=0.0056s=5.6ms)
- 传输时间指的是:从磁盘读出或将数据写入磁盘的时间,一般在零点几毫秒,相对于前两个时间可以忽略不计。那么访问一次磁盘的时间,即一次磁盘IO的时间约等于5+4.17 = 9ms左右,听起来还挺不错的,但要知道一台500 -MIPS的机器每秒可以执行5亿条指令,因为指令依靠的是电的性质,换句话说执行一次IO的时间可以执行40万条指令,数据库动辄十万百万乃至千万级数据,每次9毫秒的时间,显然是个灾难。
3:mysql中的页
mysql中和磁盘交互的最小单位称为页,页是mysql内部定义的一种数据结构,默认为16kb,相当于4个磁盘块,也就是说mysql每次从磁盘中读取一次数据是16KB,要么不读取,要读取就是16KB,此值可以修改的。
4:数据检索过程
我们对数据存储方式不做任何优化,直接将数据库中表的记录存储在磁盘中,假如某个表只有一个字段,为int类型,int占用4个byte,每个磁盘块可以存储1000条记录,100万的记录需要1000个磁盘块,如果我们需要从这100万记录中检索所需要的记录,需要读取1000个磁盘块的数据(需要1000次io),每次io需要9ms,那么1000次需要9000ms=9s,1000条数据随便一个查询就是9秒,这种情况我们是无法接受的,显然是不行的。
一个磁盘块4kb,一条记录4byte,4kb / 4byte = 4 * 1024 byte / 4 byte = 1024 条 (1K)
二、我们迫切的需求是什么?(数据结构和算法)
我们迫切需要这样的数据结构和算法:
需要一种数据存储结构:当从磁盘中检索数据的时候能,够减少磁盘的io次数,最好能够降低到一个稳定的常量值
需要一种检索算法:当从磁盘中读取磁盘块的数据之后,这些块中可能包含多条记录,这些记录被加载到内存中,那么需要一种算法能够快速从内存多条记录中快速检索出目标数据
我们来找找,看是否能够找到这样的算法和数据结构。我们看一下常见的检索算法和数据结构。
1、循环遍历查找
从一组无序的数据中查找目标数据,常见的方法是遍历查询,n条数据,时间复杂度为O(n),最快需要1次,最坏的情况需要n次,查询效率不稳定。
2、二分法查找
二分法查找也称为折半查找,用于在一个有序数组中快速定义某一个需要查找的数据。
原理是:
先将一组无序的数据排序(升序或者降序)之后放在数组中,此处用升序来举例说明:用数组中间位置的数据A和需要查找的数据F对比,如果A=F,则结束查找;如果A<F,则将查找的范围缩小至数组中A数据右边的部分;如果A>F,则将查找范围缩小至数组中A数据左边的部分,继续按照上面的方法直到找到F为止。
示例:
从下列有序数字中查找数字9,过程如下
[1,2,3,4,5,6,7,8,9]
第1次查找:[1,2,3,4,5,6,7,8,9]中间位置值为5,9>5,将查找范围缩小至5右边的部分:[6、7、8、9]
第2次查找:[6、7、8、9]中间值为8,9>8 ,将范围缩小至8右边部分:[9]
第3次查找:在[9]中查找9,找到了。
可以看到查找速度是相当快的,每次查找都会使范围减半,如果我们采用顺序查找,上面数据最快需要1次,最多需要9次,而二分法查找最多只需要3次,耗时时间也比较稳定。
- 二分法查找时间复杂度是:O(logN)(N为数据量),100万数据查找最多只需要20次
- 二分法查找数据的优点:定位数据非常快,前提是:目标数组是有序的。
3、有序数组
如果我们将mysql中表的数据以有序数组的方式存储在磁盘中,那么我们定位数据步骤是:
取出目标表的所有数据,存放在一个有序数组中
如果目标表的数据量非常大,从磁盘中加载到内存中需要的内存也非常大
步骤取出所有数据耗费的io次数太多,步骤2耗费的内存空间太大,还有新增数据的时候,为了保证数组有序,插入数据会涉及到数组内部数据的移动,也是比较耗时的,显然用这种方式存储数据是不可取的。
4、链表
链表相当于在每个节点上增加一些指针,可以和前面或者后面的节点连接起来,就像一列火车一样,每节车厢相当于一个节点,车厢内部可以存储数据,每个车厢和下一节车厢相连。
链表分为单链表和双向链表。
4.1、单链表
//单项链表 class Node1{
private Object data;//存储数据
private Node1 nextNode;//指向下一个节点
}
4.2、双向链表
每个节点中两个指针,分别指向当前节点的上一个节点和下一个节点,结构如下:
//双向链表
class Node2{
private Object data;//存储数据
private Node1 prevNode;//指向上一个节点
private Node1 nextNode;//指向下一个节点
}
链表的优点:
- 可以快速定位到上一个或者下一个节点
- 可以快速删除数据,只需改变指针的指向即可,这点比数组好
链表的缺点:
- 无法向数组那样,通过下标随机访问数据
- 查找数据需从第一个节点开始遍历,不利于数据的查找,查找时间和无需数据类似,需要全遍历,最差时间是O(N)
5、二叉查找树
二叉树是每个结点最多有两个子树的树结构,通常子树被称作“左子树”(left subtree)和“右子树” (right subtree)。二叉树常被用于实现二叉查找树和二叉堆。二叉树有如下特性:
每个结点都包含一个元素以及n个子树,这里0≤n≤2。 2、左子树和右子树是有顺序的,次序不能任意颠倒,左子树的值要小于父结点,右子树的值要大于父结点。
数组[20,10,5,15,30,25,35]使用二叉查找树存储如下:
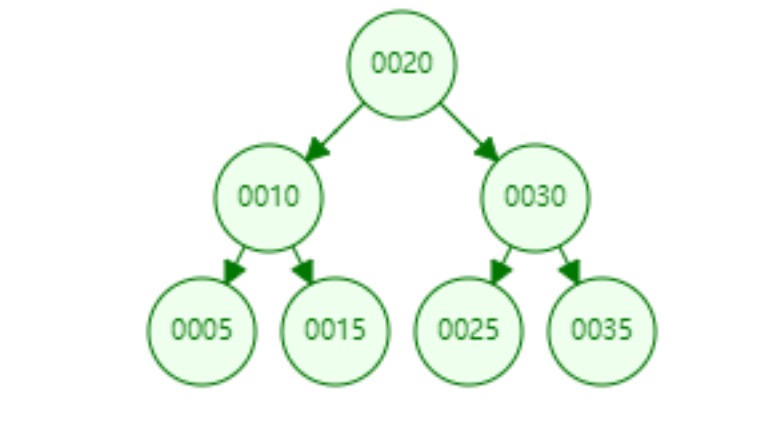
每个节点上面有两个指针(left,rigth),可以通过这2个指针快速访问左右子节点,检索任何一个数据最多只需要访问3个节点,相当于访问了3次数据,时间为O(logN),和二分法查找效率一样,查询数据还是比较快的。
但是如果我们插入数据是有序的,如[5,10,15,20,30,25,35],那么结构就变成下面这样:
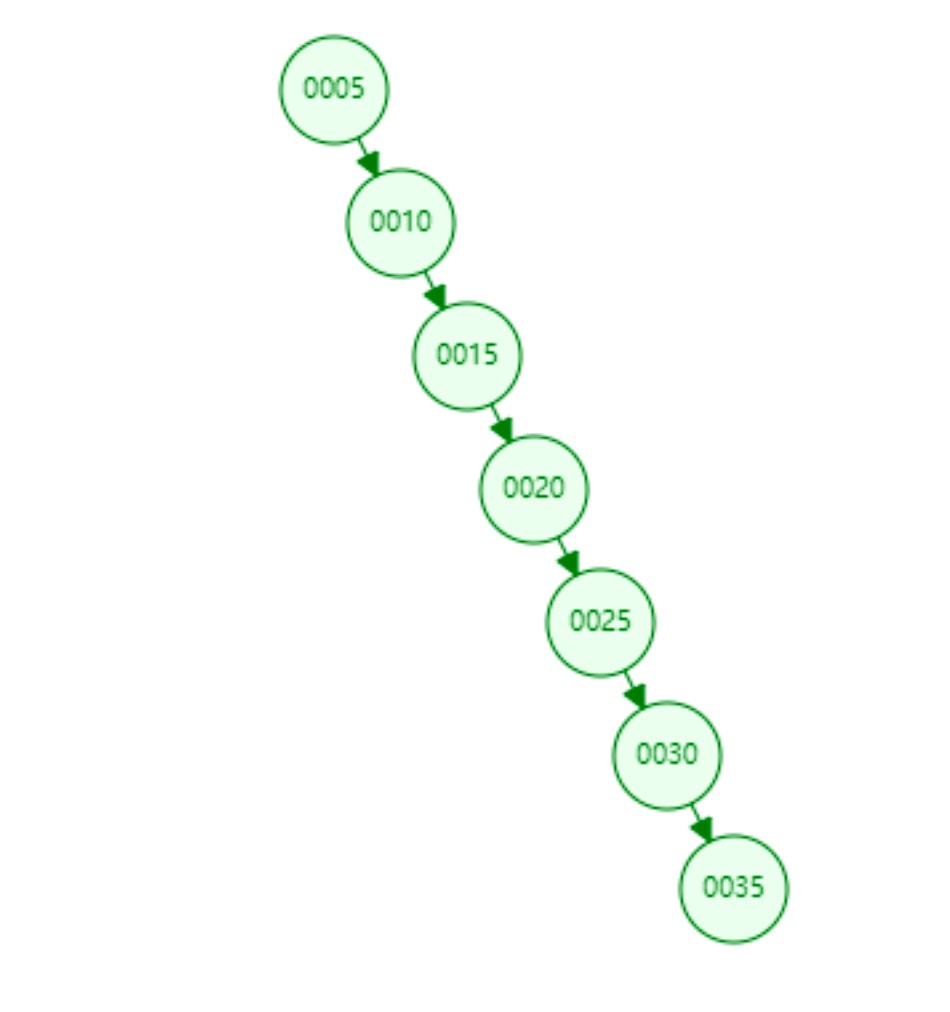
二叉树退化为了一个链表结构,查询数据最差就变为了O(N)。
二叉树的优缺点:
- 查询数据的效率不稳定,若树左右比较平衡的时,最差情况为O(logN),如果插入数据是有序的,退化为了链表,查询时间变成了O(N)
- 数据量大的情况下,会导致树的高度变高,如果每个节点对应磁盘的一个块来存储一条数据,需io次数大幅增加,显然用此结构来存储数据是不可取的
6、平衡二叉树(AVL树)
平衡二叉树是一种特殊的二叉树,所以他也满足前面说到的二叉查找树的两个特性,同时还有一个特性:
它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
平衡二叉树相对于二叉树来说,树的左右比较平衡,不会出现二叉树那样退化成链表的情况,不管怎么插入数据,最终通过一些调整,都能够保证树左右高度相差不大于1。
这样可以让查询速度比较稳定,查询中遍历节点控制在O(logN)范围内
如果数据都存储在内存中,采用AVL树来存储,还是可以的,查询效率非常高。不过我们的数据是存在磁盘中,用过采用这种结构,每个节点对应一个磁盘块,数据量大的时候,也会和二叉树一样,会导致树的高度变高,增加了io次数,显然用这种结构存储数据也是不可取的。
7、B-树
B杠树 ,千万不要读作B减树了,B-树在是平衡二叉树上进化来的,前面介绍的几种树,每个节点上面只有一个元素,而B-树节点中可以放多个元素,主要是为了降低树的高度。
一棵m阶的B-Tree有如下特性【特征描述的有点绕,看不懂的可以跳过,看后面的图】:
- 每个节点最多有m个孩子,m称为b树的阶
- 除了根节点和叶子节点外,其它每个节点至少有Ceil(m/2)个孩子(Ceil函数向上取整)
- 若根节点不是叶子节点,则至少有2个孩子
- 所有叶子节点都在同一层,且不包含其它关键字信息
- 每个非终端节点包含n个关键字(健值)信息
- 关键字的个数n满足:ceil(m/2)-1 <= n <= m-1
- ki(i=1,…n)为关键字,且关键字升序排序
- Pi(i=1,…n)为指向子树根节点的指针。P(i-1)指向的子树的所有节点关键字均小于ki,但都大于k(i-1)
B-Tree结构的数据可以让系统高效的找到数据所在的磁盘块。为了描述B-Tree,首先定义一条记录为一个二元组[key, data] ,key为记录的键值,对应表中的主键值,data为一行记录中除主键外的数据。对于不同的记录,key值互不相同。
B-Tree中的每个节点根据实际情况可以包含大量的关键字信息和分支,如下图所示为一个3阶的B-Tree: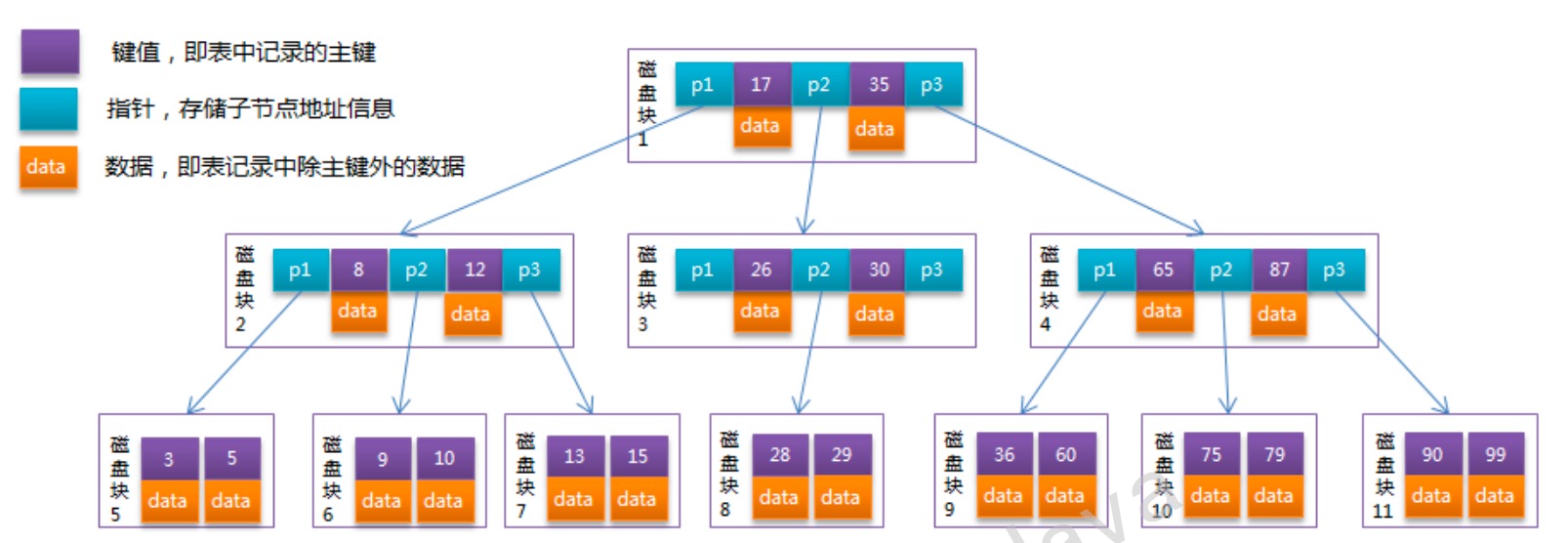
每个节点占用一个盘块的磁盘空间,一个节点上有两个升序排序的关键字和三个指向子树根节点的指针,指针存储的是子节点所在磁盘块的地址。两个键将数据划分成的三个范围域,对应三个指针指向的子树的数据的范围域。以根节点为例,关键字为17和35,P1指针指向的子树的数据范围为小于17,P2指针指向的子树的数据范围为17~35,P3指针指向的子树的数据范围为大于35。
模拟查找关键字29的过程:
- 根据根节点找到磁盘块1,读入内存。【磁盘I/O操作第1次】
- 比较关键字29在区间(17,35),找到磁盘块1的指针P2
- 根据P2指针找到磁盘块3,读入内存。【磁盘I/O操作第2次】
- 比较关键字29在区间(26,30),找到磁盘块3的指针P2
- 根据P2指针找到磁盘块8,读入内存。【磁盘I/O操作第3次】
- 在磁盘块8中的关键字列表中找到关键字29
分析上面过程,发现需要3次磁盘I/O操作,和3次内存查找操作,由于内存中的关键字是一个有序表结构,可以利用二分法快速定位到目标数据,而3次磁盘I/O操作是影响整个B-Tree查找效率的决定因素。B-树相对于avl树,通过在节点中增加节点内部数据的个数来减少磁盘的io操作。
上面我们说过mysql是采用页方式来读写数据,每页是16KB,我们用B-树来存储mysql的记录,每个节点对应mysql中的一页(16KB),假如每行记录加上树节点中的1个指针占160Byte,那么每个节点可以存储1000(16KB/160byte)条数据,树的高度为3的节点大概可以存储(第一层1000+第二层1000的2次方+第三层1000的3次方)10亿条记录,是不是非常惊讶,一个高度为3个B-树大概可以存储10亿条记录,我们从10亿记录中查找数据只需要3次io操作可以定位到目标数据所在的页,而页内部的数据又是有序的,然后将其加载到内存中用二分法查找,是非常快的。
- InnoDB存储引擎的最小存储单元是页,页可以用于存放数据也可以用于存放键值+指针,在B+树中叶子节点存放数据,非叶子节点存放键值+指针。
- 索引组织表通过非叶子节点的二分查找法以及指针确定数据在哪个页中,进而在去数据页中查找到需要的数据;
那么回到我们开始的问题,通常一棵B-树可以存放多少行数据?
这里我们先假设B+树高为2,即存在一个根节点和若干个叶子节点,那么这棵B+树的存放总记录数为:根节点指针数*单个叶子节点记录行数。
上文我们已经说明单个叶子节点(页)中的记录数=16K/1K=16条。(这里假设一行记录的数据大小为1k,实际上现在很多互联网业务数据记录大小通常就是1K左右)。
那么现在我们需要计算出非叶子节点能存放多少指针?
其实这也很好算,我们假设主键ID为bigint类型,长度为8字节,而指针大小在InnoDB源码中设置为6字节,这样一共14字节,我们一个页中能存放多少这样的单元,其实就代表有多少指针,即16*1024 =16384, 16384/14=1170。那么可以算出一棵高度为2的B+树,能存放1170*16=18720条这样的数据记录。根据同样的原理我们可以算出一个高度为3的B-树可以存放:1170*1170*16=21902400条这样的记录。
可以看出使用B-树定位某个值还是很快的(10亿数据中3次io操作+内存中二分法),但是也是有缺点的:
- B-不利于范围查找,比如上图中我们需要查找[15,36]区间的数据,需要访问7个磁盘块(1/2/7/3/8/4/9),io次数又上去了,范围查找也是我们经常用到的,所以]b-树也不太适合在磁盘中存储需要检索的数据。
8、B+树
先看个b+树结构图:
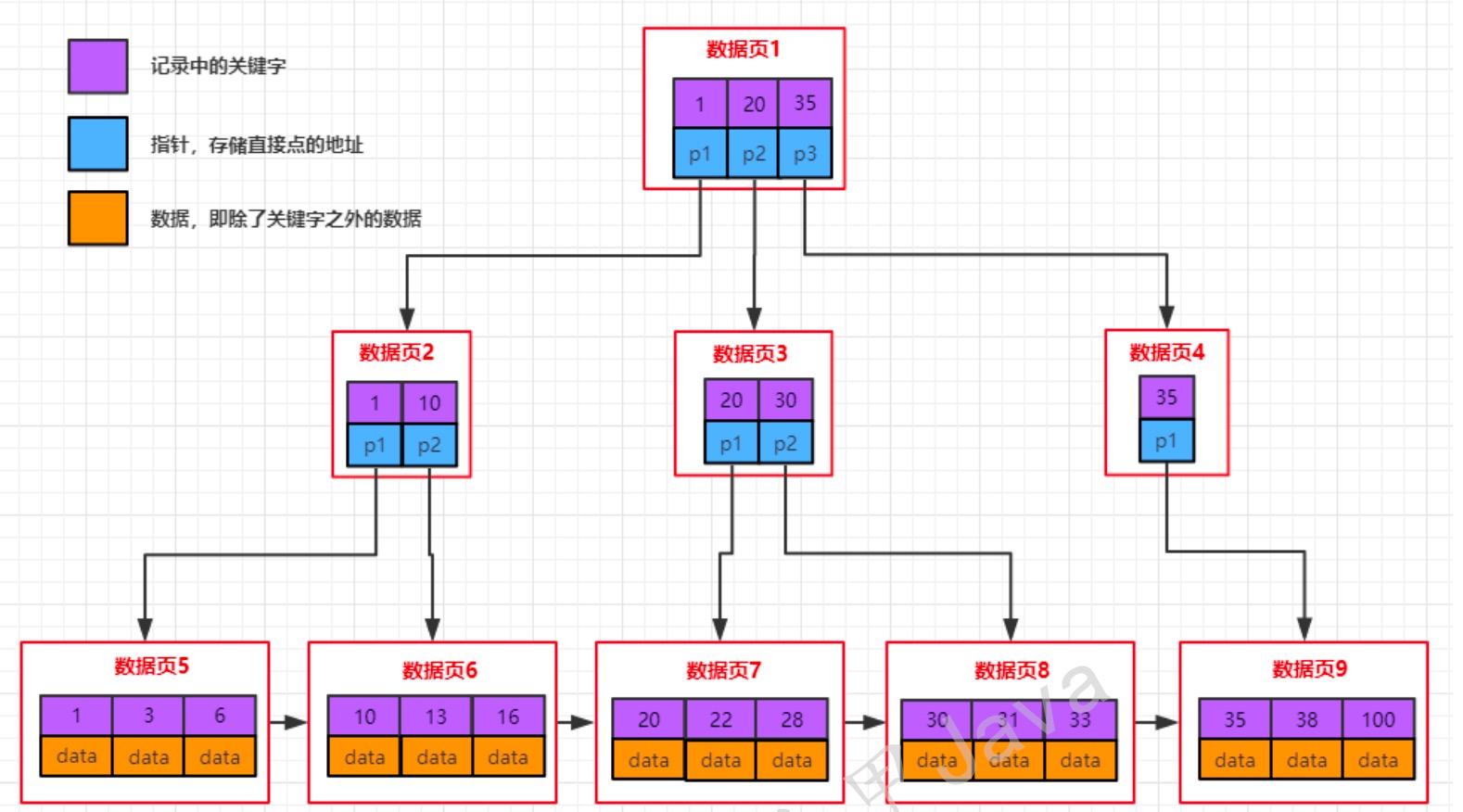
b+树的特征
- 每个结点至多有m个子女
- 除根结点外,每个结点至少有[m/2]个子女,根结点至少有两个子女
- 有k个子女的结点必有k个关键字
- 父节点中持有访问子节点的指针
- 父节点的关键字在子节点中都存在(如上面的1/20/35在每层都存在),要么是最小值,要么是最大值,如果节点中关键字是升序的方式,父节点的关键字是子节点的最小值
- 最底层的节点是叶子节点
- 除叶子节点之外,其他节点不保存数据,只保存关键字和指针
- 叶子节点包含了所有数据的关键字以及data,叶子节点之间用链表连接起来,可以非常方便的支
持范围查找
b+树与b-树的几点不同:
- b+树中一个节点如果有k个关键字,最多可以包含k个子节点(k个关键字对应k个指针);而b-树对应k+1个子节点(多了一个指向子节点的指针)
- b+树除叶子节点之外其他节点值存储关键字和指向子节点的指针,而b-树还存储了数据,这样同样大小情况下,b+树可以存储更多的关键字
- b+树叶子节点中存储了所有关键字及data,并且多个节点用链表连接,从上图中看子节点中数据从左向右是有序的,这样快速可以支撑范围查找(先定位范围的最大值和最小值,然后子节点中依靠链表遍历范围数据)
B-Tree和B+Tree该如何选择?
B-Tree因为非叶子结点也保存具体数据,所以在查找某个关键字的时候找到即可返回。而B+Tree所有的数据都在叶子结点,每次查找都得到叶子结点。所以在同样高度的B-Tree和B+Tree中,BTree查找某个关键字的效率更高
由于B+Tree所有的数据都在叶子结点,并且结点之间有指针连接,在找大于某个关键字或者小于某个关键字的数据的时候,B+Tree只需要找到该关键字然后沿着链表遍历就可以了,而B-Tree还需要遍历该关键字结点的根结点去搜索。
由于B-Tree的每个结点(这里的结点可以理解为一个数据页)都存储主键+实际数据,而B+Tree非叶子结点只存储关键字信息,而每个页的大小有限是有限的,所以同一页能存储的B-Tree的数据会比B+Tree存储的更少。这样同样总量的数据,B-Tree的深度会更大,增大查询时的磁盘I/O次数,进而影响查询效率。
以上是关于B-/B+树作为Mysql索引数据结构的区别的主要内容,如果未能解决你的问题,请参考以下文章