目标检测yolo系列—yolo_v4学习记录
Posted 超级无敌陈大佬的跟班
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了目标检测yolo系列—yolo_v4学习记录相关的知识,希望对你有一定的参考价值。
目录
文章参考自知乎作者的文章,作为学习笔记记录。参考链接:https://zhuanlan.zhihu.com/p/143747206
前言
目标检测模型调优的两种手段
目标检测的调优技巧主要分类下面两种:“Bag of freebies(免费礼包)”和“Bag of specials(特价包)”
- 手段1:Bag of freebies
是指在离线训练阶段为了提升精度而广泛使用的调优手段,而这种技巧并不在推理时使用,不会增加推理时间。
1)数据类:
- 数据增强(random erase/CutOut/hide-and-seek/grid mask/MixUp/CutMix/GAN)
- 数据分布:two-stage的有难例挖掘,one-stage的有focal loss。
2)特征图类:
- DropOut/DropConnect/DropBlock
3)Bounding Box目标函数类:
- MSE/ IoU loss/l1、l2 loss/GIoU loss/DIoU loss/CIoU loss:
- 手段2:Bag of specials
是指在推断过程中增加的些许成本但能换来较大精度提升的技巧。
1)增大感受野类:
SPP/ASPP/RFB
2)注意力类:
Squeeze-and-Excitation (SE)/Spa-tial Attention Module (SAM)
3)特征集成类:
SFAM/ASFF/BiFPN
4)激活函数类:
ReLu/LReLU/PReLU/ReLU6/Scaled ExponentialLinear Unit (SELU)/Swish/hard-Swish/Mish
5)后处理类:
soft NMS/DIoU NMS
一、YOLO-v4的主要工作
通俗的讲,YOLO-v4算法是在原有YOLO目标检测架构的基础上,采用了近些年CNN领域中最优秀的优化策略,从数据处理、主干网络、网络训练、激活函数、损失函数等各个方面都有着不同程度的优化,虽没有理论上的创新,但是会受到许许多多的工程师的欢迎,各种优化算法的尝试。文章如同于目标检测的trick综述,效果达到了实现FPS与Precision平衡的目标检测 new baseline。
yolov4网络结构
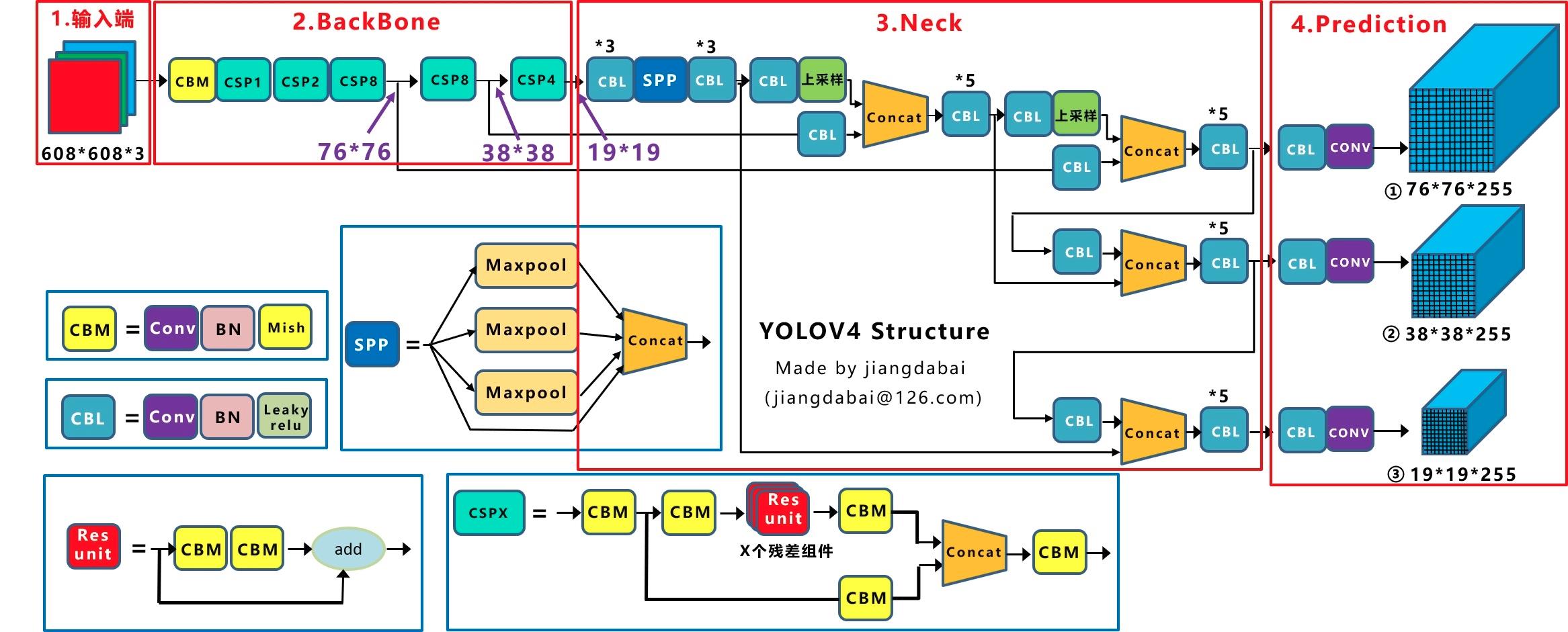
Yolov4的结构图和Yolov3相比,因为多了CSP结构,PAN结构。
先整理下Yolov4的五个基本组件:
- CBM:Yolov4网络结构中的最小组件,由Conv+Bn+Mish激活函数三者组成。
- CBL:由Conv+Bn+Leaky_relu激活函数三者组成。
- Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
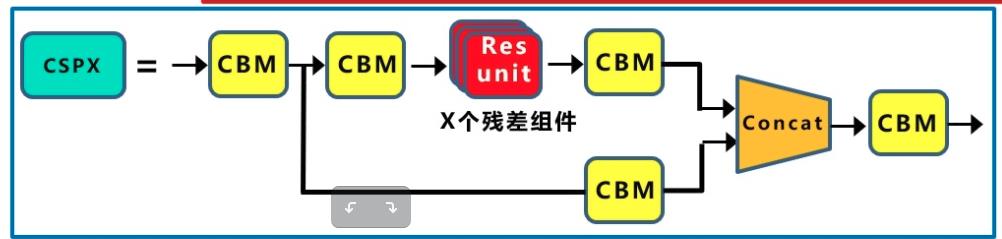
- CSPX:借鉴CSPNet网络结构,由卷积层和X个Res unint模块Concate组成。
- SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合。
其他基础操作:
- Concat:张量拼接,维度会扩充,和Yolov3中的解释一样,对应于cfg文件中的route操作。
- add:张量相加,不会扩充维度,对应于cfg文件中的shortcut操作。
Backbone中卷积层的数量:
yolov4中Backbone里面的卷积层数量,每个CSPX中包含5+2*X个卷积层,因此整个主干网络Backbone中一共包含1+(5+2*1)+(5+2*2)+(5+2*8)+(5+2*8)+(5+2*4)=72。
二、yolo_v4改进创新之处:
从网络4个部分对YoloV4的创新之处进行讲解:
- 输入端:这里指的创新主要是训练时对输入端的改进,主要包括Mosaic数据增强、cmBN、SAT自对抗训练
- BackBone主干网络:将各种新的方式结合起来,包括:CSPDarknet53、Mish激活函数、Dropblock
- Neck:目标检测网络在BackBone和最后的输出层之间往往会插入一些层,比如Yolov4中的SPP模块、FPN+PAN结构
- Prediction:输出层的锚框机制和Yolov3相同,主要改进的是训练时的损失函数CIOU_Loss,以及预测框筛选的nms变为DIOU_nms
2.1 输入端创新
1)Mosaic数据增强
Yolov4中使用的Mosaic是参考2019年底提出的CutMix数据增强的方式,但CutMix只使用了两张图片进行拼接,而Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接。

Mosaic增强的主要优点:
- 丰富数据集:随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好。
- 减少GPU:同时Mosaic增强训练时,可以直接计算4张图片的数据,使得Mini-batch大小并不需要很大,一个GPU就可以达到比较好的效果。
2.2 BackBone创新
1)CSPDarknet53
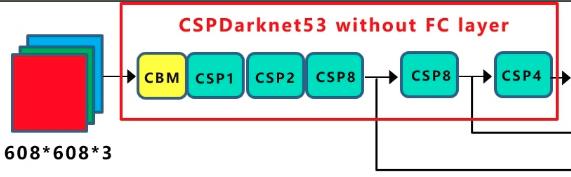
如上图所示,yolo_v4的backbone使用了5个CSP模块。每个CSP模块都有一个stride=2的卷积实现下采样操作,输入图像是608*608,所以特征图变化的规律是:608->304->152->76->38->19;
CSP全称Cross Stage Paritial,主要从网络结构设计的角度解决推理中从计算量很大的问题。CSPNet的作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的。因此采用CSP模块先将基础层的特征映射划分为两部分,然后通过跨阶段层次结构将它们合并,在减少了计算量的同时可以保证准确率。
个人理解:传统的ResNet或DenseNet的跨卷积连接操作,会使得大量的梯度信息被重复用来更新权重,CSP这里的操作是将当前featuremap层的特征维度拆成两半,一半走conv操作,另一半直接跨越连接过来,这样两条路线就没有使用相同的特征,不会导致梯度信息重复。
CSP好处:降低内存成本。
2)Mish激活函数

Yolov4的Backbone中都使用了Mish激活函数,而后面的网络则还是使用leaky_relu函数,猜测是Mish计算起来太麻烦了。
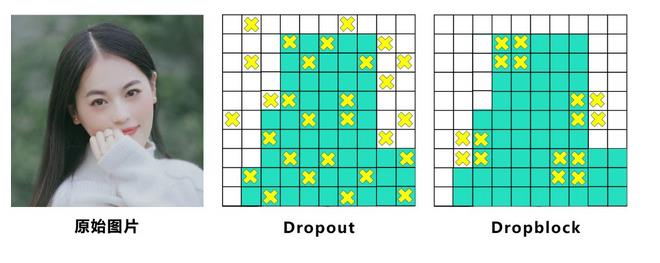
3)Dropblock
Dropblock的研究者认为,卷积层对于这种随机丢弃并不敏感,因为卷积层通常是三层连用:卷积+激活+池化层,池化层本身就是对相邻单元起作用。而且即使随机丢弃,卷积层仍然可以从相邻的激活单元学习到相同的信息。因此,在全连接层上效果很好的Dropout在卷积层上效果并不好。所以,Dropblock的研究者直接对整个局部区域进行删减丢弃。
优点:Dropblock有点类似于cutout数据增强,cutout是将输入图像的部分区域清零,而Dropblock则是将Cutout应用到每一个特征图,Yolov4中直接采用了更优的Dropblock,对网络的正则化过程进行了全面的升级改进。

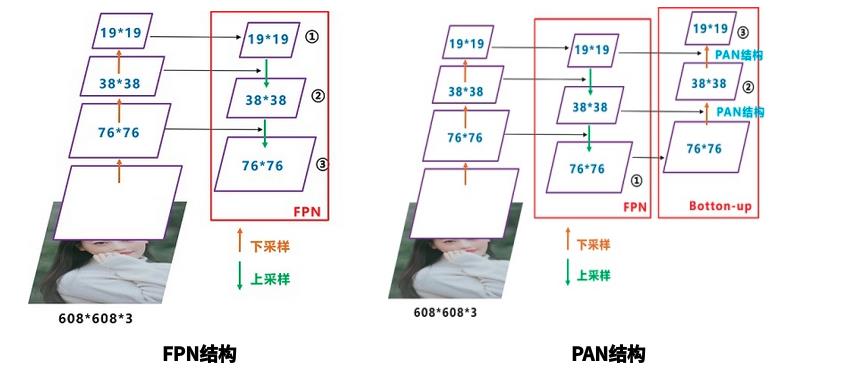
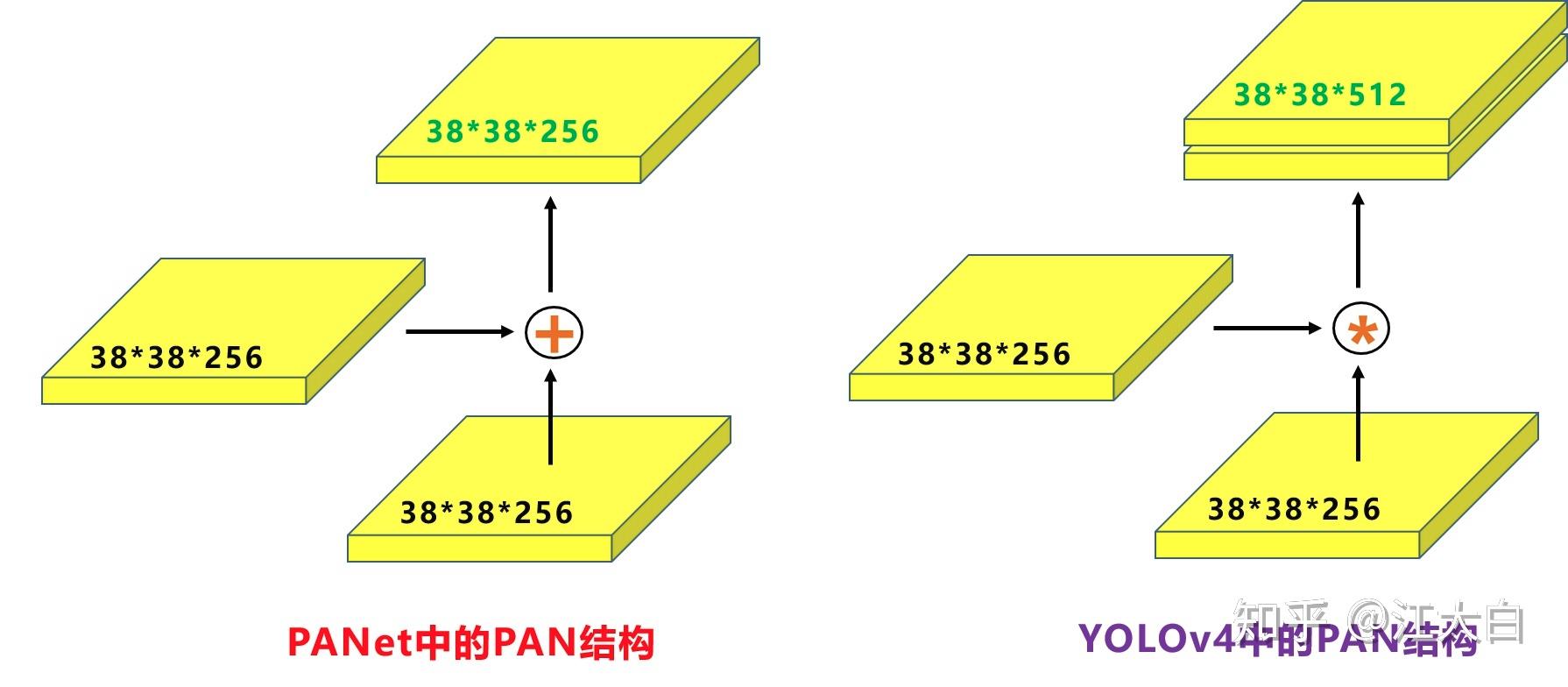
2.3 Neck结构中的创新
Yolov4的Neck结构主要采用了SPP模块、FPN+PAN(PAN其实就是从深层特征融合到浅层后,又下采样到深层...)方式。
1)SPP模块
SPP用处:融合不同尺度大小的感受野。
在SPP模块中,使用k={1*1, 5*5, 9*9, 13*13}的最大池化的方式,再将不同尺度的特征图进行Concat操作。注意:这里最大池化采用padding操作,移动的步长为1,比如13×13的输入特征图,使用5×5大小的池化核池化,padding=2,因此池化后的特征图仍然是13×13大小,也就是说这里的maxpool没有减小特征图的尺寸- -。

2)FPN + PAN
在FPN层的后面还添加了一个自底向上的特征金字塔。给我的感觉是特征图就下采采,上采采,融合融合,AP就涨点了...
2.4 Prediction部分的创新
1)CIOU_loss
Bounding Box Regeression的Loss近些年的发展过程是:Smooth L1 Loss-> IoU Loss(2016)-> GIoU Loss(2019)-> DIoU Loss(2020)->CIoU Loss(2020)
CIOU_Loss就将目标框回归函数应该考虑三个重要几何因素:重叠面积、中心点距离,长宽比全都考虑进去了。
各个Loss函数的不同点:
- IOU_Loss:主要考虑检测框和目标框重叠面积。
- GIOU_Loss:在IOU的基础上,解决边界框不重合时的问题。
- DIOU_Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
- CIOU_Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。
- Yolov4中采用了CIOU_Loss的回归方式,使得预测框回归的速度和精度更高一些。


2)DIOU_nms
将NMS过程中计算IOU的部分替换成上面DIOU的方式(考虑中心点的距离)。

在上图右边重叠的摩托车检测中,中间的摩托车因为考虑边界框中心点的位置信息,也可以回归出来。因此在重叠目标的检测中,DIOU_nms的效果优于传统的nms。
注意:有读者会有疑问,这里为什么不用CIOU_nms,而用DIOU_nms?
答:因为前面讲到的CIOU_loss,是在DIOU_loss的基础上,添加的影响因子,包含groundtruth标注框的信息,在训练时用于回归。但在测试过程中,并没有groundtruth的信息,不用考虑影响因子,因此直接用DIOU_nms即可。
Yolov4 主要带来了 3 点新贡献:
(1)提出了一种高效而强大的目标检测模型,使用 1080Ti 或 2080Ti 就能训练出超快、准确的目标检测器。
(2)在检测器训练过程中,验证了最先进的一些研究成果对目标检测器的影响。
(3)改进了 SOTA 方法,使其更有效、更适合单 GPU 训练。
三、网络精度指标
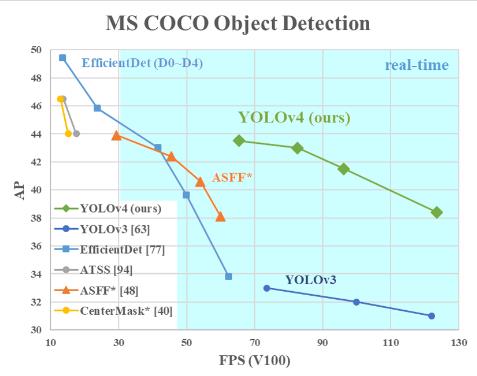
参考链接:https://blog.csdn.net/baobei0112/article/details/105831613/
以上是关于目标检测yolo系列—yolo_v4学习记录的主要内容,如果未能解决你的问题,请参考以下文章