ElasticSearch聚合查询Restful语法和JavaApi详解(基于ES7.6)
Posted Java鱼仔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch聚合查询Restful语法和JavaApi详解(基于ES7.6)相关的知识,希望对你有一定的参考价值。
(一)概述
在前面关于ES的一系列文章中,已经介绍了ES的概念、常用操作、JavaAPI以及实际的一个小demo,但是在真实的应用场景中,还有可能会有更高阶的一些用法,今天主要介绍两种相对来说会更难一些的操作,聚合查询。该文档基于ElasticSearch7.6,将介绍restful查询语法以及JavaApi。
阅读本文需要你有ElasticSearch的基础。
(二)前期数据准备
这里准备了包含姓名、年龄、教室、性别和成绩五个字段的数据
PUT /test4
{
"mappings" : {
"properties" : {
"name" : {
"type" : "text"
},
"age":{
"type": "integer"
},
"classroom":{
"type": "keyword"
},
"gender":{
"type": "keyword"
},
"grade":{
"type": "integer"
}
}
}
}
PUT /test4/_bulk
{"index": {"_id": 1}}
{"name":"张三","age":18,"classroom":"1","gender":"男","grade":80}
{"index": {"_id": 2}}
{"name":"李四","age":20,"classroom":"2","gender":"男","grade":60}
{"index": {"_id": 3}}
{"name":"王五","age":20,"classroom":"2","gender":"女","grade":70}
{"index": {"_id": 4}}
{"name":"赵六","age":19,"classroom":"1","gender":"女","grade":90}
{"index": {"_id": 5}}
{"name":"毛七","age":20,"classroom":"1","gender":"男","grade":90}
(三)聚合查询
ES中的聚合操作提供了强大的分组及数理计算的能力,ES中聚合从大体上可以分为四种方式:
1、Metrics Aggregation 提供了诸如Max,Min,Avg的数值计算能力
2、Bucket Aggregation 提供了分桶的能力,简单来讲就是将一类相同的数据聚合到一起
3、Pipeline Aggregation 管道聚合,对其他聚合进行二次聚合
4、Matrix Aggregation 对多个字段进行操作并返回矩阵结果
ES官网提供了全部聚合查询文档,这篇文章将介绍常用的几种聚合查询的语法以及JavaApi:
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.6/java-rest-high-aggregation-builders.html#_metrics_aggregations
(四)Metrics Aggregation
4.1 AVG
avg用于计算聚合文档中提取的数值的平均值,restful查询语法如下:
POST /test4/_search
{
"aggs": {
"avg_grade": {
"avg": {
"field": "grade"
}
}
}
}
查询得到的结果如下:
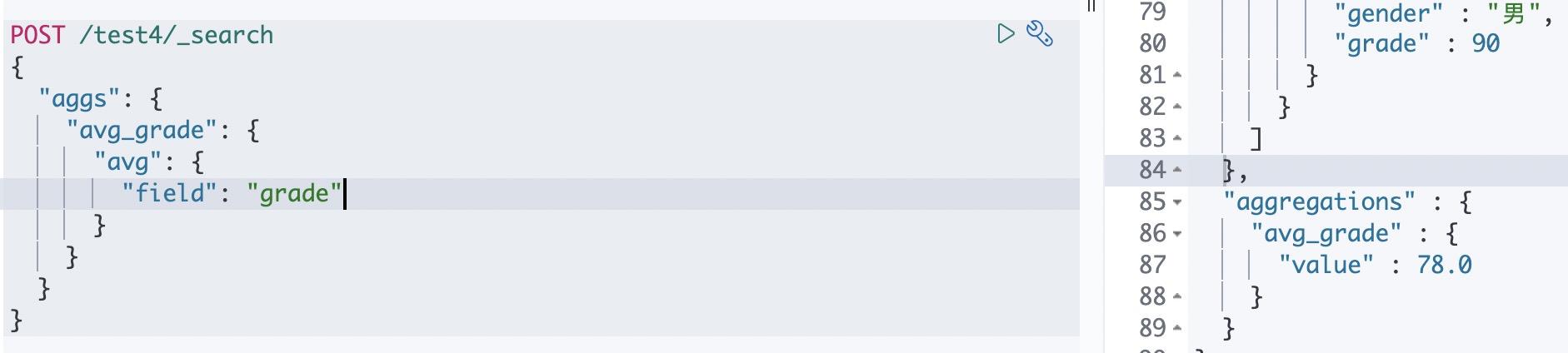
接着是JavaApi,核心在于使用AggregationBuilders的avg方法,第七行代码对应于上面的操作。
@Test
public void testAvg() throws Exception {
//封装了获取RestHighLevelClient的方法
RestHighLevelClient client=ElasticSearchClient.getClient();
SearchRequest request = new SearchRequest("test4");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.aggregation(AggregationBuilders.avg("agg_grade").field("grade")).size(0);
request.source(searchSourceBuilder);
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
//注意这里要把Aggregation类型转化为ParsedAvg类型
ParsedAvg aggregation = search.getAggregations().get("agg_grade");
System.out.println(aggregation.getValue()); //返回78.0
}
接下来就直接贴代码了
4.2 Min
获取聚合数据的最小值:
POST /test4/_search
{
"aggs": {
"min_grade": {
"min": {
"field": "grade"
}
}
}
}
@Test
public void testMin() throws Exception {
//封装了获取RestHighLevelClient的方法
RestHighLevelClient client=ElasticSearchClient.getClient();
SearchRequest request = new SearchRequest("test4");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.aggregation(AggregationBuilders.min("min_grade").field("grade")).size(0);
request.source(searchSourceBuilder);
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
ParsedMin aggregation = search.getAggregations().get("min_grade");
System.out.println(aggregation.getValue());
}
4.3 Max
获取聚合数据的最大值:
POST /test4/_search
{
"aggs": {
"max_grade": {
"max": {
"field": "grade"
}
}
}
}
@Test
public void testMax() throws Exception {
//封装了获取RestHighLevelClient的方法
RestHighLevelClient client=ElasticSearchClient.getClient();
SearchRequest request = new SearchRequest("test4");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.aggregation(AggregationBuilders.max("max_grade").field("grade")).size(0);
request.source(searchSourceBuilder);
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
ParsedMax aggregation = search.getAggregations().get("max_grade");
System.out.println(aggregation.getValue());
}
4.4 Sum
获取聚合数据的和:
POST /test4/_search
{
"aggs": {
"sum_grade": {
"sum": {
"field": "grade"
}
}
}
}
@Test
public void testSum() throws Exception {
//封装了获取RestHighLevelClient的方法
RestHighLevelClient client=ElasticSearchClient.getClient();
SearchRequest request = new SearchRequest("test4");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.aggregation(AggregationBuilders.sum("sum_grade").field("grade")).size(0);
request.source(searchSourceBuilder);
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
ParsedSum aggregation = search.getAggregations().get("sum_grade");
System.out.println(aggregation.getValue());
}
4.5 Stats
stats集成了上面的所有计算操作。
POST /test4/_search
{
"aggs": {
"stats_grade": {
"stats": {
"field": "grade"
}
}
}
}
@Test
public void testStats() throws Exception {
//封装了获取RestHighLevelClient的方法
RestHighLevelClient client=ElasticSearchClient.getClient();
SearchRequest request = new SearchRequest("test4");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.aggregation(AggregationBuilders.stats("sum_grade").field("grade")).size(0);
request.source(searchSourceBuilder);
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
ParsedStats aggregation = search.getAggregations().get("sum_grade");
System.out.println(aggregation.getMax());
System.out.println(aggregation.getAvg());
System.out.println(aggregation.getCount());
System.out.println(aggregation.getMin());
System.out.println(aggregation.getSum());
}
(五)Bucket Aggregation
桶聚合是按照某个字段将同类型的数据聚合为一类,最常用对桶聚合就是terms聚合了。
5.1 terms
terms查询类似于group by,返回查询字段分组后的值以及数量,比如我对classroom字段terms查询
POST /test4/_search
{
"aggs": {
"classroom_term": {
"terms": {
"field": "classroom"
}
}
}
}
返回值就是classroom的分组后的值以及每个组的数量:classroom是1的有3条记录,classroom是2的有2条记录
"aggregations" : {
"classroom_term" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "1",
"doc_count" : 3
},
{
"key" : "2",
"doc_count" : 2
}
]
}
我们也可以对多个字段进行terms分组,比如我现在对classroom和gender两个字段进行分组:
POST /test4/_search
{
"aggs": {
"classroom_term": {
"terms": {
"field": "classroom"
},
"aggs": {
"gender": {
"terms": {
"field": "gender"
}
}
}
}
}
}
最后对返回值就是classroom和gender分组后的值和数量:
classroom是1,gender是男有两条;
classroom是1,gender是女有一条;
classroom是2,gender是男有一条;
classroom是2,gender是女有一条;
"aggregations" : {
"classroom_term" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "1",
"doc_count" : 3,
"gender" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "男",
"doc_count" : 2
},
{
"key" : "女",
"doc_count" : 1
}
]
}
},
{
"key" : "2",
"doc_count" : 2,
"gender" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "女",
"doc_count" : 1
},
{
"key" : "男",
"doc_count" : 1
}
]
}
}
]
}
对应的JavaApi使用如下:
@Test
public void testTerms() throws Exception {
//封装了获取RestHighLevelClient的方法
RestHighLevelClient client=ElasticSearchClient.getClient();
SearchRequest request = new SearchRequest("test4");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.aggregation(AggregationBuilders.terms("classroom_term").field("classroom")
.subAggregation(AggregationBuilders.terms("gender").field("gender")));
request.source(searchSourceBuilder);
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
//获取数据时首先对classroom分桶,再对gender分桶
Terms classroomTerm = search.getAggregations().get("classroom_term");
for(Terms.Bucket classroomBucket:classroomTerm.getBuckets()){
Terms genderTerm=classroomBucket.getAggregations().get("gender");
for (Terms.Bucket genderBucket:genderTerm.getBuckets()){
System.out.println("classRoom:"+classroomBucket.getKeyAsString()+"gender:"+genderBucket.getKeyAsString()+"count:"+genderBucket.getDocCount());
}
}
}
这里比较难理解对是获取数据时的处理,聚合查询时有个桶的概念,在获取数据时需要遍历获取桶,以上面的代码为例,先获取到classroom的桶,再遍历classroom的桶获取gender的桶,从桶中获取到具体的内容。看下图:

5.2 range
range查询可以统计出每个数据区间内的数量:比如我要统计分数为*~70,70~85,80~*的数据,就可以通过下面的方式:
POST /test4/_search
{
"aggs": {
"grade_range": {
"range": {
"field": "grade",
"ranges": [
{"to":70},
{"from":70,"to":85},
{"from":85}
]
}
}
}
}
JavaAPI如下:
@Test
public void testRange() throws Exception {
//封装了获取RestHighLevelClient的方法
RestHighLevelClient client=ElasticSearchClient.getClient();
SearchRequest request = new SearchRequest("test4");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.aggregation(AggregationBuilders.range("grade_range").field("grade")
.addUnboundedTo(70).addRange(70,85).addUnboundedFrom(85));
request.source(searchSourceBuilder);
SearchResponse search = client.search(request, RequestOptions.DEFAULT);
//获取数据时首先对classroom分桶,再对gender分桶
Range gradeRange = search.getAggregations().get