性能分析之 PHP 应用进程过多导致的 page faults
Posted zuozewei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了性能分析之 PHP 应用进程过多导致的 page faults相关的知识,希望对你有一定的参考价值。
一、前言
前阵子在 7DGroup 群里讨论了一个系统遇到的性能问题。在此记录一下,以备后查。
二、背景信息
这是一个股票相关的系统,具体的业务细节不在我们的技术分析范围内。其技术架构图如下所示:
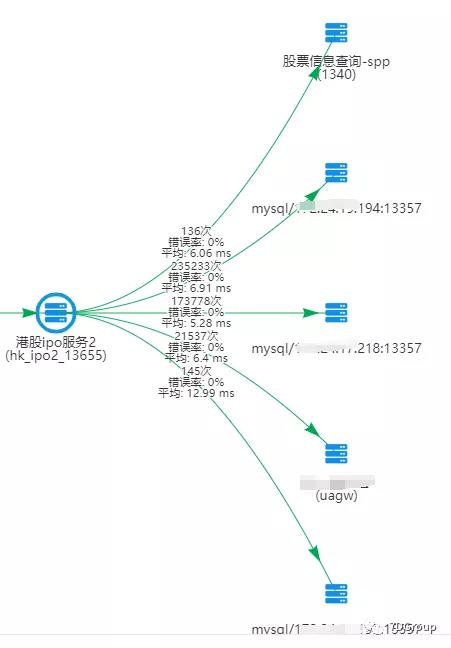
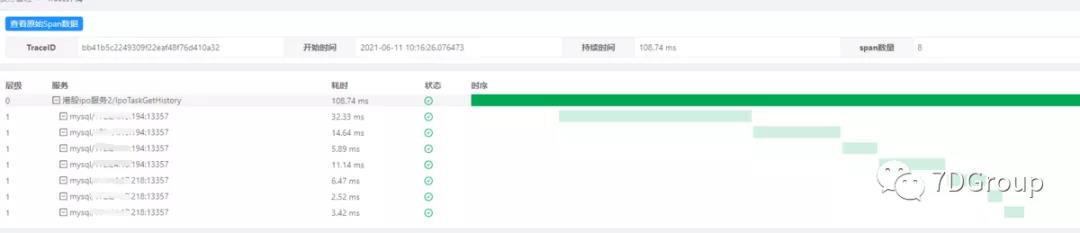
这是一个 php 应用,单个查询接口做基准场景的压力测试,调用链如下:
三、性能问题一
1、问题现象
先看一下压力数据。
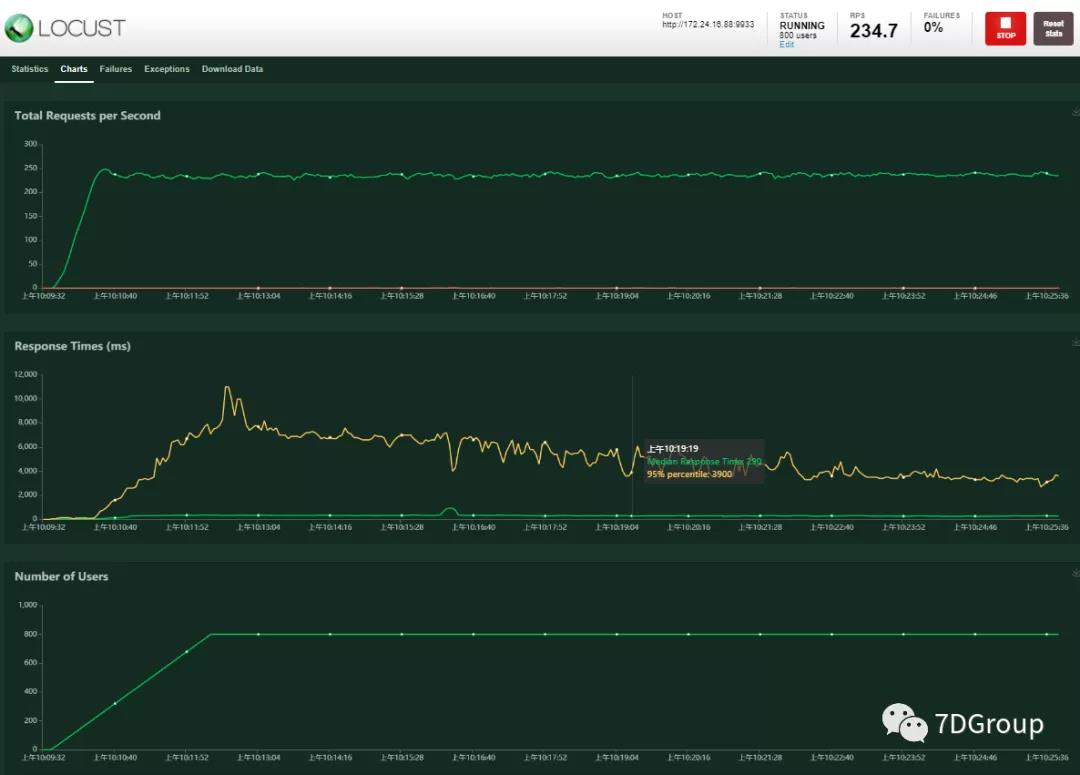
从 TPS 和 R T图上,看到响应时间在不断地下降,TPS 似乎也没有上升。
在这个问题中,我们要解决的是为啥 TPS 上不去、系统资源又用不完的问题。
2、问题分析
因为这个系统架构非常简单,所以这里可以跳过 RESAR性能分析七步法 的拆分响应时间这一步。架构在上面也已经有了。
现在我们直接去到服务器上看系统资源的使用情况。
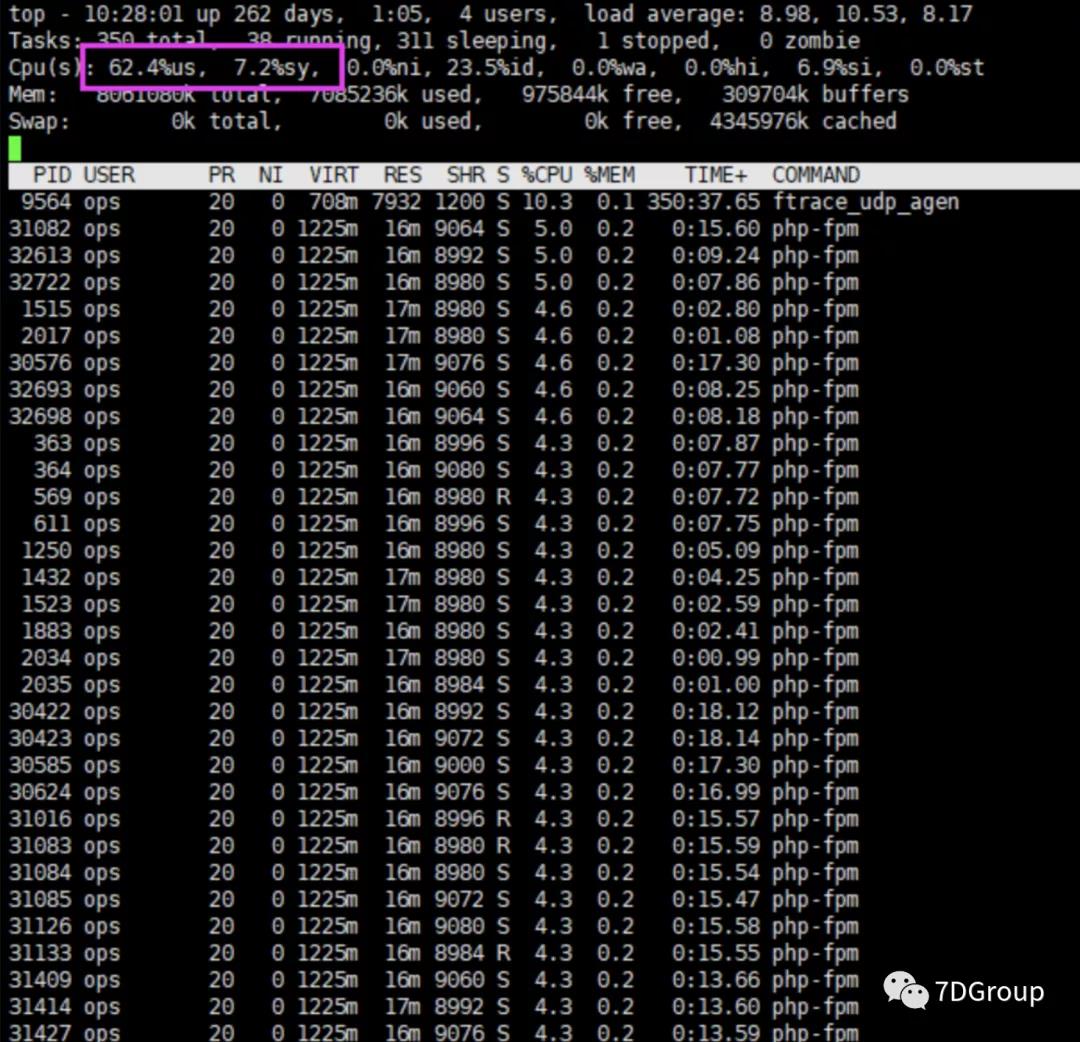
从图上看,CPU 资源还没有完全用完,但 TPS 已经上不去了(即便TPS还能增加,也增加不了多少,毕竟只有 23.5 %的空闲 CPU了)。si cpu 6.9%。
通常这种情况下,我们分析的时候,因为 CPU 的 id 还有 23.5%,所以根据我的优化逻辑,应该是先把 CPU 消耗光,因为 CPU 没有消耗光的时候,通常是已经有了瓶颈,并且这样的瓶颈通常都和这几个词相关:队列、锁、池。
简单来说,就是路不够宽,所以 CPU 才用不上那么多。
这里我们要查各种日志,因为当某个资源达到了上限时,通常都会给出异常日志。
在应用的服务器里,要查的日志通常就会包括两类:
- 应用日志;
- 系统日志。
当用 dmesg 查看系统日志时,看到如下信息:
nf_conntrack: table full, dropping packet.
这个日志非常明显,nf_conntrack 满了,我们把它加大就可以。
nf_conntrack(以前叫 ip_conntrack)是 Linux 中一个跟踪 TCP 连接条目的模块,它会用一个哈希表记录 TCP 的连接信息。当这个哈希表满了之后,就会报nf_conntrack: table full,dropping packet这样的错误。
有个参数来控制这个表的最大值就是net.netfilter.nf_conntrack_max。
这个问题,我在专栏中也有写过,原理也有解释过。
不过!这里是不是只有这个问题呢?还不止,在我们查看系统级的全局监控数据时,还看到如下信息:
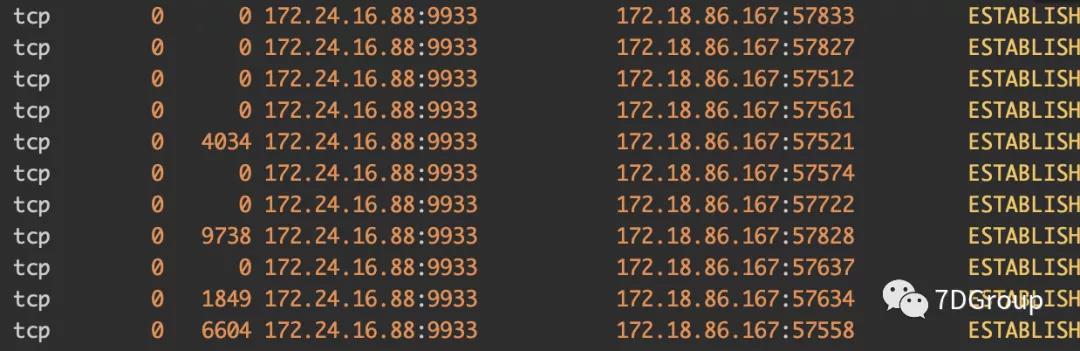
也就是服务器端的 send_Q 有值,提醒一下,这个值并不是只看一次就可以,而是持续观察一段时间,长时间有值才是有问题。
而这时查看应用的进程总共有 64 个。

PHP 是多线程单进程的管理模式。而现在又是发不出去数据,面对的又是压力机,所以,需要关心压力机和应用服务器之间的网络情况,先查一下有多少跳。
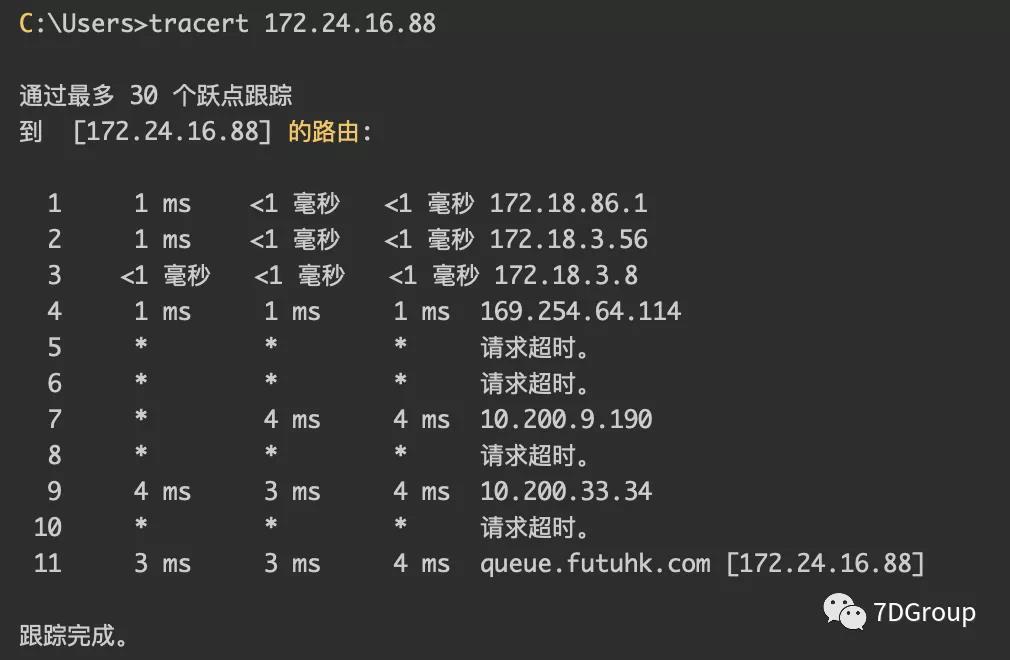
看下来,似乎也不近。通常这种情况下,最快的验证方式就是把压力机放到和应用服务器在同一网段。
在性能分析的过程中,如果你对网络的控制权限和基础知识没有达到去操作被测路径上的每一个网络设备的时候,我劝你尽快绕过中间设备,因为在很多企业中,这个沟通都是非常耗时且经常会沟通不到重点。
3、优化效果
在这里,我们把压力机换到内网服务器上之后,效果如下:
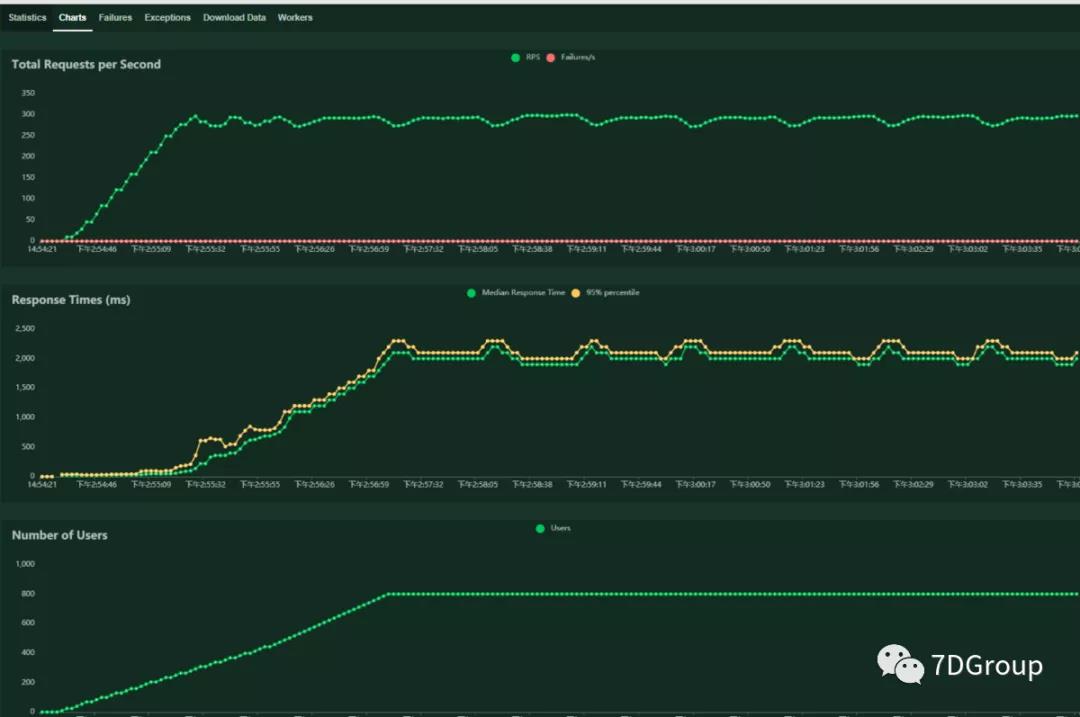
从数据上看,tps 达到 300 左右,比之前高了,响应时间也稳定了(其实这里响应时间还是长,要分析下去,还是有发挥的空间的)。
再来看一下服务器资源使用情况。
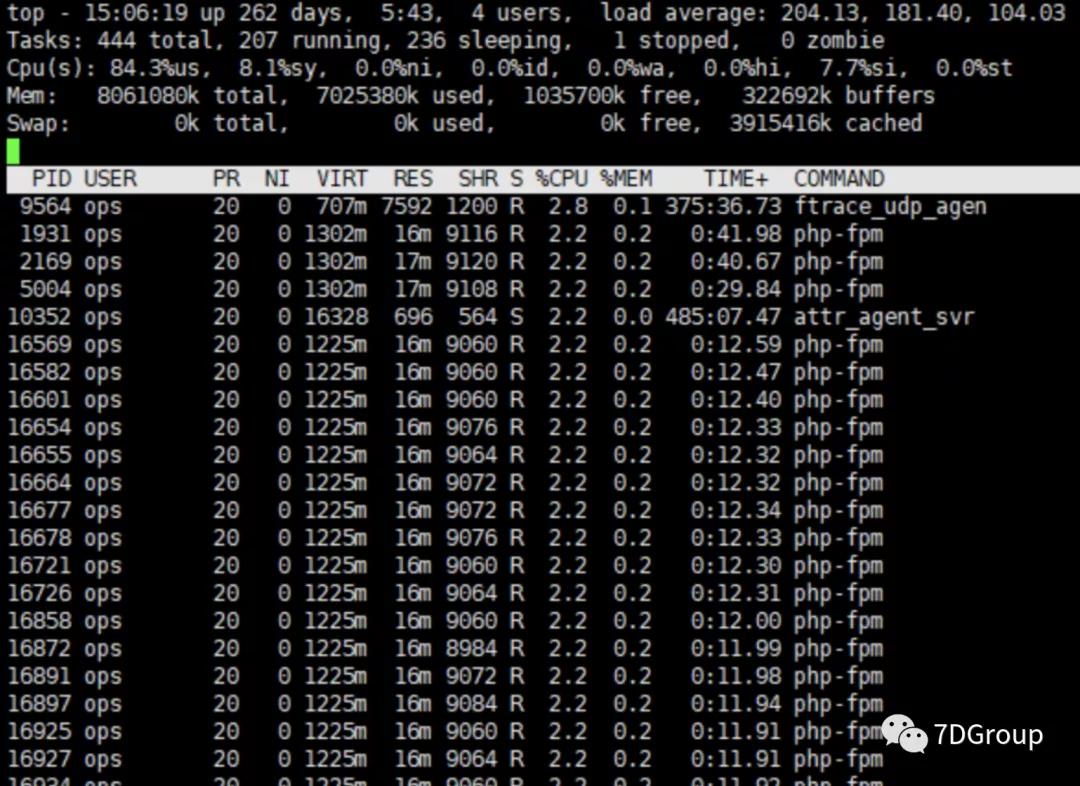
再看下应用进程数。

也就是说把压力机移到内网中,压力就可以立即上来了。这也充分说明了网络对TPS的影响。
四、性能问题二
1、问题现象
这个问题和上一个问题并不是在同一个环境,但应用是同一个版本。
在这个环境中,硬件资源要少一些,应用是 2C4G 的云服务器。
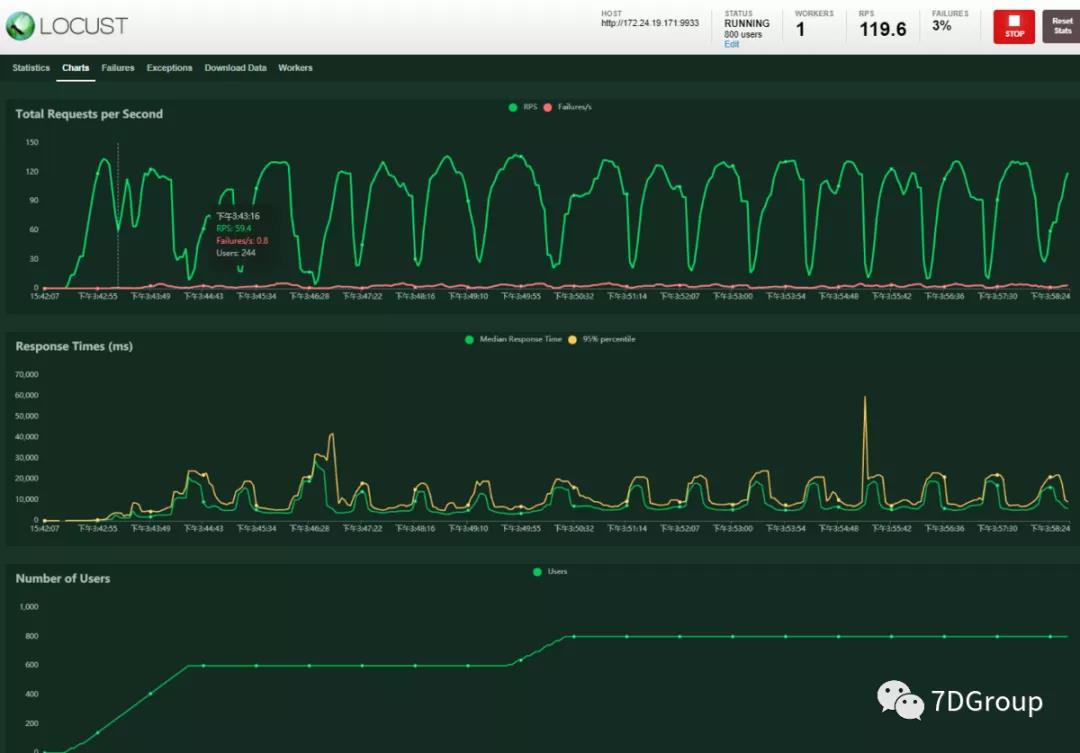
从 TPS 和 RT 曲线上来看,就知道是规律性的抖动。
我们现在要定位的就是为什么这么抖动的问题?
2、问题分析
根据我提出的 RESAR 分析逻辑,先看全局监控,后做定向监控。
来看下有什么信息可以分析的,首先这位同学给出来的是云服务器自带的监控界面。
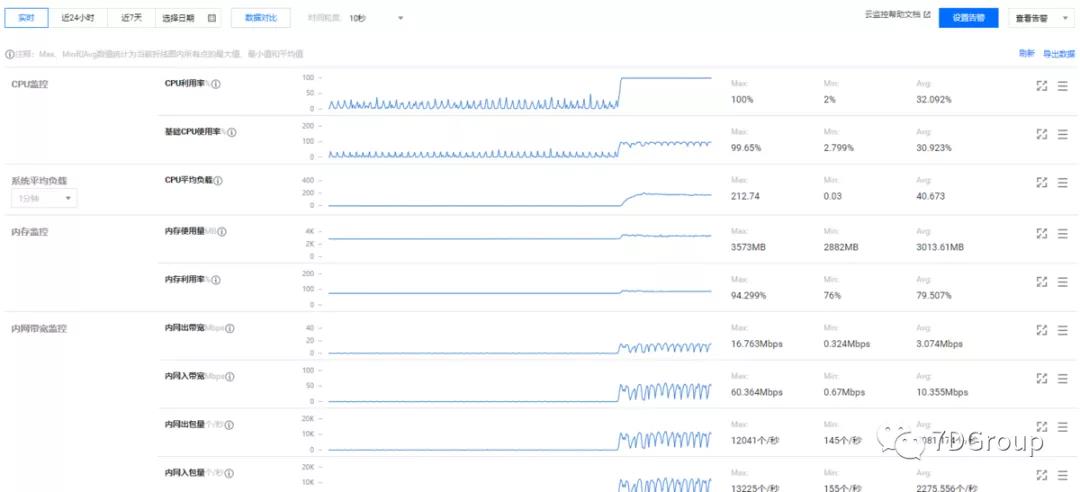
注意:通常情况下,有很多做性能分析的时候,看到这个界面以为就是看到了有效的数据。不止是性能分析人员这样想,做运维的人也认为给了这些数据就够了。但实际上,这些数据远远不够分析。但现在的云平台几乎给的都是这些差不多的数据,所以,在云服务器上做分析,大部分时候都是需要我们执行命令去收集数据的。这也是现在使用云服务器的大弊端之一。
由此可见,云服务器的监控界面,基本上不可做为全局监控数据来使用。
这时候怎么办呢?只有进到服务器里执行全局监控的命令。
先来个 top:
top - 16:00:03 up 105 days, 20:14, 3 users, load average: 178.80, 174.37, 121.59
Tasks: 475 total, 164 running, 232 sleeping, 0 stopped, 9 zombie
%Cpu0 : 71.2 us, 25.2 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 3.6 si, 0.0 st
%Cpu1 : 73.0 us, 23.3 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 3.7 si, 0.0 st
KiB Mem : 3881904 total, 143380 free, 2913448 used, 825076 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 123224 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
30 root 20 0 0 0 0 S 4.6 0.0 387:24.77 kswapd0
607 root 20 0 1201328 16732 1468 S 3.3 0.4 136:27.39 barad_agent
10519 ops 20 0 706456 8760 680 S 3.3 0.2 135:50.02 ftrace_udp_agen
1 root 20 0 190876 2664 1168 S 2.0 0.1 96:52.92 systemd
635 dbus 20 0 28140 2312 344 R 2.0 0.1 129:10.52 dbus-daemon
8544 root 20 0 775288 18612 8932 S 2.0 0.5 4:14.55 YDEdr
349 root 20 0 53604 3684 3304 S 1.7 0.1 58:35.04 systemd-journal
14345 ops 20 0 1278392 17644 9056 R 1.7 0.5 0:07.48 php-fpm
5631 ops 20 0 1278392 17684 9072 R 1.3 0.5 0:09.28 php-fpm
有人要说了,top又多了啥呢?其实你仔细看就知道:
- cpu 计数器是8个,并且每个都能看到值。
- 有 load average。
- 内存有具体的数值。
- 可以看到process table。
这些够不够呢?这就要取决于是什么问题了,当 top 不能让我们进行下一步时,还要执行其他的全局监控命令。
由于在 linux 中并没有一个命令可以看到所有的系统性能计数器,所以只能执行多个命令来覆盖(vmstat/iostat/netstat等)。
先来分析一下,在上面的top数据中,有什么疑点呢:
- cpu已经被消耗光了,id 已经为0了,但us cpu只有70%左右。
- load average也非常高,在2C的服务器上达到了170多的队列长度,真是过分了。
- sy cpu达到了25%左右,这个也过分了。
- 从process table里来看,有一个kswapd0,这是管理页交换的。
而以上的这些有价值的信息,通过云服务器的监控界面是一个也看不到的。
通过以上几点重要的信息,下面我们相应地再查几组数据,然后再进行关联综合分析。
[ops@xxxxxx-null ~]$ sar -B 1
Linux 3.10.0-514.21.1.el7.x86_64 (QC_GZ-172_24_19_171-null) 06/11/2021 _x86_64_ (2 CPU)
05:16:37 PM pgpgin/s pgpgout/s fault/s majflt/s pgfree/s pgscank/s pgscand/s pgsteal/s %vmeff
05:16:38 PM 2428.00 112.00 11481.00 8.00 16976.00 0.00 0.00 0.00 0.00
05:16:39 PM 23691.09 139.60 16352.48 0.99 28139.60 18412.87 0.00 17388.12 94.43
05:16:40 PM 11172.00 0.00 12116.00 5.00 18185.00 0.00 0.00 0.00 0.00
05:16:41 PM 4444.00 0.00 3368.00 3.00 12457.00 0.00 0.00 0.00 0.00
05:16:42 PM 4.00 0.00 5399.00 1.00 13263.00 0.00 0.00 0.00 0.00
05:16:43 PM 4.00 0.00 2674.00 1.00 14081.00 0.00 0.00 0.00 0.00
05:16:44 PM 0.00 31.68 2530.69 0.00 13134.65 0.00 0.00 0.00 0.00
05:16:45 PM 420.00 0.00 4992.00 4.00 14598.00 0.00 0.00 0.00 0.00
05:16:46 PM 8.00 0.00 2582.00 2.00 12660.00 0.00 0.00 0.00 0.00
05:16:47 PM 0.00 0.00 2520.00 0.00 13658.00 0.00 0.00 0.00 0.00
05:16:48 PM 0.00 0.00 2770.30 0.00 13668.32 0.00 0.00 0.00 0.00
05:16:49 PM 2200.00 0.00 2825.00 2.00 11906.00 0.00 0.00 0.00 0.00
05:16:50 PM 8.00 316.00 5241.00 0.00 12759.00 0.00 0.00 0.00 0.00
05:16:51 PM 0.00 0.00 2605.00 0.00 10551.00 0.00 0.00 0.00 0.00
05:16:52 PM 0.00 0.00 5153.00 0.00 13309.00 0.00 0.00 0.00 0.00
05:16:53 PM 0.00 0.00 6580.00 0.00 24864.00 0.00 0.00 0.00 0.00
05:16:54 PM 16.00 12624.00 2838.00 0.00 12658.00 0.00 0.00 0.00 0.00
05:16:55 PM 3.96 75.25 4837.62 0.00 14996.04 0.00 0.00 0.00 0.00
05:16:56 PM 20.00 0.00 2799.00 1.00 12374.00 0.00 0.00 0.00 0.00
05:16:57 PM 2596.00 0.00 5063.00 5.00 15248.00 0.00 0.00 0.00 0.00
05:16:58 PM 7.92 0.00 2525.74 0.00 13568.32 0.00 0.00 0.00 0.00
05:16:59 PM 0.00 0.00 2897.00 0.00 12689.00 0.00 0.00 0.00 0.00
05:17:00 PM 52.00 0.00 5115.00 1.00 14965.00 0.00 0.00 0.00 0.00
05:17:01 PM 3432.00 247.00 4049.00 2.00 13372.00 0.00 0.00 0.00 0.00
05:17:02 PM 13680.00 108.00 24726.00 96.00 14860.00 0.00 0.00 0.00 0.00
05:17:03 PM 38308.00 436.00 74812.00 273.00 59709.00 31661.00 0.00 30270.00 95.61
05:17:04 PM 19668.00 4861.00 50836.00 217.00 50120.00 21439.00 3326.00 23184.00 93.62
05:17:05 PM 29104.95 1172.28 34513.86 181.19 34986.14 21929.70 0.00 20190.10 92.07
05:17:06 PM 56416.83 1906.93 49170.30 201.98 46266.34 22119.80 0.00 21058.42 95.20
05:17:07 PM 132063.73 550.98 26121.57 359.80 54441.18 35367.65 2843.14 36667.65 95.96
05:17:08 PM 140647.22 85.47 6047.46 475.79 53316.95 332737.53 673634.87 31309.44 3.11
05:17:14 PM 147070.19 60.87 8724.22 465.53 71342.86 960378.88 2018672.36 36032.30 1.21
05:17:14 PM 64550.00 0.00 143087.50 862.50 149162.50 0.00 0.00 0.00 0.00
05:17:15 PM 92045.00 52.00 174568.00 690.00 48202.00 0.00 0.00 0.00 0.00
05:17:16 PM 54492.00 108.00 122016.00 436.00 75954.00 0.00 0.00 0.00 0.00
05:17:17 PM 3056.00 0.00 81783.00 49.00 24937.00 0.00 0.00 0.00 0.00
05:17:18 PM 4516.00 4.00 74144.00 73.00 60364.00 0.00 0.00 0.00 0.00
05:17:19 PM 2784.16 27.72 16536.63 1.98 18620.79 0.00 0.00 0.00 0.00
05:17:20 PM 8944.00 0.00 15552.00 2.00 13285.00 0.00 0.00 0.00 0.00
05:17:21 PM 3688.00 552.00 31403.00 11.00 19743.00 0.00 0.00 0.00 0.00
05:17:22 PM 1805.94 0.00 17313.86 0.99 14853.47 0.00 0.00 0.00 0.00
05:17:23 PM 3992.00 0.00 7831.00 0.00 18488.00 0.00 0.00 0.00 0.00
05:17:24 PM 5972.00 0.00 10727.00 3.00 10108.00 0.00 0.00 0.00 0.00
05:17:25 PM 10376.00 0.00 6539.00 19.00 14876.00 0.00 0.00 0.00 0.00
05:17:26 PM 16920.00 144.00 6997.00 4.00 12119.00 0.00 0.00 0.00 0.00
[ops@xxxxxx-null ~]$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
218 10 0 145864 2952 756036 0 0 1323 93 0 1 7 2 89 2 0
231 10 0 124852 2496 748252 0 0 81672 119 7689 6395 69 32 0 0 0
224 12 0 110848 1356 723592 0 0 39582 507 8786 6771 72 28 0 0 0
95 71 0 88360 196 710604 0 0 816904 873 27306 27572 13 78 0 8 0
68 10 0 102900 7016 881700 0 0 88965 8 5425 6100 60 40 0 0 0
68 7 0 244032 8272 859476 0 0 59032 60 6473 6845 65 35 0 0 0
76 5 0 285132 8844 871252 0 0 13104 8 7963 7489 76 24 0 0 0
112 1 0 303520 9200 873980 0 0 2388 4 7567 6675 76 24 0 0 0
129 1 0 230600 9692 883212 0 0 9444 380 8103 6854 69 31 0 0 0
145 0 0 242124 9732 890496 0 0 6204 4 9292 8441 78 22 0 0 0
166 0 0 213028 9752 897756 0 0 6544 0 8881 7795 79 21 0 0 0
162 1 0 197468 10044 900888 0 0 2516 0 9290 8153 80 21 0 0 0
191 1 0 206824 11168 911960 0 0 13180 0 10097 9118 78 22 0 0 0
126 1 0 203336 11180 913396 0 0 1440 280 10015 8836 82 18 0 0 0
176 0 0 188376 11180 917688 0 0 4092 0 10803 9574 82 18 0 0 0
191 1 0 174668 11596 923228 0 0 5812 0 9830 9114 84 17 0 0 0
203 2 0 155228 11636 931476 0 0 8832 0 10648 9316 81 19 0 0 0
127 3 0 143336 11636 940520 0 0 9089 0 11578 9979 79 21 0 0 0
146 1 0 112528 11776 959636 0 0 19300 0 9510 8703 83 17 0 0 0
170 1 0 120620 10740 952520 0 0 15532 96 9831 8649 82 18 0 0 0
183 2 0 120652 10276 944988 0 0 15644 157 10171 9378 80 20 0 0 0
194 2 0 146280 8820 918372 0 0 17388 457 9458 8180 83 17 0 0 0
200 3 0 91428 7600 931980 0 0 29656 178 9205 8073 82 18 0 0 0
109 2 0 167932 5804 866800 0 0 8658 19728 10093 8987 77 23 0 0 0
[ops@xxxxxx-null ~]$ iostat -x -d 1
Linux 3.10.0-514.21.1.el7.x86_64 (QC_GZ-172_24_19_171-null) 06/11/2021 _x86_64_ (2 CPU)
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.32 6.71 52.50 9.48 2018.28 98.98 68.32 0.07 1.18 0.31 6.00 0.41 2.51
vdb 0.01 0.42 31.45 2.77 618.48 85.87 41.16 0.08 2.22 1.56 9.69 0.69 2.37
scd0 0.00 0.00 0.00 0.00 0.00 0.00 10.18 0.00 0.79 0.79 0.00 0.79 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 18.81 0.00 2047.52 409.90 122364.36 4071.29 102.90 11.08 4.61 3.78 8.76 0.32 77.82
vdb 0.00 0.00 256.44 6.93 4556.93 27.72 34.82 0.29 1.10 1.11 0.86 0.58 15.35
scd0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 7.00 0.00 917.00 0.00 51412.00 0.00 112.13 2.67 2.91 2.91 0.00 0.38 35.10
vdb 0.00 0.00 288.00 3.00 6588.00 35.50 45.52 0.26 0.90 0.90 1.00 0.59 17.30
scd0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 3.00 0.00 169.00 0.00 5724.00 0.00 67.74 0.33 1.96 1.96 0.00 0.37 6.30
vdb 0.00 0.00 127.00 1.00 3120.00 4.00 48.81 0.15 1.20 1.20 1.00 0.98 12.60
scd0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.00 242.00 0.00 1920.00 0.00 15.87 0.45 1.84 1.84 0.00 0.21 5.20
vdb 0.00 0.00 14.00 1.00 376.50 4.00 50.73 0.01 0.53 0.50 1.00 0.53 0.80
scd0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 2.00 67.00 547.00 8.00 11348.00 300.00 41.97 1.01 1.81 1.78 4.25 0.33 18.10
vdb 0.00 0.00 12.00 1.00 3980.00 4.00 612.92 0.08 6.31 6.33 6.00 1.38 1.80
scd0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.00 19.80 129.70 831.68 772.28 21.46 0.32 2.15 2.15 2.15 0.14 2.08
vdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
scd0 0.00 0.00 0.00 0.00 0.00 以上是关于性能分析之 PHP 应用进程过多导致的 page faults的主要内容,如果未能解决你的问题,请参考以下文章