如何获取web视频数据流的传输?小姐姐的视频都被我爬下来了,这谁顶得住
Posted 五包辣条!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何获取web视频数据流的传输?小姐姐的视频都被我爬下来了,这谁顶得住相关的知识,希望对你有一定的参考价值。
大家好,我是辣条。
效果展示
爬取目标
网站:六间房
工具使用
开发工具:pycharm 开发环境:python3.7, Windows10 使用工具包:requests,lxml
重点学习内容
-
动态数据抓取
-
requests使用
-
json数据获取
项目思路解析
第一步,明确自己需要获取的网页地址信息,要先清楚的自己的采集目标,今天采集的数据是六间房的小视频数据。
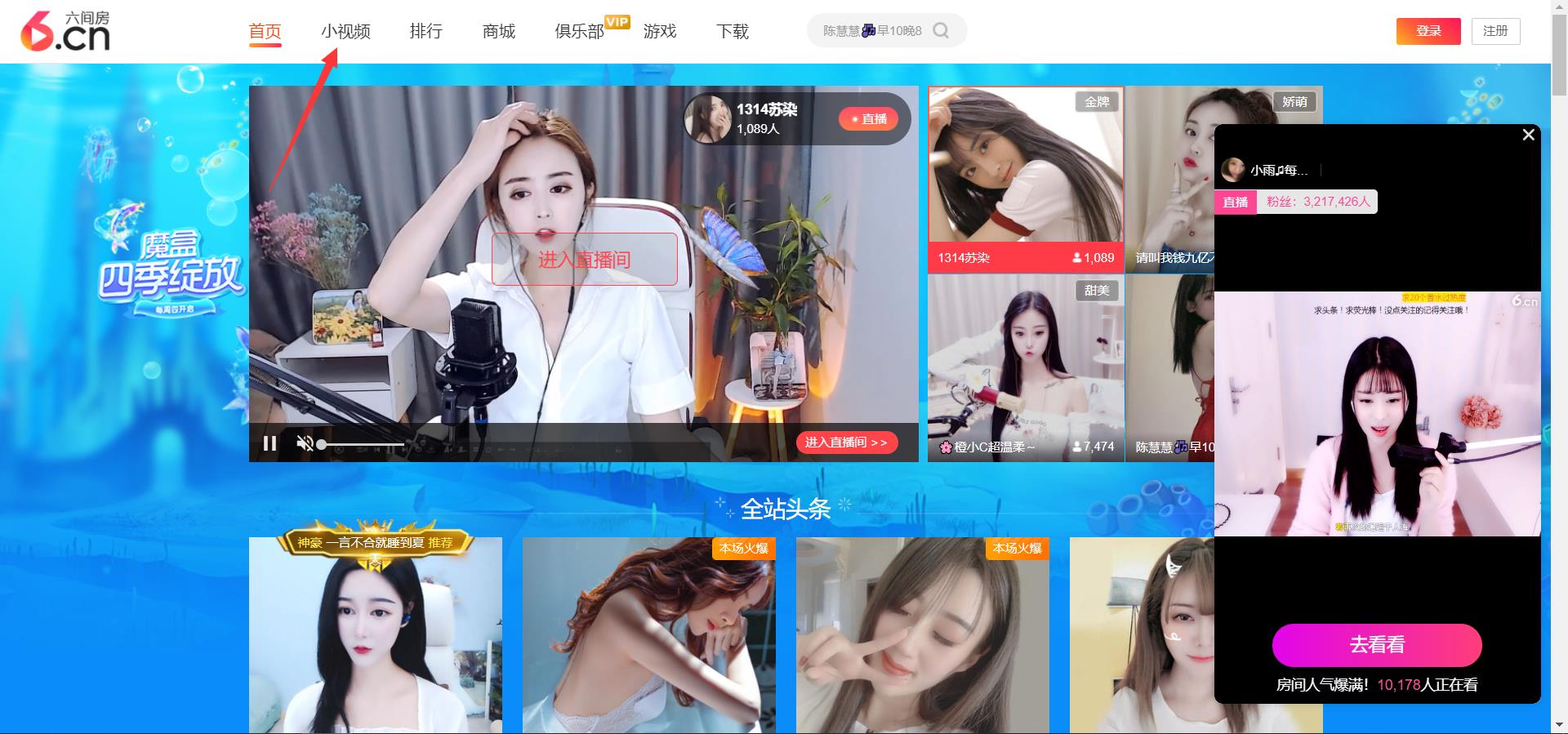
当前网页数据可以明显看出是动态数据,找到对应数据接口,获取到视频的播放地址,动态数据获取的话首先打开抓包工具 (爬虫必备技能就不做过多介绍) 刷新网页数据进行页面的数据加载,找到动态数据。
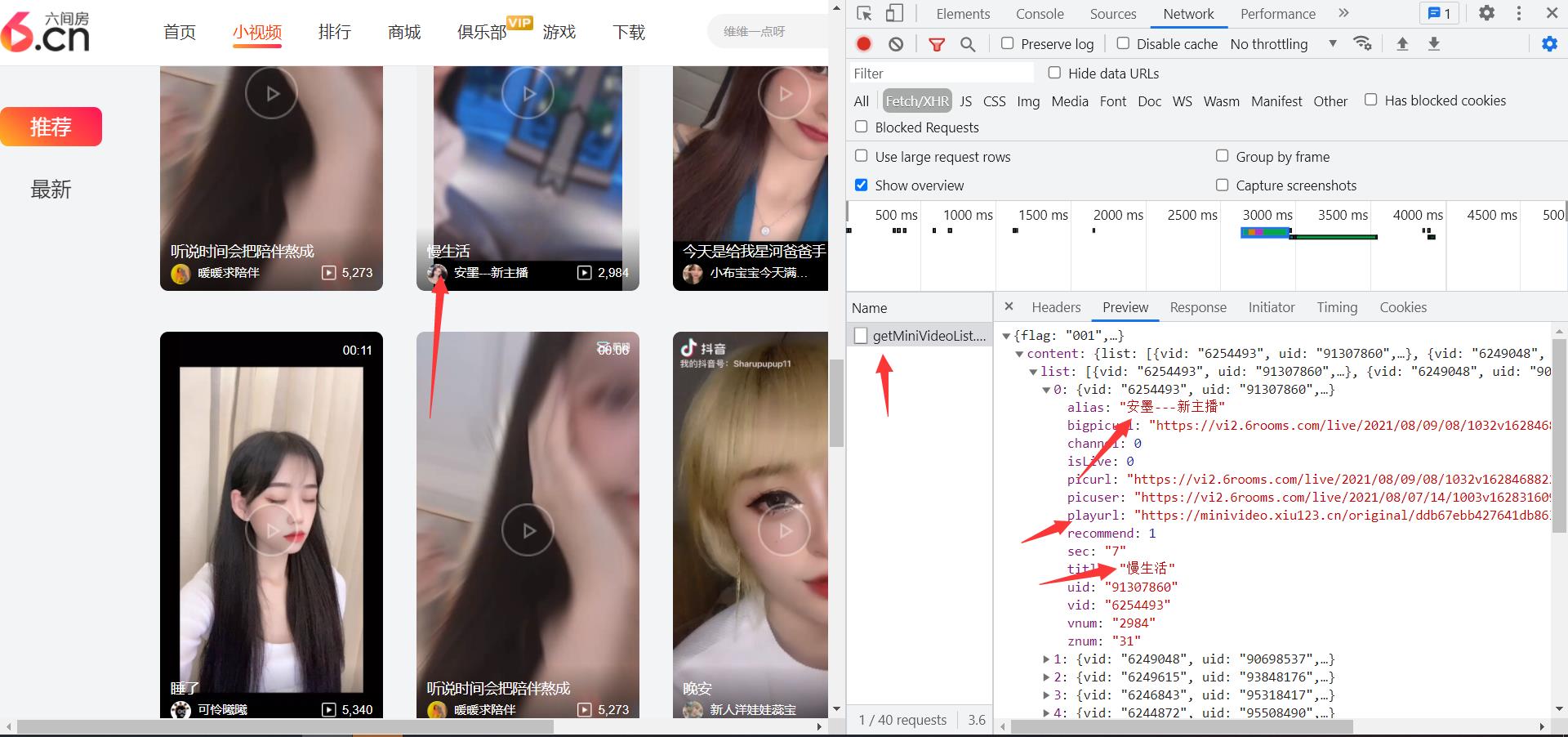
确定自己需要的数据,在headers里找到请求的url地址,对网址发送请求(尽量做爬虫的时候都带上请求头不要像我。。。 将数据转换成字典格式,取出字典里content里的list 循环取出列表每个视频数据,拿到数据里的视频播放地址和视频标题,保存对应视频数据。
简易源码分享
import requests
url = 'https://v.6.cn/minivideo/getMiniVideoList.php?act=recommend&page=1&pagesize=25'
response = requests.get(url).json()
content = response['content']['list']
for i in content:
playurl = i['playurl'] # 视频播放地址
title = playurl.split('-')[1] # 名称存储名称
# 视频下载
video = requests.get(playurl).content # 请求视频地址
# 文件存储 文件存储路径 文件读写方式 b 进制文件读写 a文件存在就追加 不存在就新建
f = open('./VIdeo/{}'.format(title), 'ab')
f.write(video)
f.close()
print('{}下载完成...'.format(title))最后给大家分享腾讯,阿里,字节跳动,很有意思的一张对比图!

从BAT到BAT,只是从Baidu换成了ByteDance,曾经的BTA,是PC时代的霸主,如今的BAT,是移动互联网的霸主。
二十世纪的,第一个十年,是靠搜索的百度国内称王,第二个十年,是靠算法的字节走向世界。
第三个十年,会是谁独树一帜站上顶点,又会是谁让位谁上位?
以上是关于如何获取web视频数据流的传输?小姐姐的视频都被我爬下来了,这谁顶得住的主要内容,如果未能解决你的问题,请参考以下文章