文件系统与linux相关知识点
Posted 一生不过烟花
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文件系统与linux相关知识点相关的知识,希望对你有一定的参考价值。
文件系统是操作系统中管理持久性数据的子系统,提供数据存储和访问功能。对于服务器开发人员,比较关注的是unix(linux)环境下的文件系统,比如分区与磁盘关系,磁盘的剩余空间,文件的类型与权限控制,文件链接等相关知识。
磁盘结构简介:
文件系统是建立在物理磁盘之上的,因此在介绍文件系统之前先简单介绍磁盘的结构,这样便于理解后面的相关概念。本文对磁盘的介绍可能比较粗略,感兴趣的读者可以参考《硬盘的读写原理》这一篇文章,写的非常详尽。先来一张结构示意图:
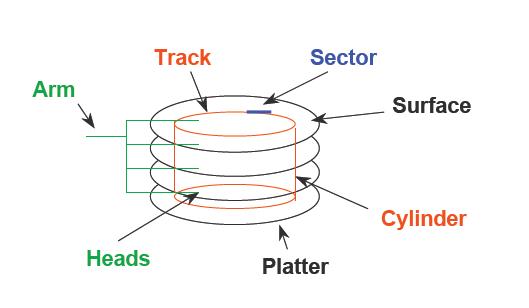
相关术语解释如下:
- 磁盘面(platter):相互平行的存储介质
- 磁头(Heads):每个磁头对应一个磁盘面,负责该磁盘面上的数据的读写。
- 磁道(Track):每个盘面会围绕圆心划分出多个同心圆圈,每个圆圈叫做一个磁道。
- 柱面(Cylinders):所有盘片上的同一位置的磁道组成的立体叫做一个柱面。
- 扇区(Sector):以磁道为单位管理磁盘仍然太大,所以计算机前辈们又把每个磁道划分出了多个扇区
- 磁头臂(arm):驱动磁头的移动
逻辑上,磁盘被分成一个个扇区,扇区是磁盘访问的最基本单位,如果所示,一块区域由cylinder, head,sector三块区域组成(CHS)。早期的操作系统需要知道磁盘的所有参数才能读写数据,而现在的磁盘越来越复杂,扇区可能还有不同的大小。因此,现在的磁盘需要提供更高阶的接口,将磁盘的容量宦维城一组逻辑的块(blocks),操作系统直接对这些逻辑块进行操作。
一次磁盘的读写可能需要经历以下三个步骤,因此读写性能也取决于这三部分的速度:
- 寻道(seek):磁头移动定位到指定磁道,速度非常慢
- 旋转延迟(rotation):等待指定扇区从磁头下旋转经过,速度比较慢
- 数据传输(transfer):数据在磁盘与内存之间的实际传输,速度比较快
什么是文件系统:
首先得知道什么文件,文件是具有符号名,由字节序列组成的数据项集合,是文件系统的基本数据单位。平常提到文件的时候,基本上只关注文件的内容,但是文件本身也有很多信息,比如文件名、类型、位置、大小、权限控制、创建时间、修改时间等,这些信息成为文件的元数据(meta data),在unix系统中个,元数据记录在inode中。
文件系统是操作系统中管理文件的子系统,提供文件数据存储和访问功能,具体来说,文件系统应具备以下功能:
- 分配文件磁盘空间:需要管理已经分配的文件块,包括位置与顺序;管理所有的空闲空间;用一定的分配算法为新的文件分配空间
- 管理文件集合:以某种组织方式结构化文件的信息,以便能够通过名字找到文件,并读取文件的内容
- 数据可靠与安全:首先是提供不同的手段,多层次保护数据安全,比如访问权限控制。通过持久保存文件,避免系统崩溃错误、冗余来保证文件的可靠。
操作系统中一般都是用分层的文件系统,即文件以目录的形式组织,目录里面也可以包含子目录,这样,整个文件系统就形成了一棵树形结构。基于这种分层结构,文件的名字解析(用逻辑名字到物理资源)就比较简单了,根据文件的完整路径,遍历文件目录直到找到目标文件。
由于历史和使用环境的差异,存在着各种不同的磁盘文件系统,比如FAT、NTFS、EXT2、EXT3;还有网络分布式文件系统,比如NFS、SMB,不同的文件系统,作用不同,安全要求不同,优化的目标也不同。面对有多种不同的文件系统,又需要向上层提供一致的接口,因此引入了虚拟文件系统(virtual file system)。分区(即一个虚拟文件系统)与磁盘并不是一一对应的关系,一个磁盘可以对应多个分区,如LVM;多个磁盘也可以对应一个分区,如RAID
操作系统会为每个进程维护一个打开的文件表,为每一个打开的文件分配套一个唯一的标志,即文件描述符(file descriptor)。打开文件表用文件描述符做索引,对应的项维护打开文件的状态和相关信息,比如:
- 文件指针:最近一次读写位置,写过C语言的同学应该不陌生。虽然一个文件可以被多个进程同事打开,但每个进程分别维护自己的文件指针
- 文件打开计数:当前打开文件的次数,当最后一个进程关闭文件时,将其从打开文件表中移除??
- 文件的磁盘信息:操作系统会把一部分访问的文件内容缓存在内存当中,以便加速访问。缓存的数据信息也会记录
- 访问权限:每个进程的文件访问模式信息,打开文件时的选项,只读、只写、还是可读可写
在用户的角度,文件是持久化的数据结构。而在操作系统的角度,文件是数据块(block)的集合,操作系统以快为单位对文件数据进行读写,即使只需读写一个字段,也需要读取一个块(大小为1k、2k或者4k),这里的块是逻辑存储单元,而扇区是物理存储单元,块大小不等同于扇区大小,一般来说,若干个扇区构成一个数据块。
文件分配:
文件分配是指将哪些块分配给文件来存储数据,包括数据库的位置与顺序。在这里,块的大小非常重要,第一:大多数文件都比较小,因此块空间不能太大,需要对小文件提供很好的支持;第二,一些文件非常大,必须支持大文件,访问需要高效(如果块太小,那么大文件需要很多的块)。衡量分配策略的指标主要有两个:存储效率,即外部碎片;读写性能,即访问速度。分配方式有以下三种:
- 连续分配:优点在于访问效率高,支持高效的顺序和随机访问。但缺点在于会引入外部碎片,而且对于文件增长问题不是很好处理。
- 链式分配:优点在于创建、增大、缩小都容易,而且没有外部碎片。缺点在于访问效率低,无法实现真正的随机访问。
- 索引分配:优点在于创建、增大、缩小都容易,没有外部碎片,而且支持直接访问。缺点在于当文件很小时,存储索引的开销,对大文件的处理也是需要考虑的问题
在unix中,使用多级索引分配。
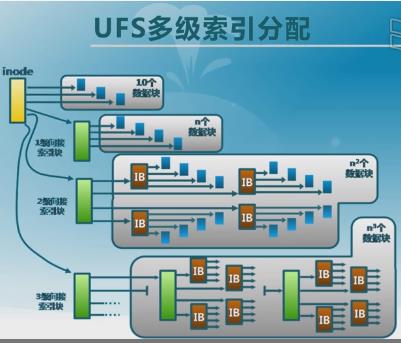
从上图可以看到:文件头总共包含13个指针(PS: 上面来自清华大学的课程,按照Inode_pointer_structure,现在的操作系统有15个block pointer),其中
- 前10个指针直接指向数据库
- 第11个指针指向索引块i
- 第12个指针指向二级索引快
- 第13个指针指向三级索引快
多级索引分配提高了文件大小限制阈值,而且可以动态分配数据块,文件的扩展很容易。文件比较小的时候,直接索引;文件比较大的时候,也能处理,只是效率会差一点。
文件共享和访问控制
在多用户操作系统中(比如unix),文件的共享是分成有必要的,首先一部分文件对于每个用户都是相同的(或者默认是情况下是相同的),没有必要每个用户都保存一份;其次,用户之间可能需要协同处理同一份文件。有共享就需要互斥,这个跟进程线程间的同步互斥是一样的道理,比如对于同一个文件,一个进程在读,另一个进程在写,怎么协调,操作系统并不解决多个进程共享文件时候的一致性问题,需要英语程序来规范解决。
访问控制分为两个层面,第一个是哪些用户可以访问(广义的访问,不限于读写执行)到文件,第二是怎么访问这个文件。更一般的抽象的就是某个用户用什么样的权限来访问某个文件,文件(objects)是what,用户(subjects)是who,方式(actions)是how。从用户的角度来看,需要维护文件与权限的列表,即Access Control list(ACL);从文件的角度看,需要维护用户与用户对该文件的权限的列表,即Capabilities:
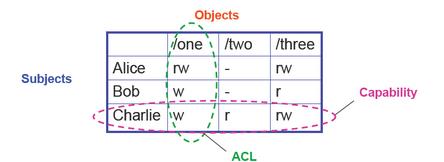
对于每一个用户(subject),都有一个ACL,那么当用户用来越时且一个文件在很多个用户之间共享的时候,ACL列表就会变得非常庞大,因此在unix中,提出了group的概念,同一个group里面的用户对同一个文件共享相同的权限。
文件系统性能:
由于物理设备的制约,磁盘文件的读写与内存比起来相差十万八千里。为了提升文件的读写效率,磁盘会根据自身的参数做优化,比如尽量把一个文件(包括元数据信息)放在临界的扇区。同时,文件系统也会做一些优化,比如:
文件缓存,File buffer cache,将部分文件内容缓存在内存中,由于内存的读写比较快,这样就能极大提高性能。操作系统统一管理缓存,所有进程共享缓存信息,在需要置换的时候也是使用LRU之类的算法。
滞后写,wtire behind,需要写操作的时候,并不立即刷到磁盘,而是维护未提交块的队列,周期性把队列内容刷到磁盘上。但问题是不可靠,可能造成数据不一致。
预先读,read ahead,如果文件系统预测进程会读取下一个块,就预先将下一个块读到cache中来,这个在连续的文件读取环境下,十分有效。
RAID:数据可靠性
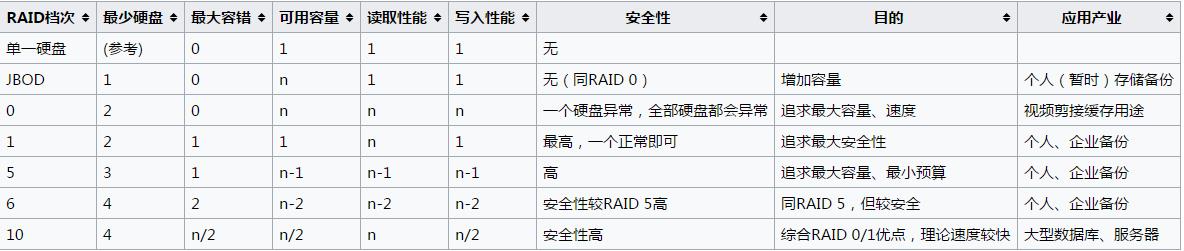
RAID是Redundant Array of Independent Disks,即独立磁盘冗余序列。其基本思想就是把多个相对便宜的硬盘组合起来,成为一个硬盘阵列组,使性能达到甚至超过一个价格昂贵、容量巨大的硬盘。根据选择的版本不同,RAID比单颗硬盘有以下一个或多个方面的好处:增强数据集成度,增强容错功能,增加处理量或容量。另外,磁盘阵列对于电脑来说,看起来就像一个单独的硬盘或逻辑存储单元。下图是wiki上各种磁盘阵列的比较表:
linux下的文件
linux环境下的文件系统分为三个层级,其基本数据结构如下:
(1)文件卷控制块:superblock
每一个文件系统一个,在文件系统挂接的时候加载,记录文件系统的详细信息,比如块、块大小、空闲块、各种计数和指针。
(2)目录项:dentry(dictionary entry)
每一个目录项一个,在遍历文件的时候加载到内存,包含指向文件控制块,父目录、子目录等信息
(3)文件控制块:inode
每个文件一个,在文件访问的时候加载到内存,记录的就是文件的元数据(meta data)。
在linux环境下,可以使用df(disk free)查看本系统上的文件系统的剩余空间与相应的挂载情况,然后使用dumpe2fs xxx(文件系统名)即查看文件系统信息,包括superblock信息,总共/可用的block inode信息,每个block inode的大小等。
文件的meta data
使用list -l可以查看一部分文件的元数据,不过使用stat命令会更加详细一些, for example:
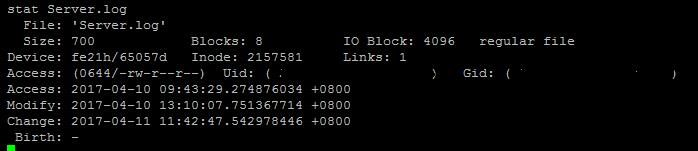
比较重要的信息包括:
File type: 文件类型,上图已经指出为“regular file”, Access的第一位也是用来表明文件类型。
Inode:元数据位置索引,每个文件唯一
Links:有多少个文件名指向这个文件,后面介绍文件链接的时候还会提到
Access:访问权限
atime:access time, 文件的最后访问时间
mtime: modification time, 文件内容修改时间
ctime: change time, 文件属性(meta data)修改时间
从上面的截图可以看到,文件的三个时间属性可能是不同的值,三者之间可能相互影响,关系如下:
- atime的变化不会影响mtime和ctime
- ctime的变化也不会影响mtime 和atime
- mtime的变化会同时影响到atime和mtime,因为修改文件必定会访问文件,另外文件内容的大小是文件的元数据
对于文件系统来说,文件的类型也是非常重要的信息,而且操作系统的其他部分也需要知道文件的类型信息。在windows下,通过后缀名来区分文件类型,在unix下,会将文件的类型通过magic number记录。linux下文件类型通过ls -l 命令第一行即可看到,可能得类型如下:
- 普通文件,第一个字段为-
- 目录,第一个字段为d
- 管道(PIPE), 第一个字段为p, 用来做进程间通信(IPC)
- 套接字(socket),第一个字段是s,之前已经介绍过,unix domain socket,也是用作进程间通信
- 符号链接文件(symbol link), 第一个字段是l,后面会详细介绍
- 块设备(block), 第一个字段是b,即磁盘设备
- 字符设备(character), 第一个字段是c,指的是鼠标、键盘灯串行设备
其中。普通文件又分为纯文本文件、二进制文件等,可通过file命令查看
访问权限控制
我们都知道对于一个文件,用户有三种权限:r(可读)、w(可写)、x(可执行),对于普通文件来说很好理解,但是对于目录来说是是你们意思呢,特别是目录的写操作和执行?
r: 具有读取目录结构列表的权限,比如使用ls(list)
w:具有更改目录结构列表的权限,不如新建文件、目录;删除文件、目录;重命名等
x:用户能否进入该目录成为工作目录, 比如使用cd
以前就出现过cd失败的原因,原来是因此这个权限问题。
另外也能在用户权限位看到s、t等情况,这个具体意义可以参考《Linux特殊权限:SUID、SGID、SBIT》。下面制作简单总结
- 文件具有SUID的权限时,代表用户执行此二进制程序的时候,执行过程中用户文件所有者的权限
- 目录具有SGID的权限时,代表用户在这个目录下新建的文件用户组都会与该目录的用户组相同
- 目录具有SBIT的权限时,代表用户在这个目录下新建的文件只有自己和root能够删除
atime & noatime
上面提到 atime是文件的最后访问时间,我自己测试了一下,用cat访问文件,但是访问前后的时间戳并没有发生变化,就是说,访问文件并没有改变atime。于是网上查了一下,原因如下:
相信对性能、优化这些关键字有兴趣的朋友都知道在 Linux 下面挂载文件系统的时候设置 noatime 可以显著提高文件系统的性能。默认情况下,Linux ext2/ext3 文件系统在文件被访问、创建、修改等的时候记录下了文件的一些时间戳,比如:文件创建时间、最近一次修改时间和最近一次访问时间。因为系统运行的时候要访 问大量文件,如果能减少一些动作(比如减少时间戳的记录次数等)将会显著提高磁盘 IO 的效率、提升文件系统的性能。Linux 提供了 noatime 这个参数来禁止记录最近一次访问时间戳。
在wiki stat上面也有对着问题的描述,称之为“Criticism_of_atime”,提到关于atime的更新有以下几种选项:
- strictatime (formerly atime, and formerly the default; strictatime as of 2.6.30) – always update atime, which conforms to the behavior defined by POSIX
- relatime ("relative atime", introduced in 2.6.20 and the default as of 2.6.30) – only update atime under certain circumstances: if the previous atime is older than the mtime or ctime, or the previous atime is over 24 hours in the past
- nodiratime – never update atime of directories, but do update atime of other files
- noatime – never update atime of any file or directory; implies nodiratime; highest performance, but least compatible
- lazytime – update atime according to specific circumstances laid out below
其中noatime表示永远不更新任何文件和目录的atime属性。配置在/etc/fstab。for example:

硬链接与符号链接:
硬链接:多个文件项指同一个文件(同一个inode)
符号链接:链接文件与被链接文件的描述信息(元数据,meta data)各自独立,只是说链接文件里面存储另一个文件的完整路径,以此实现文件别名,类似windows中的“快捷方式”。
linux下面使用指令ln src target 即可创建硬链接,target指向的是和src同样的文件,拥有同样的inode(即meta data)信息。也可以理解为,只是多了一个逻辑名指向某个文件。执行指令:ln Server.log Server_hardlink.log
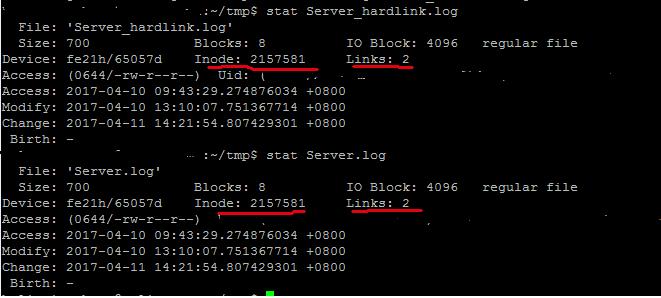
结合上面介绍meta data时候的截图,可以看到,创建硬链接之后唯一变化的就是Links的数值变成了2,因为现在Server_hardlink.log也指向了这个文件。硬链接的好处在于更改的安全性,当我们用rm删除一个文件的时候,其实只是将文件的links数目减少1,只有当links数目减少到0之后才会真正的删除文件。
linux下面使用指令ln -s src target 即可创建符号链接,如下图所示,src和target指向的是不同的inode
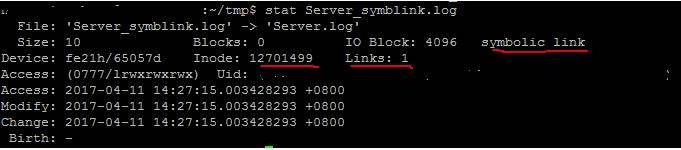
关于硬链接和符号链接,《Linux软链接和硬链接》这篇文章比较详尽清楚。
总结:
本文记录了关于文件系统的一些基础知识,以及linux中文件系统相关的命令,文章中主要是笔者之前不太清晰的一些知识点,并不全面,感兴趣的读者可以看看《鸟哥私房菜》。
以上是关于文件系统与linux相关知识点的主要内容,如果未能解决你的问题,请参考以下文章
Linux系统的相关知识常用命令及拓展centos 7网卡配置