python 人生苦短,我学Python
Posted IT_Holmes
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 人生苦短,我学Python相关的知识,希望对你有一定的参考价值。
文章目录
1. Python 函数
函数可以说非常熟悉了,在java,js中都是重要的存在,熟读下图内容。

2. 函数参数

定义形参可以指定默认值

位置参数就是将对应位置的实参复制给对应位置的形参

关键字参数,关键字参数可以不按照形参定义的顺序去传递,而直接根据参数名去传递参数。
a = 2;
b = 3;
c = 4;
def f(a,b,c):
print(a); # 2
print(b); # 3
print(c); # 4
f(b=b,a=a,c=c);
位置参数和关键字参数可以混合使用,但是不推荐,容易报错。
混合使用关键字和位置参数时,必须将位置参数写到前面。

4. 函数实参
函数再调用时,解析器不会检查实参的类型。
实参可以传递任意类型的对象。

在函数中,也会涉及到一个改变量(value)还是改变象(对象)的问题。
改变量,在函数中对形参进行重新赋值,不会影响其他的变量。
def f(a):
a = 20; # 对它的值赋值,不会改变c。
print('a=',a,id(a)); # a= 20 140705421728112
c = 10;
f(c);
print('c=',c,id(c)); # c= 10 140705421727792
改变象,如果形参执行的是一个对象,当我们去通过形参修改对象内容时,会影响到所有指向该对象的变量。
def f(a):
a[0] = 30; # 修改对象中的内容,就会改变c,因为它们的物理地址一样。
print('a=',a,id(a)); # a= [30, 2, 3] 3005567789632
c = [1,2,3];
f(c);
print('c=',c,id(c)); # c= [30, 2, 3] 3005567789632
对于上面这样的情形,如果我们想要满足a[0] = 30,并且不对c进行修改。
我们可以通过c.copy()或c[:]切片来操作它。
def f(a):
a = [4,5,6];
print('a=',a,id(a)); # a= [4, 5, 6] 2378783846592
c = [1,2,3];
# f(c[:]) # 通过切片操作。
f(c.copy()); # 通过copy()操作。
print('c=',c,id(c)); # c= [1, 2, 3] 2378754484800
5. 不定长的参数
在定义函数时,可以在形参前边加上一个 * ,这样这个形参将会获取到所有的实参。它将会将所有的实参保存到一个元组中。
def f(a,b,*c):
print(a); # 1
print(b); # 2
print(c,type(c)); # (3, 4, 5, 6) <class 'tuple'>
f(1,2,3,4,5,6);

注意:
- 带 * 号的参数只能有一个。
- 可变参数不是必须写在后面,但是注意,带 * 的参数后的所有参数,必须以关键字参数的形式传递。

如果在形参开头直接写一个 *号,则要求我们的所有的参数必须以关键字参数的形式传递。

* 形参只能接受位置参数,而不能接受关键字参数,如下:就会报错,因为没法接受关键字参数。
def f(*c):
print(c,type(c)); # TypeError: f() got an unexpected keyword argument 'a'
f(a=1,b=2,c=3);
为了解决上面的情况,还有一种**形参,它可以接受其他关键字参数,并且返回的时dict字典。字典的key键就是参数的名字,字典的值就是参数的value值
def f(**c):
print(c,type(c)); # TypeError: f() got an unexpected keyword argument 'a'
f(a=1,b=2,c=3);
注意:
- **形参只能有一个。
- 必须写在所有参数的最后。
6. 参数的解包(拆包)
如果我们要通过一个元组等形式,想让里面的元素来传递实参时,也可以在序列类型的参数前添加 * 号,这样它会自动将序列中的元素一次作为参数传递。
def f(a,b,c):
print(a); # 10
print(b); # 20
print(c); # 30
t = (10,20,30); # 这里要求序列中元素的个数(实参)必须和形参的个数一致,不然报错。
f(*t);
通过使用 ** 来对一个字典进行解包操作。
def f(a,b,c):
print(a,b,c);
t = {'a':100,'b':200,'c':300};
f(*t); # 得到键 a b c
f(**t); # 得到值 100 200 300
7. 函数的返回值
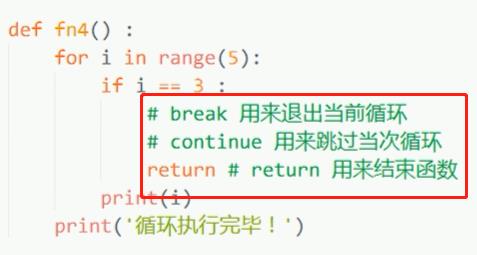
- 使用return ,定义返回值。
- 返回值可以是任意类型,甚至可以是一个函数。
- 如果仅仅写一个return 或者 不写return ,则相当于return None。
- 在函数中,return后的代码都不会执行。return 一旦执行函数自动结束。
- 注意调用函数和打印函数的区别。如下图:

8. 文档字符串
help()是Python的内置函数,通过help()函数可以查询python中的函数的用法。
语法:
help(函数对象); //例如:help(print);

9. 作用域

global关键字,来声明变量,在函数内部修改全局变量。
a = 20;
def f():
global a; # 使用global 声明变量
a = 10;
print(a); # 10
f();
print(a); # 10
10. 命名空间(namespace)
- 命名空间指的是变量存储的位置,每一个变量都需要存储到指定的命名空间当中。
- 每一个作用域都会又一个它对应的命名空间。
- 全局命名空间,用来保存全局变量。函数命名空间用来保存函数中的变量。
- 命名空间实际上就是一个字典,是一个专门用来存储变量的字典。
- 使用locals()用来获取当前作用域的命名空间。
全局命名空间:
- 向全局命名空间字典中添加key-value就相当于在全局中创建了一个变量(一般不建议这么做,但是要懂!
- print(scope[‘a’]); # 在命名空间中,查看a变量。
a = 20;
scope = locals();
print(scope); # 打印全局命名空间
print(type(scope)); # 命名空间类型是dict 字典
print(scope['a']); # 在命名空间中,查看a变量。
scope['c'] = 1000; # 向字典中添加key-value就相当于在全局中创建了一个变量(一般不建议这么做,但是要懂!)
print(scope);
函数命名空间:
- 和全局空间差不多,只不过是在函数内部。
- 注意的是,globals()函数可以用来在任意位置获取全局命名空间。
a = 10;
scope = locals();
scope['c'] = 1234;
def f():
global_scope = globals();
print(global_scope); # 在函数内部获取全局命名空间内容
print(global_scope['a']); # 也可以查看全局命名空间的内容
global_scope['f'] = 123456; # 也可以修改全局命名空间的内容
print(global_scope);
f();
11. 递归(recursion)
递归式函数,意思就是自己调用自己来完成。


看懂就行,了解好下面的例子:
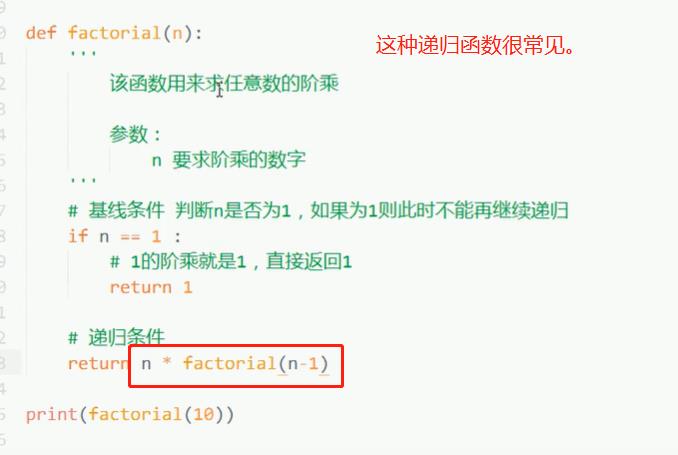
注意的错误:RecursionError: maximum recursion depth exceeded in comparison,递归错误:比较中超出了最大递归深度。
12. 高阶函数
一等对象,高阶函数定义:

filter()函数:从序列中过滤出符合条件的元素,保存到一个新的序列中。

filter使用案例,像这种有boolean判断返回值的,就要用到filter()函数。
l = {1,2,3,4,5};
def fun(i):
if i % 2 == 0:
return True;
return False;
# fun作为一个参数,传递给filter()函数中。
a = filter(fun,l); # 注意:这里fun不能加括号,这里不是调用,而是要这个函数原型。
print(a); # <filter object at 0x000002BB30367FD0>
print(list(a)); # [2, 4] ,这里最后要转换一些称为列表才能看到数值。
13. 匿名函数 lambda 函数表达式
lambda函数表达式专门用来创建一些简单的函数,它是函数创建的又一种方式。
具体的匿名函数使用方法如下四种:
第一种方式:(lambda a,b : a+b)(10,20) ,不推荐
# def fun(a,b):
# return a+b;
# lambda a,b : a+b ,这种式子和上面的式子是等价的
# (lambda a,b : a+b)(10,20) # 可以通过这种方式添加参数(不推荐)
print((lambda a,b : a+b)(10,20)) ;
第二种方式:func = lambda a,b : a+b; 通过赋值方式来操作,一般不会这么做。
# def fun(a,b):
# return a+b;
func = lambda a,b : a+b; # 也可以通过赋值方式来操作
print(func(10,20));
第三种方式:配合filter()函数使用,挑出符合条件的元素,并返回新的对象。
# def fun(i):
# return i % 3 ==0;
l = {1,2,3,4,5,6,7,8,9};
r = filter((lambda i : i % 3 == 0),l);
print(r,list(r));
第四种方式:配合map()函数使用,对元素进行修改,并返回新的对象。
map()函数:可以对可跌倒对象中的所有元素做指定的操作,然后将其添加到一个新的对象中返回。
l = [1,2,3,4,5,6];
r = map(lambda i:i+1,l);
print(r,list(r)); # <map object at 0x00000235240A70A0> [2, 3, 4, 5, 6, 7]
匿名函数一般都作为参数使用。就像filter和map函数这样操作。
14. xxx.sort() 和 sorted(xxx)函数
14.1 xxx.sort()函数
- sort()方法用来对列表中的元素进行排序。
- sort()方法默认是直接比较列表中的元素大小。
- 但sort()可以接受一个关键字参数:key。
- key需要一个函数作为参数,当设置了函数作为参数,每次都会以列表中的一个元素作为参数来调用给该函数,并且使用函数的返回值来比较元素的大小。
转换为int,str等等类型,再比较。
l = ['6',2,5,'4','1',3];
l.sort(key=str); # 将元素内部数据转为字符串形式,进行比较
print(l); # ['1', 2, 3, '4', 5, '6']
也可以自己创建函数,进行比较。
students = [{"age": 15, "name": 'tom', "score": 98},
{"age": 16, "name": 'mike', "score": 98},
{"age": 18, "name": 'jack', "score": 89},
{"age": 19, "name": 'jone', "score": 95}];
students.sort(key=lambda student: student['score']);
print(students);
### [{'age': 18, 'name': 'jack', 'score': 89},
### {'age': 19, 'name': 'jone', 'score': 95},
### {'age': 15, 'name': 'tom', 'score': 98},
### {'age': 16, 'name': 'mike', 'score': 98}]
14.2 sorted(xxx)函数
- sorted排序不会影响原来的对象,而是返回一个新对象。

l = '112345347594234';
a = sorted(l,key=int);
print(l);# 不会改变原来的值
print(a);# 返回一个新的对象给a
# 112345347594234
# ['1', '1', '2', '2', '3', '3', '3', '4', '4', '4', '4', '5', '5', '7', '9']
15. 闭包
- 将函数作为返回值返回,也是一种高阶函数。
- 就像上面这种高阶函数,我们也成为闭包。如下:

- 通过闭包可以创建一些只有当前函数能访问的变量。可以将一些私有的数据藏到闭包中。
sum()函数用来求列表中所有元素的和。
nums = [20,30,40,50];
print(sum(nums)/len(nums)); # 35.0
形成闭包的必要条件:
- 函数嵌套。
- 将内部函数作为返回值返回。
- 内部函数必须要使用到外部函数的变量。(如下:make_averager()函数是外部函数,averager()函数是内部函数。)
def make_averager():
nums = [];
def averager(n):
nums.append(n);
return sum(nums)/len(nums);
return averager;
# averager名字一样无所谓,因为作用域不同
averager = make_averager();
# 从上面就可以看出nums是定义在函数内部,而外部不能访问。
print(averager(10));
print(averager(20));
print(averager(30));
print(averager(40));
16. 装饰器
16.1 函数拓展
如下方式:
def add(a,b):
return a+b;
def new_add(a,b):
print('计算开始~~');
r = add(a,b);
print('计算结束~~');
return r;
# r 名字一样无所谓,因为作用域不同
r = new_add(3,4);
print(r);
16.2 装饰器拓展(重要)
- 像下面的begin_end这种函数就是装饰器。
- 装饰器就是传入函数,对函数进行修改更新。
- 在开发中,我们都是通过装饰器来扩展函数的功能的。
def add(a,b):
return a+b;
def begin_end(old):
# *args可以接受任意的位置参数,**kwargs可以接受任意的关键字参数
def new_function(*args,**kwargs):
print('开始执行~~~');
result = old(*args,**kwargs);
print('执行结束~~~');
return result;
return new_function;
f = begin_end(add); # 将函数传给begin_add函数
print(f(123,456));
# 上面的begin_end这种函数就是装饰器。
- 通过@begin_end来装饰函数。
def begin_end(old):
# *args可以接受任意的位置参数,**kwargs可以接受任意的关键字参数
def new_function(*args,**kwargs):
print('开始执行~~~');
result = old(*args,**kwargs);
print('执行结束~~~');
return result;
return new_function;
# 定义begin_end来装饰say_hello函数
@begin_end
def say_hello():
print('大家好~~');
say_hello();
- 可以同时为一个函数指定多个装饰器,这样函数会由内向外的顺序进行装饰。

以上是关于python 人生苦短,我学Python的主要内容,如果未能解决你的问题,请参考以下文章