Fate实战——实现集群横向逻辑回归
Posted AI浩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Fate实战——实现集群横向逻辑回归相关的知识,希望对你有一定的参考价值。
摘要
我在做集群的联邦学习之前,用主机部署的方式,实现了单机版的横向联邦学习。参考了下面的两篇文章:
联邦学习实战-2-用FATE从零实现横向逻辑回归_文杰的博客-CSDN博客
Ubuntu18.04上部署单机 Fate1.6.0, 并使用PyCharm进行开发和调试。 - 老妹儿的 - 博客园 (cnblogs.com)
参考这两篇就可以实现单机版的部署和横向联邦学习,建议大家在做集群横向联邦学习之前,先把单机版的搞明白。搞明白单机版后,实现集群的横向联邦。我的集群是个星型的集群,三个节点通过exchange相链接,三个节点的patryid分别是9999,10000,8888。文章对实现过程做个记录。
1 切分数据集
数据集和单机版的一样也是采用威斯康星州临床科学中心开源的乳腺癌肿瘤数据集
from sklearn.datasets import load_breast_cancer
为了模拟横向联邦建模的场景,我们首先在本地将乳腺癌数据集切分为特征相同的横向联邦形式,当前的breast数据集有569条样本,我们将前面的469条作为训练样本,后面的100条作为评估测试样本。
从469条训练样本中,选取前200条作为公司A的本地数据,保存为breast_1_train.csv,将剩余的269条数据作为公司B的本地数据,保存为breast_2_train.csv。
测试数据集可以不需要切分,两个参与方使用相同的一份测试数据即可,文件命名为breast_eval.csv。
splitDataset.py
from sklearn.datasets import load_breast_cancer
import pandas as pd
breast_dataset = load_breast_cancer()
breast = pd.DataFrame(breast_dataset.data, columns=breast_dataset.feature_names)
breast = (breast-breast.mean())/(breast.std())
col_names = breast.columns.values.tolist()
columns = {}
for idx, n in enumerate(col_names):
columns[n] = "x%d"%idx
breast = breast.rename(columns=columns)
breast['y'] = breast_dataset.target
breast['idx'] = range(breast.shape[0])
idx = breast['idx']
breast.drop(labels=['idx'], axis=1, inplace = True)
breast.insert(0, 'idx', idx)
breast = breast.sample(frac=1)
train = breast.iloc[:469]
eval = breast.iloc[469:]
breast_1_train = train.iloc[:200]
breast_1_train.to_csv('breast_1_train.csv', index=False, header=True)
breast_2_train = train.iloc[200:]
breast_2_train.to_csv('breast_2_train.csv', index=False, header=True)
eval.to_csv('breast_eval.csv', index=False, header=True)
注:这一部分的逻辑和单机版的保持一致,我没有做更改。
2 数据转换输入
在集群的fate01上的/data/projects/fate目录下新建chapter05文件夹(单机版叫这个名字,我也懒得换了),进入chapter05文件夹然后新建data文件夹,然后将数据集放到该目录下的data目录中。
参与的节点重复上面的操作,每个节点放置一份数据。
完成数据转换,需要一个配置文件和一个启动程序,我演示第一个节点的操作。
编写训练集的配置文件
upload_train.json
{
"file": "chapter05/data/breast_1_train.csv", //训练集的路径,我们这次试用fate_flow_client.py上传数据,默认的home路径是/data/projects/fate,所以我们需要把剩下的路径补充完整
"head": 1,
"partition": 1,//是否要分区,小数据不用分区
"work_mode": 1,//0是单机,1是集群,我们要注意
"table_name": "homo_breast_1_train",
"namespace": "homo_host_breast_train"//后面这两个字段一个是数据集的名字和命名空间,这个在后面的配置中要用到。
}
编写验证集的配置文件
upload_eval.json
{
"file": "chapter05/data/breast_eval.csv", //训练集的路径,我们这次试用fate_flow_client.py上传数据,默认的home路径是/data/projects/fate,所以我们需要把剩下的路径补充完整
"head": 1,
"partition": 1,//是否要分区,小数据不用分区
"work_mode": 1,//0是单机,1是集群,我们要注意
"table_name": "homo_breast_eval",
"namespace": "homo_host_breast_eval"//后面这两个字段一个是数据集的名字和命名空间,这个在后面的配置中要用到。
}
上面的配置每个节点都配置一份,切分数据集时,训练集切了两份,验证集只有一份,所以验证集配置成一样的,训练我在fate01和fate03上使用的breast_1_train.csv,在fate02上用breast_2_train.csv,大家根据自己的情况修改配置文件即可。
下面执行上传数据的操作,有两种方式上传数据,一种是用fate_flow_client.py上传数据,一种使用flow命令上传数据,我在使用flow上传数据时遇到一些问题,所以先演示如何使用fate_flow_client.py上传数据。具体的详细使用可以查阅官方的文档。
官方文档:上传数据指南 — FATE documentation
启动虚拟环境,并进入chapter05下面,如图:
然后执行:
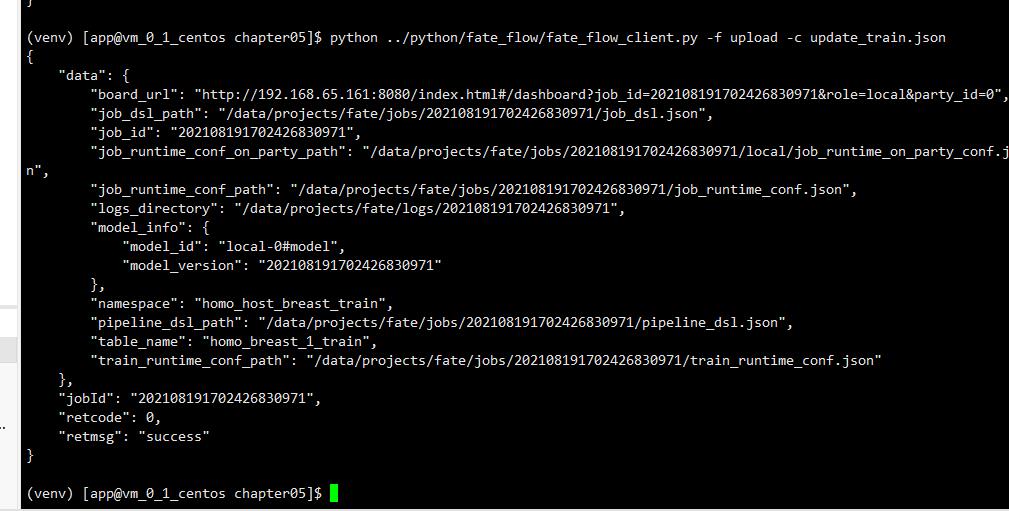
python ../fate_flow/python/fate_flow_client.py -f upload -c upload_train.json
-f :函数名称
-c :配置文件
将验证集也上传上去:
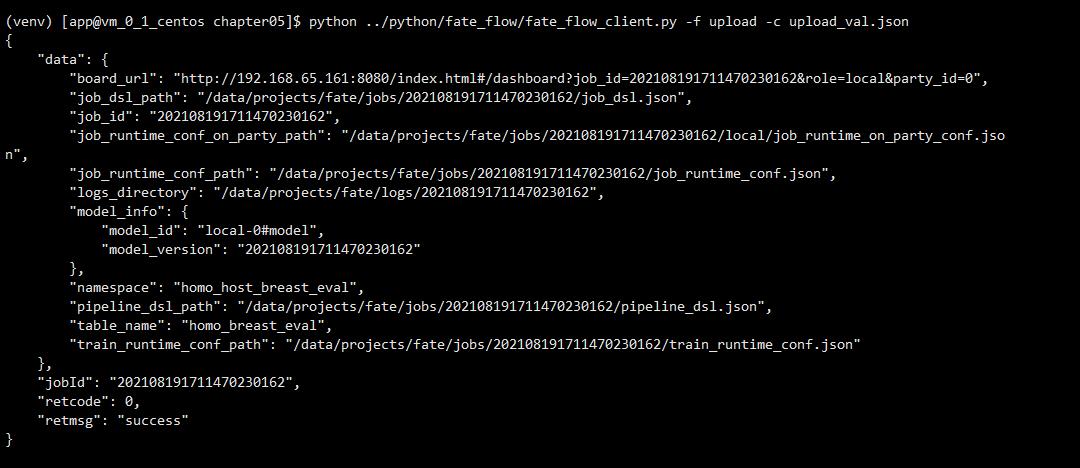
fate02和fate03重复上面的步骤,把训练集和测试传上去。
到这里数据集已经上传,接着就可以开始做训练了。
3 模型训练
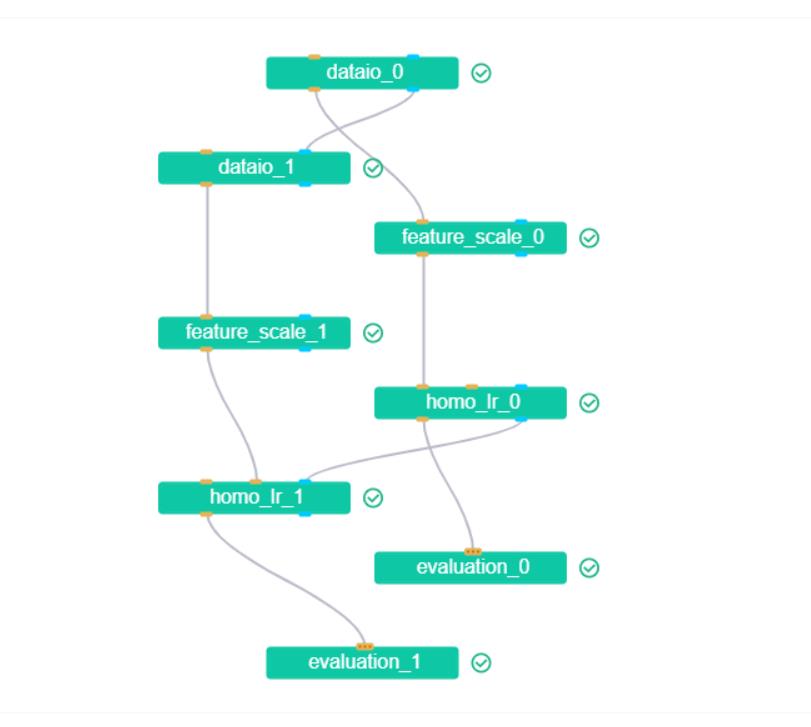
为了让任务模型的构建更加灵活,目前 FATE 使用了一套自定的领域特定语言 (DSL) 来描述任务。在 DSL 中,各种模块(例如数据读写 data_io,特征工程 feature-engineering, 回归 regression,分类 classification)可以通向一个有向无环图 (DAG) 组织起来。通过各种方式,用户可以根据自身的需要,灵活地组合各种算法模块。
除此之外,每个模块都有不同的参数需要配置,不同的 party 对于同一个模块的参数也可能有所区别。为了简化这种情况,对于每一个模块,FATE 会将所有 party 的不同参数保存到同一个运行配置文件(Submit Runtime Conf)中,并且所有的 party 都将共用这个配置文件。这个指南将会告诉你如何创建一个 DSL 配置文件。
官方的文档:DSL 配置和运行配置 V1 — FATE documentation
所以我们需要写一个DSL配置文件和Config文件。
1)DSL文件配置
文件名字:test_homolr_train_job_dsl.json
{
"components" : {
"dataio_0": {
"module": "DataIO",
"input": {
"data": {
"data": [
"args.train_data"
]
}
},
"output": {
"data": ["train"],
"model": ["dataio"]
}
},
"dataio_1": {
"module": "DataIO",
"input": {
"data": {
"data": [
"args.eval_data"
]
},
"model": ["dataio_0.dataio"]
},
"output": {
"data": ["eval_data"]
}
},
"feature_scale_0": {
"module": "FeatureScale",
"input": {
"data": {
"data": [
"dataio_0.train"
]
}
},
"output": {
"data": ["train"],
"model": ["feature_scale"]
}
},
"feature_scale_1": {
"module": "FeatureScale",
"input": {
"data": {
"data": [
"dataio_1.eval_data"
]
}
},
"output": {
"data": ["eval_data"],
"model": ["feature_scale"]
}
},
"homo_lr_0": {
"module": "HomoLR",
"input": {
"data": {
"train_data": [
"feature_scale_0.train"
]
}
},
"output": {
"data": [
"train"
],
"model": ["homolr"]
}
},
"homo_lr_1": {
"module": "HomoLR",
"input": {
"data": {
"eval_data": [
"feature_scale_1.eval_data"
]
},
"model": [
"homo_lr_0.homolr"
]
},
"output": {
"data": [
"eval_data"
],
"model": ["homolr"]
}
},
"evaluation_0": {
"module": "Evaluation",
"input": {
"data": {
"data": [
"homo_lr_0.train"
]
}
}
},
"evaluation_1": {
"module": "Evaluation",
"input": {
"data": {
"data": [
"homo_lr_1.eval_data"
]
}
}
}
}
}
我在DSL里面配置了训练集组件和验证集组件,这个组件的配置在单机版的横向联邦中提到过。
2)Config配置文件
文件名字:test_homolr_train_job_conf.json
{
"initiator": {
"role": "guest",
"party_id": 9999
},
"job_parameters": {
"work_mode": 1
},
"role": {
"guest": [
9999
],
"host": [
10000,8888
],
"arbiter": [
9999
]
},
"role_parameters": {
"guest": {
"args": {
"data": {
"train_data": [
{
"name": "homo_breast_2_train",
"namespace": "homo_host_breast_train"
}
],
"eval_data": [
{
"name": "homo_breast_eval",
"namespace": "homo_host_breast_eval"
}
]
}
},
"dataio_0": {
"label_name": ["y"]
}
},
"host": {
"args": {
"data": {
"train_data": [
{
"name": "homo_breast_1_train",
"namespace": "homo_host_breast_train"
},
{
"name": "homo_breast_2_train",
"namespace": "homo_host_breast_train"
}
],
"eval_data": [
{
"name": "homo_breast_eval",
"namespace": "homo_host_breast_eval"
},
{
"name": "homo_breast_eval",
"namespace": "homo_host_breast_eval"
}
]
}
},
"dataio_0": {
"label_name": ["y","y"]
},
"evaluation_0": {
"need_run": [
false,false
]
}
}
},
"algorithm_parameters": {
"dataio_0": {
"with_label": true,
"label_name": "y",
"label_type": "int",
"output_format": "dense"
},
"homo_lr_0": {
"penalty": "L2",
"optimizer": "sgd",
"tol": 1e-05,
"alpha": 0.01,
"max_iter": 10,
"early_stop": "diff",
"batch_size": 500,
"learning_rate": 0.15,
"decay": 1,
"decay_sqrt": true,
"init_param": {
"init_method": "zeros"
},
"encrypt_param": {
"method": null
},
"cv_param": {
"n_splits": 4,
"shuffle": true,
"random_seed": 33,
"need_cv": false
}
}
}
}
写完上面的配置文件后,将他们放到guest的chapter05文件夹下面,然后就可以开始训练了。
在fate02的chapter05中,启动虚拟环境,执行训练。
cd /data/projects/fate/chapter05
source ../bin/init_env.sh
python ../python/fate_flow/fate_flow_client.py -f submit_job -c test_homolr_train_job_conf.json -d test_homolr_train_job_dsl.json
如果出现如下图的错误,说明flow的服务没有启动这时候就需要重启所有的服务,执行命令:
cd /data/projects/common/supervisord
sh service.sh restart all

然后在执行提交任务的指令,出现下面的信息就说明任务提交成功。
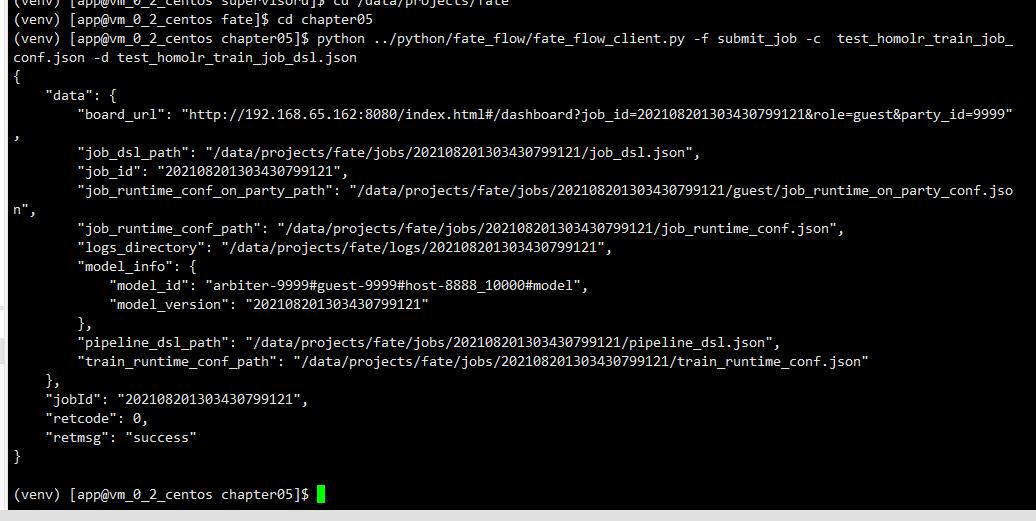
查看fate01、fate02、fate03的运行状态,如下图:
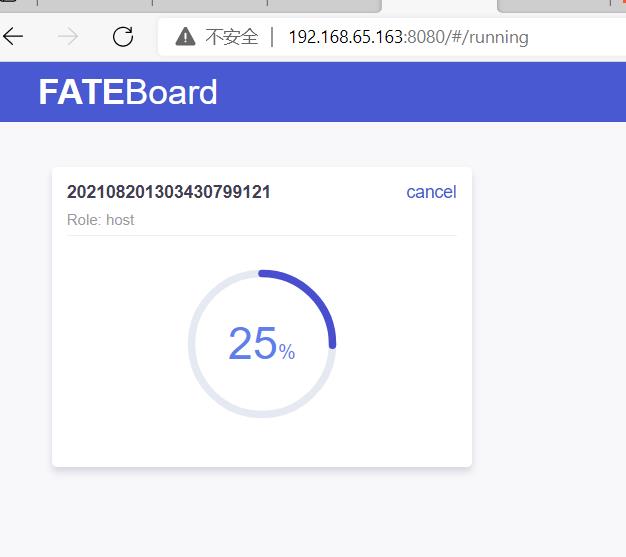
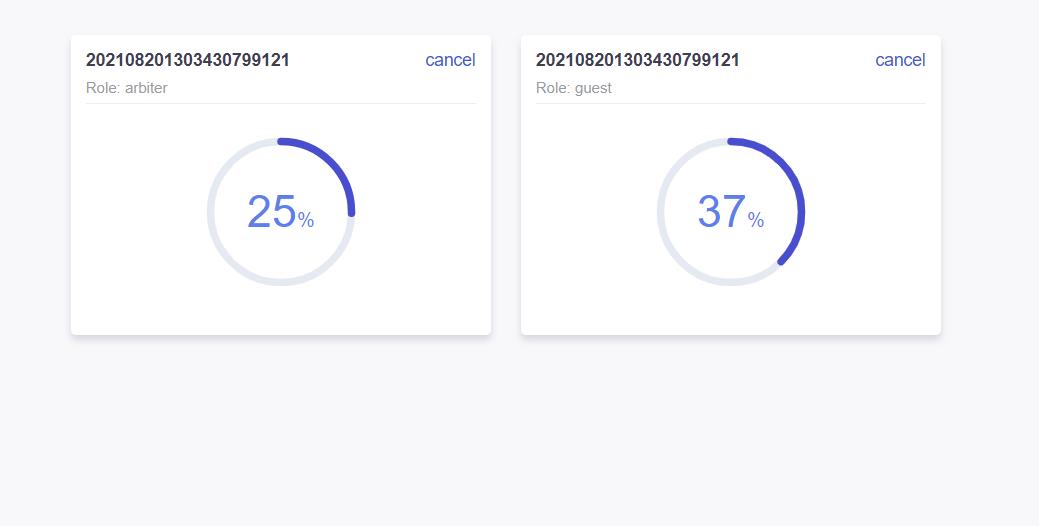
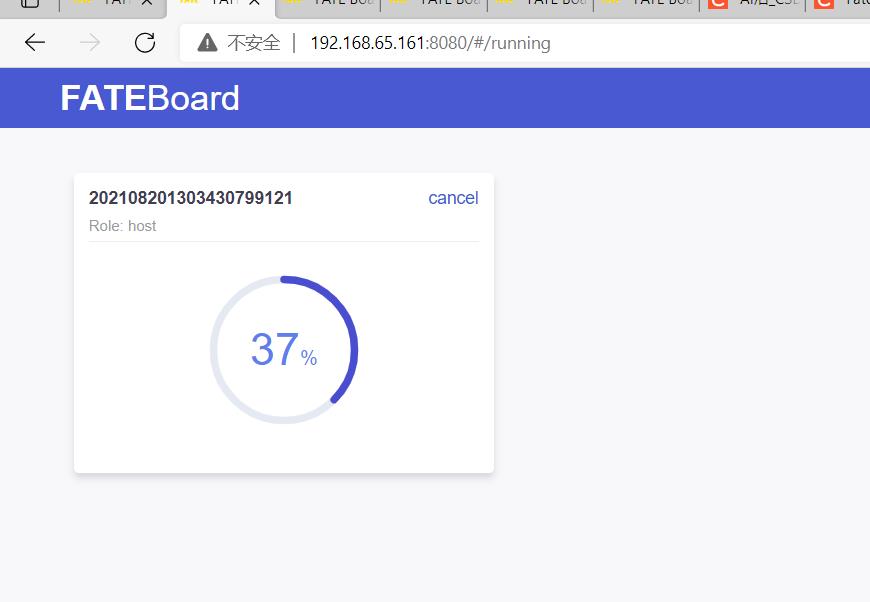
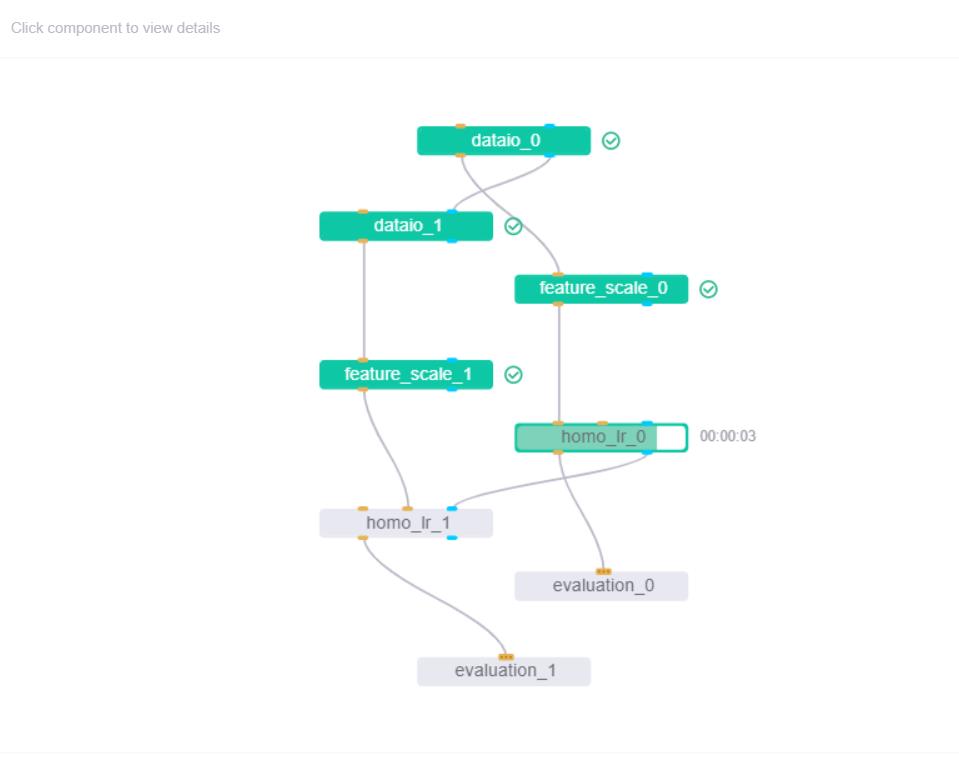
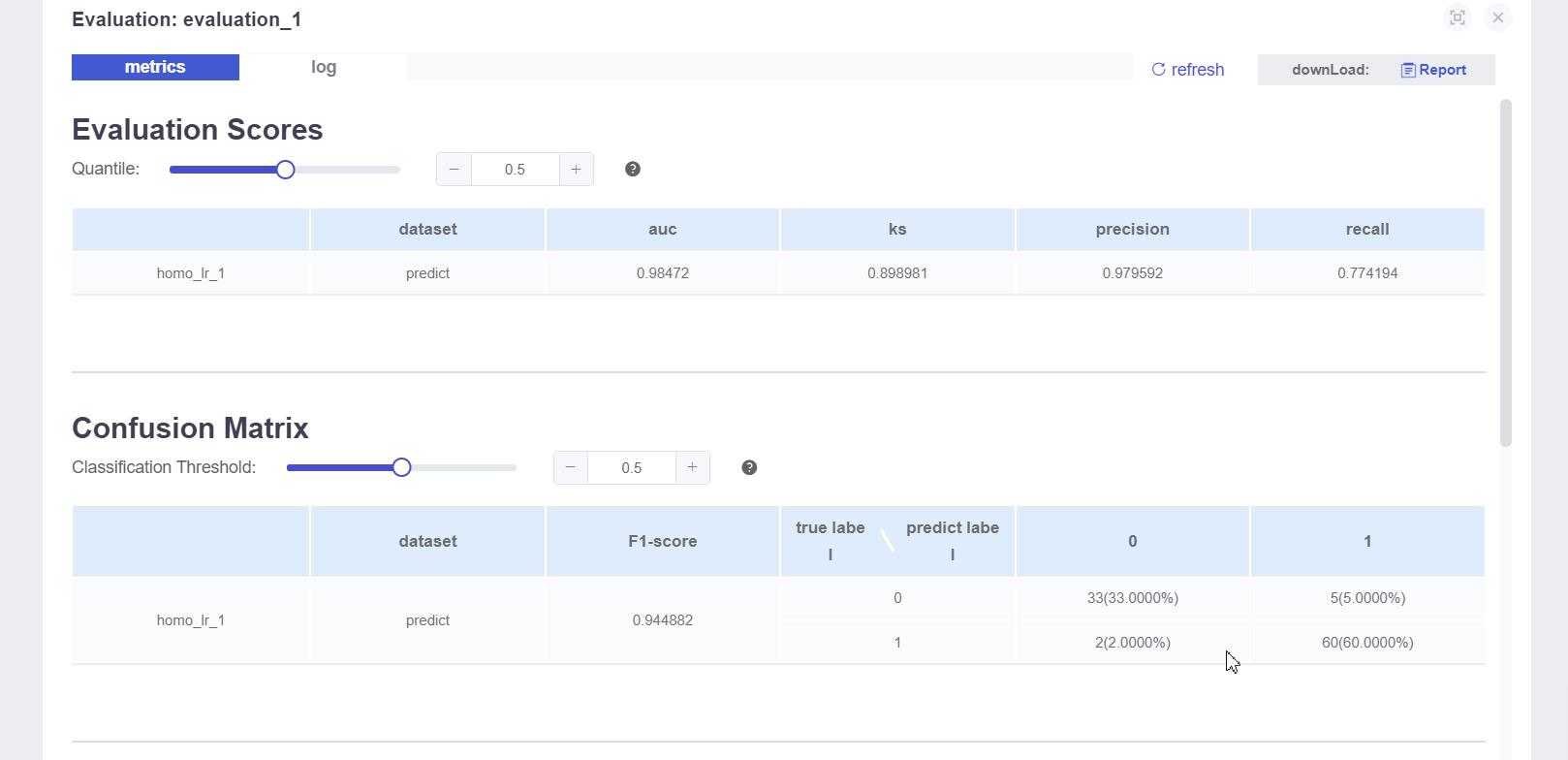
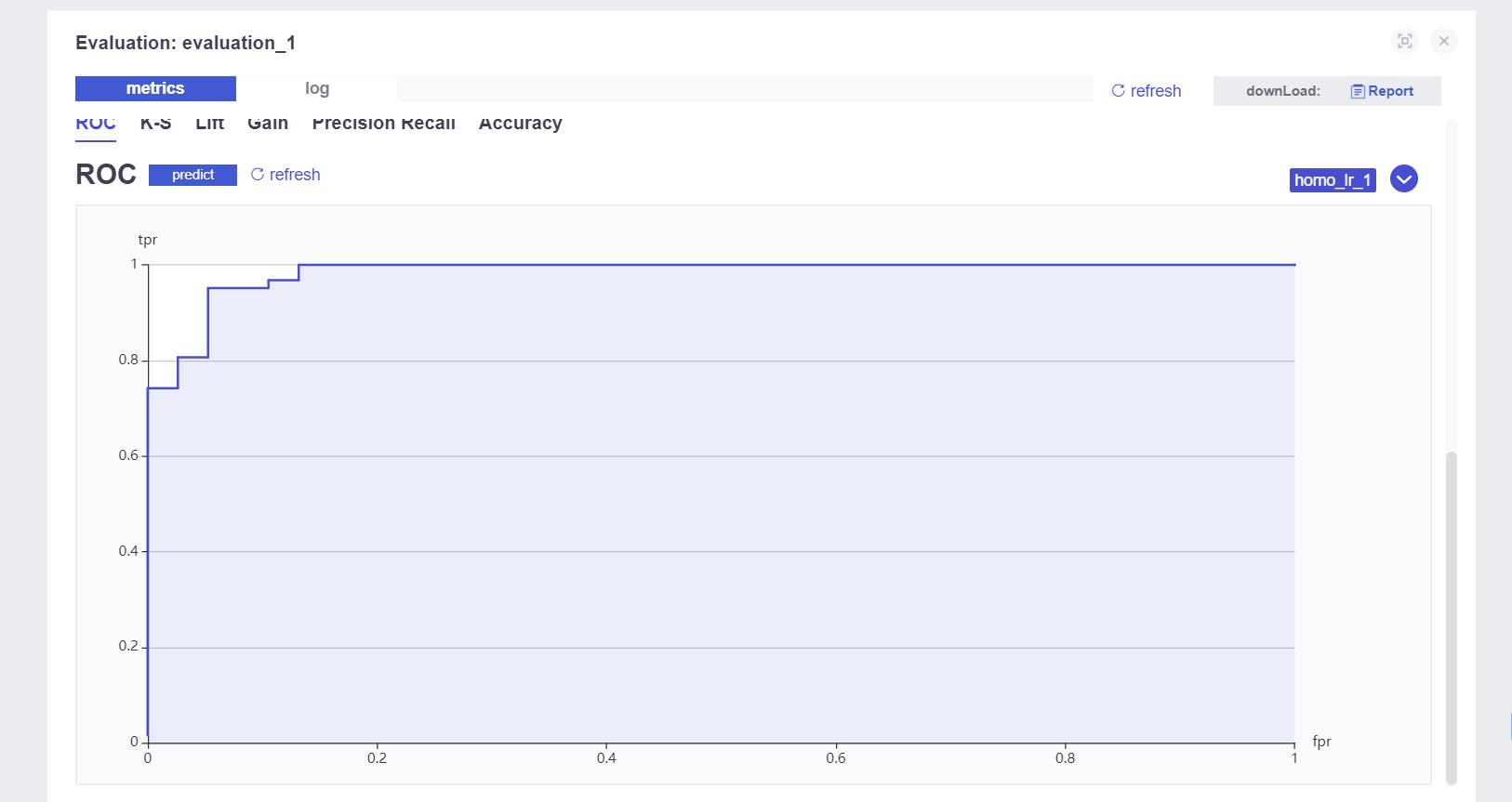
看到下图所有的训练组件变成绿色,恭喜你,成功了!!!

以上是关于Fate实战——实现集群横向逻辑回归的主要内容,如果未能解决你的问题,请参考以下文章