HBase眼高手低从Shell到IDEA编程心路笔记踩坑过程
Posted Data+Science+Insight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase眼高手低从Shell到IDEA编程心路笔记踩坑过程相关的知识,希望对你有一定的参考价值。
HBase眼高手低从Shell到IDEA编程、心路笔记、踩坑过程
HBase眼高手低
通过shell操作Hbase
Foundation
在terminal中输入hbase,就可以查看hbase命令的使用:
[root@big]# hbase
Usage: hbase [<options>] <command> [<args>]
Options:
--config DIR Configuration direction to use. Default: ./conf
--hosts HOSTS Override the list in 'regionservers' file
Commands:
Some commands take arguments. Pass no args or -h for usage.
Dare you don’t see this!!!
shell Run the HBase shell
hbck Run the hbase 'fsck' tool
snapshot Create a new snapshot of a table
wal Write-ahead-log analyzer
hfile Store file analyzer
zkcli Run the ZooKeeper shell
upgrade Upgrade hbase
master Run an HBase HMaster node
regionserver Run an HBase HRegionServer node
zookeeper Run a Zookeeper server
rest Run an HBase REST server
thrift Run the HBase Thrift server
thrift2 Run the HBase Thrift2 server
clean Run the HBase clean up script
classpath Dump hbase CLASSPATH
mapredcp Dump CLASSPATH entries required by mapreduce
pe Run PerformanceEvaluation
ltt Run LoadTestTool
version Print the version
CLASSNAME Run the class named CLASSNAME
正如commands后面的提示,有些命令需要参数,但是没有关系,student take it easy,开发人员已经尽力使得一切变得容易了。
慢慢来比较快。
[root@big]# hbase upgrade
usage: $bin/hbase upgrade -check [-dir DIR]|-execute
-check Run upgrade check; looks for HFileV1 under ${hbase.rootdir}
or provided 'dir' directory.
-dir <arg> Relative path of dir to check for HFileV1s.
-execute Run upgrade; zk and hdfs must be up, hbase down
-h,--help Help
Read http://hbase.apache.org/book.html#upgrade0.96 before attempting upgrade
Example usage:
Run upgrade check; looks for HFileV1s under ${hbase.rootdir}:
$ bin/hbase upgrade -check
Run the upgrade:
$ bin/hbase upgrade –execute
[root@big]# hbase shell -h
Usage: shell [OPTIONS] [SCRIPTFILE [ARGUMENTS]]
--format=OPTION Formatter for outputting results.
Valid options are: console, html.
(Default: console)
-d | --debug Set DEBUG log levels.
-h | --help This help.
-n | --noninteractive Do not run within an IRB session
and exit with non-zero status on
first error.
[root@big]# hbase shell
15/10/09 10:35:10 INFO Configuration.deprecation: hadoop.native.lib is deprecated. Instead, use io.native.lib.available
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 1.0.0-cdh5.4.2, rUnknown, Tue May 19 17:07:29 PDT 2015
hbase(main):001:0>
进入Hbase shell后人家有给你提供了一次帮助:
HBase Shell; enter 'help<RETURN>' for list of supported commands.
do something
创建表
create 'table_name','cf1','cf2','cf3'
Example:
hbase(main):002:0> create 'users','user_id','address','info'
0 row(s) in 0.8740 seconds
=> Hbase::Table – users
创建表的时候可以不加列名,加入数据的时候再具体申明,这就是为什么Hbase这么灵活了。
那么不加列族名那???
查看有哪些表
Example:
hbase(main):003:0> list
TABLE
users
1 row(s) in 0.0080 seconds
=> ["users"]
查看表结构
desc 't1'
describe 't1'
Example:
hbase(main):007:0> describe
ERROR: wrong number of arguments (0 for 1)
Here is some help for this command:
Describe the named table. For example:
hbase> describe 't1'
hbase> describe 'ns1:t1'
Alternatively, you can use the abbreviated 'desc' for the same thing.
hbase> desc 't1'
hbase> desc 'ns1:t1'
hbase(main):008:0> describe 'users'
Table users is ENABLED
users
COLUMN FAMILIES DESCRIPTION
{NAME => 'address', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE'
, MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}
{NAME => 'info', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE', M
IN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}
{NAME => 'user_id', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE'
, MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}
3 row(s) in 0.0270 seconds
注意:每一个列族对应一个{}进行相关属性的描述。
删除表
注意:删除表分为两步,第一步先disable这张表,然后再删除该表
disable 't1'
drop 't1'
Example:
hbase(main):018:0> disable 'users'
0 row(s) in 1.3070 seconds
hbase(main):019:0> drop 'users'
0 row(s) in 0.1830 seconds
hbase(main):020:0> list
TABLE
0 row(s) in 0.0060 seconds
=> []
添加数据
hbase(main):001:0> put 'users','xiaoming','info:age','24'
0 row(s) in 0.2950 seconds
hbase(main):002:0> put 'users','xiaoming','info:birthday','1987-04-24'
0 row(s) in 0.0100 seconds
hbase(main):003:0> put 'users','xiaoming','info:company','Alibaba'
0 row(s) in 0.0080 seconds
hbase(main):004:0> put 'users','xiaoming','address:country','China'
0 row(s) in 0.0080 seconds
hbase(main):005:0> put 'users','xiaoming','address:province','Zhejiang'
0 row(s) in 0.0110 seconds
hbase(main):006:0> put 'users','xiaoming','address:city','HangZhou'
0 row(s) in 0.0080 seconds
hbase(main):007:0> put 'users','zhangsan','info:birthday','1999-09-06'
0 row(s) in 0.0190 seconds
hbase(main):008:0> put 'users','zhangsan','info:favourite','football'
0 row(s) in 0.0080 seconds
hbase(main):009:0> put 'users','zhangsan','info:company','Tecent'
0 row(s) in 0.0110 seconds
hbase(main):010:0> put 'users','zhangsan','info:country','China'
0 row(s) in 0.0090 seconds
hbase(main):011:0> put 'users','zhangsan','info:province','Fujian'
0 row(s) in 0.0090 seconds
hbase(main):012:0> put 'users','zhangsan','info:city','Xiamen'
0 row(s) in 0.0270 seconds
hbase(main):013:0> put 'users','zhangsan','info:town','daxuecheng'
0 row(s) in 0.0080 seconds
查询
KeyàValue
hbase(main):014:0> get 'users','xiaoming'
COLUMN CELL
address:city timestamp=1444360941172, value=HangZhou
address:country timestamp=1444360876501, value=China
address:province timestamp=1444360906626, value=Zhejiang
info:age timestamp=1444360701107, value=24
info:birthday timestamp=1444360779743, value=1987-04-24
info:company timestamp=1444360818861, value=Alibaba
6 row(s) in 0.0300 seconds
hbase(main):015:0> get 'users','zhangsan'
COLUMN CELL
info:birthday timestamp=1444361085631, value=1999-09-06
info:city timestamp=1444361275813, value=Xiamen
info:company timestamp=1444361177871, value=Tecent
info:country timestamp=1444361203037, value=China
info:favourite timestamp=1444361121247, value=football
info:province timestamp=1444361245038, value=Fujian
info:town timestamp=1444361343392, value=daxuecheng
7 row(s) in 0.0150 seconds
虽然在同一张表里但是,他们的列尽然可以不相同。
hbase(main):016:0> get 'users','xiaoming','address:city'
COLUMN CELL
address:city timestamp=1444360941172, value=HangZhou
1 row(s) in 0.0220 seconds
修改信息
修改小明的city值,see what happen
hbase(main):018:0> put 'users','xiaoming','address:city','Zhoushan'
0 row(s) in 0.0120 seconds
hbase(main):019:0> get 'users','xiaoming','address:city'
COLUMN CELL
address:city timestamp=1444361861897, value=Zhoushan
1 row(s) in 0.0110 seconds
如果想显示所有的时间戳下的数据,该怎么做那?
查看版本数据
Student进行版本查看,可是只看到了一个。
hbase(main):008:0> get 'users','xiaoming',{COLUMN => 'address:city',VERSIONS => 3}
COLUMN CELL
address:city timestamp=1444361861897, value=Zhoushan
1 row(s) in 0.0080 seconds
所以,student查看表的描述
hbase(main):007:0> desc 'users'
Table users is ENABLED
users
COLUMN FAMILIES DESCRIPTION
{NAME => 'address', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE'
, MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}
{NAME => 'info', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE', M
IN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}
{NAME => 'user_id', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE'
, MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}
3 row(s) in 0.1170 seconds
问题原来在这里!
注意表的描述是由几个{}构成的(恰好是每个列族进行一次属性描述),所以倒逼思维,student想到,那么建表的时候是可以对这些属性进行自定义的指定的。
查询表中的所有信息
hbase(main):009:0> scan 'users'
ROW COLUMN+CELL
xiaoming column=address:city, timestamp=1444361861897, value=Zhoushan
xiaoming column=address:country, timestamp=1444360876501, value=China
xiaoming column=address:province, timestamp=1444360906626, value=Zhejiang
xiaoming column=info:age, timestamp=1444360701107, value=24
xiaoming column=info:birthday, timestamp=1444360779743, value=1987-04-24
xiaoming column=info:company, timestamp=1444360818861, value=Alibaba
zhangsan column=info:birthday, timestamp=1444361085631, value=1999-09-06
zhangsan column=info:city, timestamp=1444361275813, value=Xiamen
zhangsan column=info:company, timestamp=1444361177871, value=Tecent
zhangsan column=info:country, timestamp=1444361203037, value=China
zhangsan column=info:favourite, timestamp=1444361121247, value=football
zhangsan column=info:province, timestamp=1444361245038, value=Fujian
zhangsan column=info:town, timestamp=1444361343392, value=daxuecheng
2 row(s) in 0.0540 seconds
为什么是2 row(s),因为这里面xiaoming和zhangsan就是rowkey。
删除某列
hbase(main):010:0> get 'users','xiaoming','info:age'
COLUMN CELL
info:age timestamp=1444360701107, value=24
1 row(s) in 0.0090 seconds
hbase(main):011:0> delete 'users','xiaoming','info:age'
0 row(s) in 0.0450 seconds
hbase(main):012:0> get 'users','xiaoming','info:age'
COLUMN CELL
0 row(s) in 0.0080 seconds
删除整行数据
hbase(main):013:0> get 'users','xiaoming'
COLUMN CELL
address:city timestamp=1444361861897, value=Zhoushan
address:country timestamp=1444360876501, value=China
address:province timestamp=1444360906626, value=Zhejiang
info:birthday timestamp=1444360779743, value=1987-04-24
info:company timestamp=1444360818861, value=Alibaba
5 row(s) in 0.0130 seconds
hbase(main):014:0> deleteall 'users','xiaoming'
0 row(s) in 0.0080 seconds
hbase(main):015:0> get 'users','xiaoming'
COLUMN CELL
0 row(s) in 0.0060 seconds
统计表中数据的行数(即rowkey的个数)
hbase(main):016:0> count 'users'
1 row(s) in 0.0210 seconds
=> 1
清空表数据
hbase(main):017:0> truncate 'users'
Truncating 'users' table (it may take a while):
- Disabling table...
- Truncating table...
0 row(s) in 1.8630 seconds
注意:步骤依旧是需要先对表进行disable操作。
Hbase try to help you
Student实验在创建表的时候对版本数目进行描述。
看看看:
Hbase try to help you. Amazing, so many explanation and examples;
hbase(main):024:0> create 'users','user_id','address','info',{NAME => 'address',VERSIONS=>3}
Family 'address' already exists, the old one will be replaced
ERROR: Table already exists: users!
Here is some help for this command:
Creates a table. Pass a table name, and a set of column family
specifications (at least one), and, optionally, table configuration.
Column specification can be a simple string (name), or a dictionary
(dictionaries are described below in main help output), necessarily
including NAME attribute.
Examples:
Create a table with namespace=ns1 and table qualifier=t1
hbase> create 'ns1:t1', {NAME => 'f1', VERSIONS => 5}
Create a table with namespace=default and table qualifier=t1
hbase> create 't1', {NAME => 'f1'}, {NAME => 'f2'}, {NAME => 'f3'}
hbase> # The above in shorthand would be the following:
hbase> create 't1', 'f1', 'f2', 'f3'
hbase> create 't1', {NAME => 'f1', VERSIONS => 1, TTL => 2592000, BLOCKCACHE => true}
hbase> create 't1', {NAME => 'f1', CONFIGURATION => {'hbase.hstore.blockingStoreFiles' => '10'}}
Table configuration options can be put at the end.
Examples:
hbase> create 'ns1:t1', 'f1', SPLITS => ['10', '20', '30', '40']
hbase> create 't1', 'f1', SPLITS => ['10', '20', '30', '40']
hbase> create 't1', 'f1', SPLITS_FILE => 'splits.txt', OWNER => 'johndoe'
hbase> create 't1', {NAME => 'f1', VERSIONS => 5}, METADATA => { 'mykey' => 'myvalue' }
hbase> # Optionally pre-split the table into NUMREGIONS, using
hbase> # SPLITALGO ("HexStringSplit", "UniformSplit" or classname)
hbase> create 't1', 'f1', {NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
hbase> create 't1', 'f1', {NUMREGIONS => 15, SPLITALGO => 'HexStringSplit', REGION_REPLICATION => 2, CONFIGURATION => {'hbase.hregion.scan.loadColumnFamiliesOnDemand' => 'true'}}
You can also keep around a reference to the created table:
hbase> t1 = create 't1', 'f1'
Which gives you a reference to the table named 't1', on which you can then
call methods.
这是什么?
hbase(main):001:0> desc 'users'
Table users is ENABLED
users
COLUMN FAMILIES DESCRIPTION
{NAME => 'address', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS => '3', COMPRESSION => 'NONE'
, MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}
{NAME => 'info', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE', M
IN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}
{NAME => 'user_id', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE'
, MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}
3 row(s) in 0.4290 seconds
分解他们:divide and conquor
NAME => 'address'
DATA_BLOCK_ENCODING => 'NONE'
BLOOMFILTER => 'ROW'
REPLICATION_SCOPE => '0'
VERSIONS => '3'
COMPRESSION => 'NONE'
MIN_VERSIONS => '0'
TTL => 'FOREVER'
KEEP_DELETED_CELLS => 'FALSE'
BLOCKSIZE => '65536'
IN_MEMORY => 'false'
BLOCKCACHE => 'true'
总结
- 慢慢来比较快
- 就像退出往往使用quit,exit,q,或者Q一样,求助的时候往往是-h,--help等。
- 所以说,没事敲敲help
- Hbase shell操作时候的习惯,敲错以后如何处理:delete,Backspace(倒回来)
在gradle中添加依赖包
第一,添加依赖包
compile 'org.apache.hbase:hbase-common:1.0.0-cdh5.4.2'
compile 'org.apache.hbase:hbase-examples:1.0.0-cdh5.4.2'
//hbase-client-1.0.0-cdh5.4.2.jar
compile 'org.apache.hbase:hbase-client:1.0.0-cdh5.4.2'
compile 'org.apache.hbase:hbase:1.0.0-cdh5.4.2'第二,添加配置文件
确保HBase环境已启动且能连接到CDH下不存在该问题。
将HBase环境的hbase-site.xml文件拷贝到Gradle工程的src/main/resources目录下。
类似student使用API进行HDFS的操作。

通过java api操作Hbase

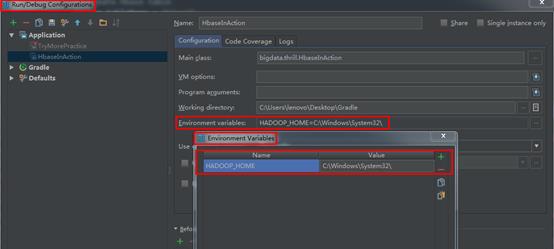
C:\\Windows\\System32\\


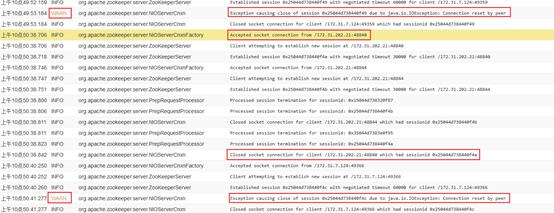
上CM平台查看Zookeeper的日志信息:
Source code
package bigdata.thrill;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.HTablePool;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.util.Bytes;
public class HbaseInAction {
// declare static configuration
static Configuration conf = null;
static {
conf = HBaseConfiguration.create();
//conf.set("hbase.zookeeper.quorum", "bigdata1,bigdata2,bigdata3");
//you can find this configuration information in hbase-site.xml.
}
public static void main(String[] args) throws Exception {
// create hbase table
String tableName = "blog2";
String[] family = { "article", "author" };
creatTable(tableName, family);
// put data to the table
String[] column1 = { "title", "content", "tag" };
String[] value1 = {
"Head First HBase",
"HBase is the Hadoop database. Use it when you need random, realtime read/write access to your Big Data.",
"Hadoop,HBase,NoSQL" };
String[] column2 = { "name", "nickname" };
String[] value2 = { "nicholas", "lee" };
addData("rowkey1", "blog2", column1, value1, column2, value2);
addData("rowkey2", "blog2", column1, value1, column2, value2);
addData("rowkey3", "blog2", column1, value1, column2, value2);
//CRUD:create read(retrieve) update delete
getResultScannAll("blog2");
// getResultScann("blog2", "rowkey4", "rowkey5");
// getResult("blog2", "rowkey1");
// getResultByColumn("blog2", "rowkey1", "author", "name");
// updateTable("blog2", "rowkey1", "author", "name", "bin");
// getResultByColumn("blog2", "rowkey1", "author", "name");
// getResultByVersion("blog2", "rowkey1", "author", "name");
// deleteColumn("blog2", "rowkey1", "author", "nickname");
// deleteAllColumn("blog2", "rowkey1");
// deleteTable("blog2");
}
/*
* 创建表
*
* @tableName 表名
*
* @family 列族列表
*/
public static void creatTable(String tableName, String[] family)
throws Exception {
HBaseAdmin admin = new HBaseAdmin(conf);
HTableDescriptor desc = new HTableDescriptor(tableName);
for (int i = 0; i < family.length; i++) {
desc.addFamily(new HColumnDescriptor(family[i]));
}
if (admin.tableExists(tableName)) {
System.out.println("table Exists!");
System.exit(0);
} else {
admin.createTable(desc);
System.out.println("create table Success!");
}
}
/*
* 为表添加数据(适合知道有多少列族的固定表)
*
* @rowKey rowKey
*
* @tableName 表名
*
* @column1 第一个列族列表
*
* @value1 第一个列的值的列表
*
* @column2 第二个列族列表
*
* @value2 第二个列的值的列表
*/
public static void addData(String rowKey, String tableName,
String[] column1, String[] value1, String[] column2, String[] value2)
throws IOException {
Put put = new Put(Bytes.toBytes(rowKey));// 设置rowkey
HTable table = new HTable(conf, Bytes.toBytes(tableName));// HTabel负责跟记录相关的操作如增删改查等//
// 获取表
HColumnDescriptor[] columnFamilies = table.getTableDescriptor().getColumnFamilies();
// 获取所有的列族
for (int i = 0; i < columnFamilies.length; i++) {
String familyName = columnFamilies[i].getNameAsString(); // 获取列族名
if (familyName.equals("article")) { // article列族put数据
for (int j = 0; j < column1.length; j++) {
put.add(Bytes.toBytes(familyName),
Bytes.toBytes(column1[j]), Bytes.toBytes(value1[j]));
}
}
if (familyName.equals("author")) { // author列族put数据
for (int j = 0; j < column2.length; j++) {
put.add(Bytes.toBytes(familyName),
Bytes.toBytes(column2[j]), Bytes.toBytes(value2[j]));
}
}
}
table.put(put);
System.out.println("add data Success!");
}
/*
* 根据rwokey查询
*
* @rowKey rowKey
*
* @tableName 表名
*/
public static Result getResult(String tableName, String rowKey)
throws IOException {
Get get = new Get(Bytes.toBytes(rowKey));
HTable table = new HTable(conf, Bytes.toBytes(tableName));// 获取表
Result result = table.get(get);
for (KeyValue kv : result.list()) {
System.out.println("family:" + Bytes.toString(kv.getFamily()));
System.out.println("qualifier:" + Bytes.toString(kv.getQualifier()));
System.out.println("value:" + Bytes.toString(kv.getValue()));
System.out.println("Timestamp:" + kv.getTimestamp());
System.out.println("-------------------------------------------");
}
return result;
}
/*
* 遍历查询hbase表
*
* 进行全表的查询,不指定rowkey的范围
*
* @tableName 表名
*/
public static void getResultScannAll(String tableName) throws IOException {
Scan scan = new Scan();
ResultScanner rs = null;
HTable table = new HTable(conf, Bytes.toBytes(tableName));
try {
rs = table.getScanner(scan);
for (Result r : rs) {
for (KeyValue kv : r.list()) {
System.out.println("row:" + Bytes.toString(kv.getRow()));
System.out.println("family:"
+ Bytes.toString(kv.getFamily()));
System.out.println("qualifier:"
+ Bytes.toString(kv.getQualifier()));
System.out
.println("value:" + Bytes.toString(kv.getValue()));
System.out.println("timestamp:" + kv.getTimestamp());
System.out
.println("-------------------------------------------");
}
}
} finally {
rs.close();
}
}
/*
* 遍历查询hbase表
*
* 指定起始和结束的rowkey
*
* @tableName 表名
*/
public static void getResultScann(String tableName, String start_rowkey,
String stop_rowkey) throws IOException {
Scan scan = new Scan();
scan.setStartRow(Bytes.toBytes(start_rowkey));
scan.setStopRow(Bytes.toBytes(stop_rowkey));
ResultScanner rs = null;
HTable table = new HTable(conf, Bytes.toBytes(tableName));
try {
rs = table.getScanner(scan);
for (Result r : rs) {
for (KeyValue kv : r.list()) {
System.out.println("row:" + Bytes.toString(kv.getRow()));
System.out.println("family:"
+ Bytes.toString(kv.getFamily()));
System.out.println("qualifier:"
+ Bytes.toString(kv.getQualifier()));
System.out
.println("value:" + Bytes.toString(kv.getValue()));
System.out.println("timestamp:" + kv.getTimestamp());
System.out
.println("-------------------------------------------");
}
}
} finally {
rs.close();
}
}
/*
* 查询表中的某一列
*
* @tableName 表名
*
* @rowKey rowKey
*/
public static void getResultByColumn(String tableName, String rowKey,
String familyName, String columnName) throws IOException {
HTable table = new HTable(conf, Bytes.toBytes(tableName));
Get get = new Get(Bytes.toBytes(rowKey));
get.addColumn(Bytes.toBytes(familyName), Bytes.toBytes(columnName)); // 获取指定列族和列修饰符对应的列
Result result = table.get(get);
for (KeyValue kv : result.list()) {
System.out.println("family:" + Bytes.toString(kv.getFamily()));
System.out
.println("qualifier:" + Bytes.toString(kv.getQualifier()));
System.out.println("value:" + Bytes.toString(kv.getValue()));
System.out.println("Timestamp:" + kv.getTimestamp());
System.out.println("-------------------------------------------");
}
}
/*
* 更新表中的某一列
*
* @tableName 表名
*
* @rowKey rowKey
*
* @familyName 列族名
*
* @columnName 列名
*
* @value 更新后的值
*/
public static void updateTable(String tableName, String rowKey,
String familyName, String columnName, String value)
throws IOException {
HTable table = new HTable(conf, Bytes.toBytes(tableName));
Put put = new Put(Bytes.toBytes(rowKey));
put.add(Bytes.toBytes(familyName), Bytes.toBytes(columnName),
Bytes.toBytes(value));
table.put(put);
System.out.println("update table Success!");
}
/*
* 查询某列数据的多个版本
*
* @tableName 表名
*
* @rowKey rowKey
*
* @familyName 列族名
*
* @columnName 列名
*/
public static void getResultByVersion(String tableName, String rowKey,
String familyName, String columnName) throws IOException {
HTable table = new HTable(conf, Bytes.toBytes(tableName));
Get get = new Get(Bytes.toBytes(rowKey));
get.addColumn(Bytes.toBytes(familyName), Bytes.toBytes(columnName));
get.setMaxVersions(5);
Result result = table.get(get);
for (KeyValue kv : result.list()) {
System.out.println("family:" + Bytes.toString(kv.getFamily()));
System.out
.println("qualifier:" + Bytes.toString(kv.getQualifier()));
System.out.println("value:" + Bytes.toString(kv.getValue()));
System.out.println("Timestamp:" + kv.getTimestamp());
System.out.println("-------------------------------------------");
}
/*
* List<?> results = table.get(get).list(); Iterator<?> it =
* results.iterator(); while (it.hasNext()) {
* System.out.println(it.next().toString()); }
*/
}
/*
* 删除指定的列
*
* @tableName 表名
*
* @rowKey rowKey
*
* @familyName 列族名
*
* @columnName 列名
*/
public static void deleteColumn(String tableName, String rowKey,
String falilyName, String columnName) throws IOException {
HTable table = new HTable(conf, Bytes.toBytes(tableName));
Delete deleteColumn = new Delete(Bytes.toBytes(rowKey));
deleteColumn.deleteColumns(Bytes.toBytes(falilyName),
Bytes.toBytes(columnName));
table.delete(deleteColumn);
System.out.println(falilyName + ":" + columnName + "is deleted!");
}
/*
* 删除指定的行
*
* @tableName 表名
*
* @rowKey rowKey
*/
public static void deleteAllColumn(String tableName, String rowKey)
throws IOException {
HTable table = new HTable(conf, Bytes.toBytes(tableName));
Delete deleteAll = new Delete(Bytes.toBytes(rowKey));
table.delete(deleteAll);
System.out.println("all columns are deleted!");
}
/*
* 删除整张表
*
* @tableName 表名
*/
public static void deleteTable(String tableName) throws IOException {
HBaseAdmin admin = new HBaseAdmin(conf);
admin.disableTable(tableName);
admin.deleteTable(tableName);
System.out.println(tableName + "is deleted!");
}
}Hbase API 介绍
致敬:HBase总结(十一)hbase Java API 介绍及使用示例
几个相关类与HBase数据模型之间的对应关系
| java类 | HBase数据模型 |
| HBaseAdmin | 数据库(DataBase) |
| HBaseConfiguration | |
| HTable | 表(Table) |
| HTableDescriptor | 列族(Column Family) |
|
|