从分类到检测_从0学习yolov3_万字文章干货满满
Posted scarecrow_sun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从分类到检测_从0学习yolov3_万字文章干货满满相关的知识,希望对你有一定的参考价值。
更新:
data:2021.8.23
note:
🕐之前Yolov3的解释有问题,重新学习更改内容
🕐加入了Yolov3的评价指标——还在写ing
一、机器视觉任务
按照上课老师讲的,目前的机器视觉有以下这四大任务,目前我学到了物体检测这一块,之后的语义分割和实例分割还没学,所以以下的笔记都是从0开始的检测任务相关笔记,干货满满

二、分类任务和检测任务的区别
分类任务:简单的对一个对象进行识别
但是对于有多个物体的图像,分类很明显不能够满足我们所需要的识别
检测任务:可以对多个对象进行识别
三、检测任务
1.目标定位
Bounding box
学习检测任务之前,咱们先学习一个小玩意儿,叫BBOX,也就是Bounding box
首先在检测任务里面有一个非常重要的概念——Bounding box
检测任务之所以叫检测任务,是因为我们要检测出图像中的物体的类别和位置,而为了标出这个位置,我们就需要用上这个Bounding box,其作用是为了能够圈出图像的位置。
一般有三种定义Bounding box
- 左上角和右下角的坐标画出一个Bounding box
- 中心坐标、图像长、宽画出一个Bounding box
- 中心坐标、图像长、宽再加上一个旋转角度alpha画出一个Bounding box

这个概念是不是超级简单,但是这个简单的概念也是检测任务的基础

单个物体进行目标定位
了解了最基础的什么是bounding box之后,我们继续往后走。
按照我们之前分类任务的思维,我们如果要在一张图片里面找到一个物体,识别出这一个物体,并且对他进行定位,我们可以怎么来实现呢?
分类图片很简单,我们只需要将这一个图片经过卷积神经网络,最终让全连接层(或者其他)输出一个类别里面最可能的那一种类别,我们可能用softmax进行判断,亦或者是其他方法进行判断,但无论如何,这个是简单可以能够实现的。
那我们怎么把这一个物体进行定位呢,其实道理也很简单,我们只需要让图片经过网络,让这个网络还能输出我们需要寻找的那一个物体的中心点座标(X,Y),以及图片的长度和高度,那么这样我们就可以实现一张图片中一个物体的检测了。用所学的一张PPT来举例子如下:
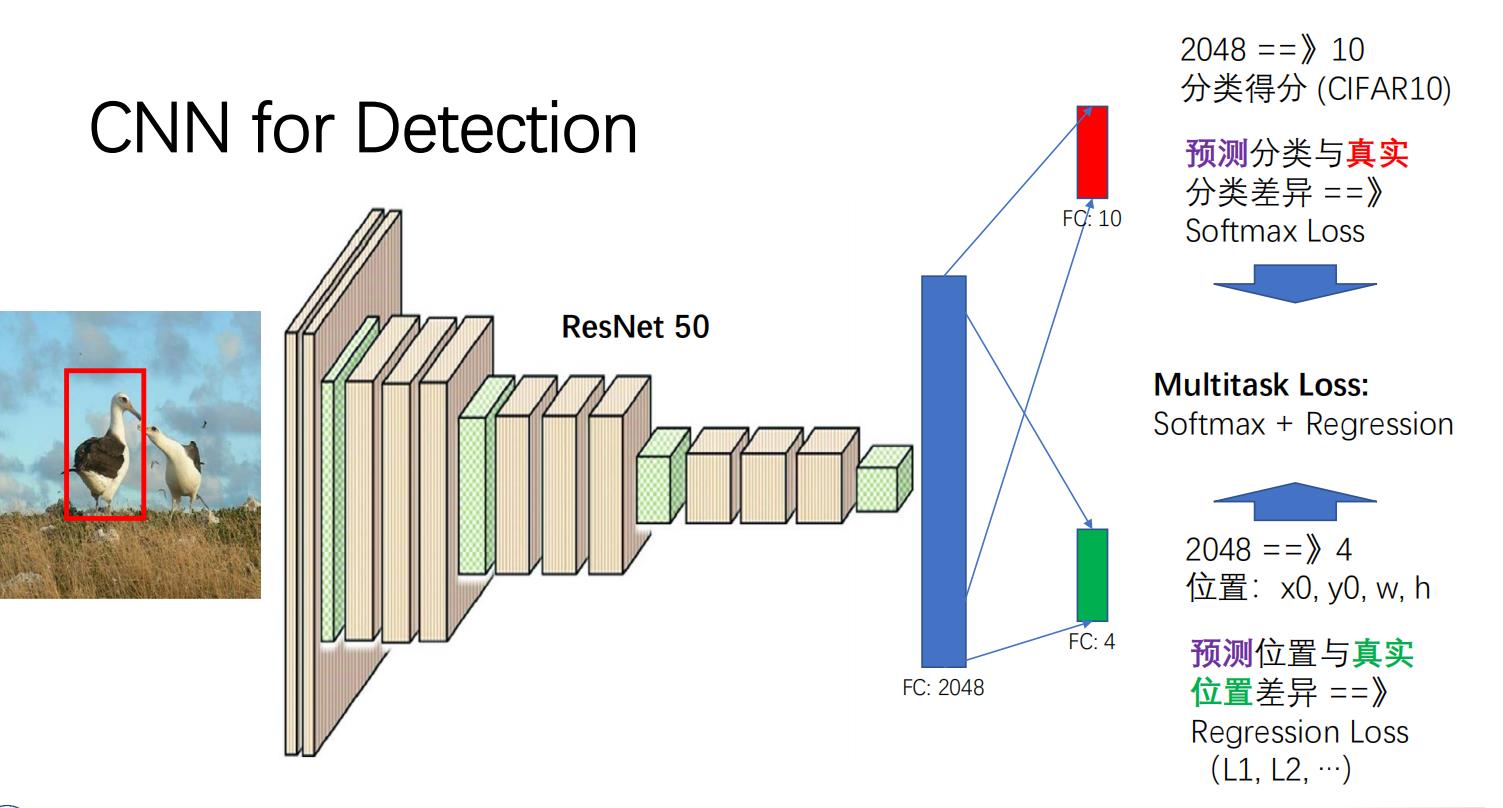
可以看到,最后的神经元节点,也就是我们的分类个数是14个,其中10个是10种物体的类别,剩下的4个就是该物体的座标。我们的卷积神经网络的Loss只需要定义成Multitask Loss即可,至于这个混合损失要怎么具体用数学形式来表达,你可以用图上的单纯相加,也可以使用其他的数学方法来定义。
多个相同种类物体进行目标定位
解决了如何对一个单个物体进行定位,那么如果一张图片上有多个物体,我们需要如何进行定位呢?
方法其实很简单,我们要做的其实就是简单的增加一下最后输出的神经元个数,让其输出的类更多,这样就解决了多个相同种类物体的定位。
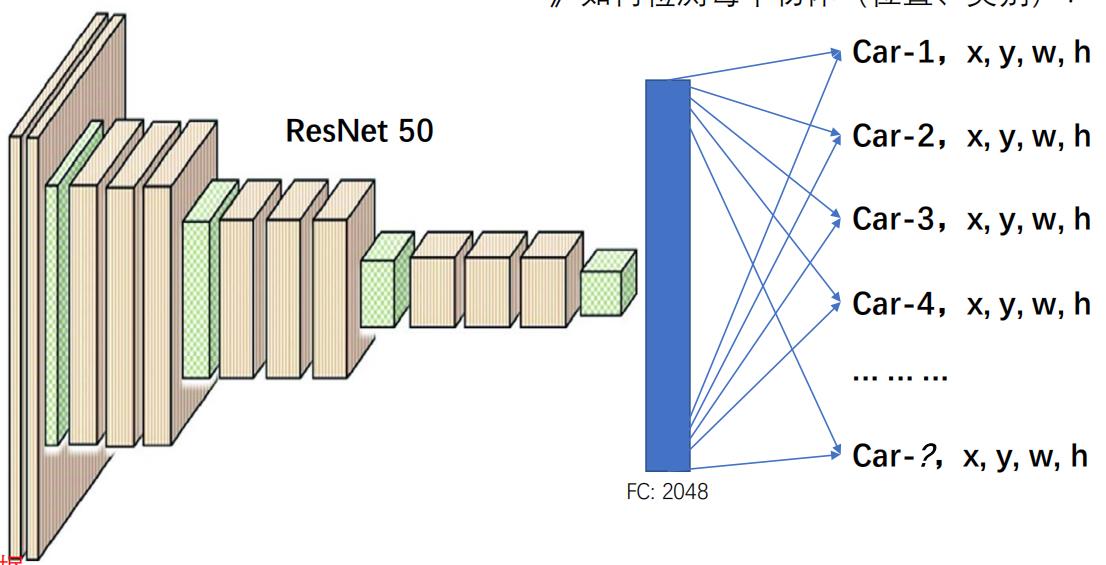
但是,这样的方法有很明显的缺点
- 多个物体的时候,你的多个物体在图片中的长度和宽度是不固定的,这样的训练如何进行呢?
- 多个物体,这个多个两个字要怎么体现在你的输出上面呢?你并不知道你一张图片具体有多少个对象,如何规整化呢?
- 对待多类别物体的时候你就没法了
不太一样的bounding box
为了解决这些问题,我们其实是用这样的输出信息来放在我们圈出一个物体的bounding box里面
[Pc,bx,by,bh,bw,c1,c2,c3…]…
或者能把很多物体放到一起
[Pc,bx,by,bh,bw,c1,c2,c3…,Pc2,bx2,by2,bh2,bw2,c1,c2,c3…,…]
注意:这里需要先行说一个概念,我们后续的识别,就相当于是在整个图片里面取出了一个小图片,然后用这个小图片来进行我们的目标检测和识别,从而组成整张图片,而这一个小图片,我们就可以看成是我们现在进行的这些步骤处理图片。
解释
- Pc代表了你这个图片里面含有你需要检测物体的概率,你可以设置一个阈值,当Pc小于一个值的时候,后面的数据我都不关心了。
- bx,by,bh,bw是你图像里面识别出来的物体的位置信息
- c1,c2,c3…代表了你有多少类物体需要去识别
以上所有的方法就是对物体的一个定位了,当然也包含了一些对最终目标图片的检测
目标检测
因为我们的目的是要实现对一张图片里面的多个物体,多种物体进行识别,并且标注其位置
所以我们如果只把一张图片输出去,就会出现在目录<多个相同种类物体进行目标定位>里面出现的各种缺点。
针对这种情况,我们的目的就是需要尽可能把图片中含有我们物体的那一小块图片给拿出来,放到卷积神经网络里面,输出[Pc,bx,by,bh,bw,c1,c2,c3…],从而实现物体的识别和定位。
先从最开始,也是最简单的方法开始说起。
Sliding window(滑窗法——简单粗暴进行检测任务)
在以前那个分类任务到检测任务的过渡时期,我们使用的是滑动窗口模式进行检测任务
设计一个窗口,从图像的左上角开始,设计步长以及窗口大小,进行滑动,最终滑动到图像的右下角,这样我们只需要将每一个窗口进行分类任务,不识别他的位置信息,因为位置信息已经蕴含在了每一个滑动的窗口中,我们只需要将滑动窗口的位置信息放进去输出的信息即可。
