数据结构第四章:带头节点的拆链表
Posted 歌咏^0^
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构第四章:带头节点的拆链表相关的知识,希望对你有一定的参考价值。
目录
三、实现链表就地排序,也就是将一个已经建好的链表,根据某个数据(data),按照从小到大的顺序进行排列
四、利用两个有序链表的自身的结点,归并成一条链表,而且归并后的新链表也是有序的。
一、带头节点的链表
1、设计头结点(链表的管理结点)头结点 != 首结点
作用:用来管理整条链表,比如记录数据首节点的地址 记录 当前链表中数据结点的数量
struct list{
struct node *head; //记录链表中数据结点的首地址 数据首结点
int nodeNumber;//记录 链表中数据结点的数量
/*其他属性*/
}二、实现链表的就地自逆函数,也就是将链表数据颠倒
从头到尾 -----》 从尾到头
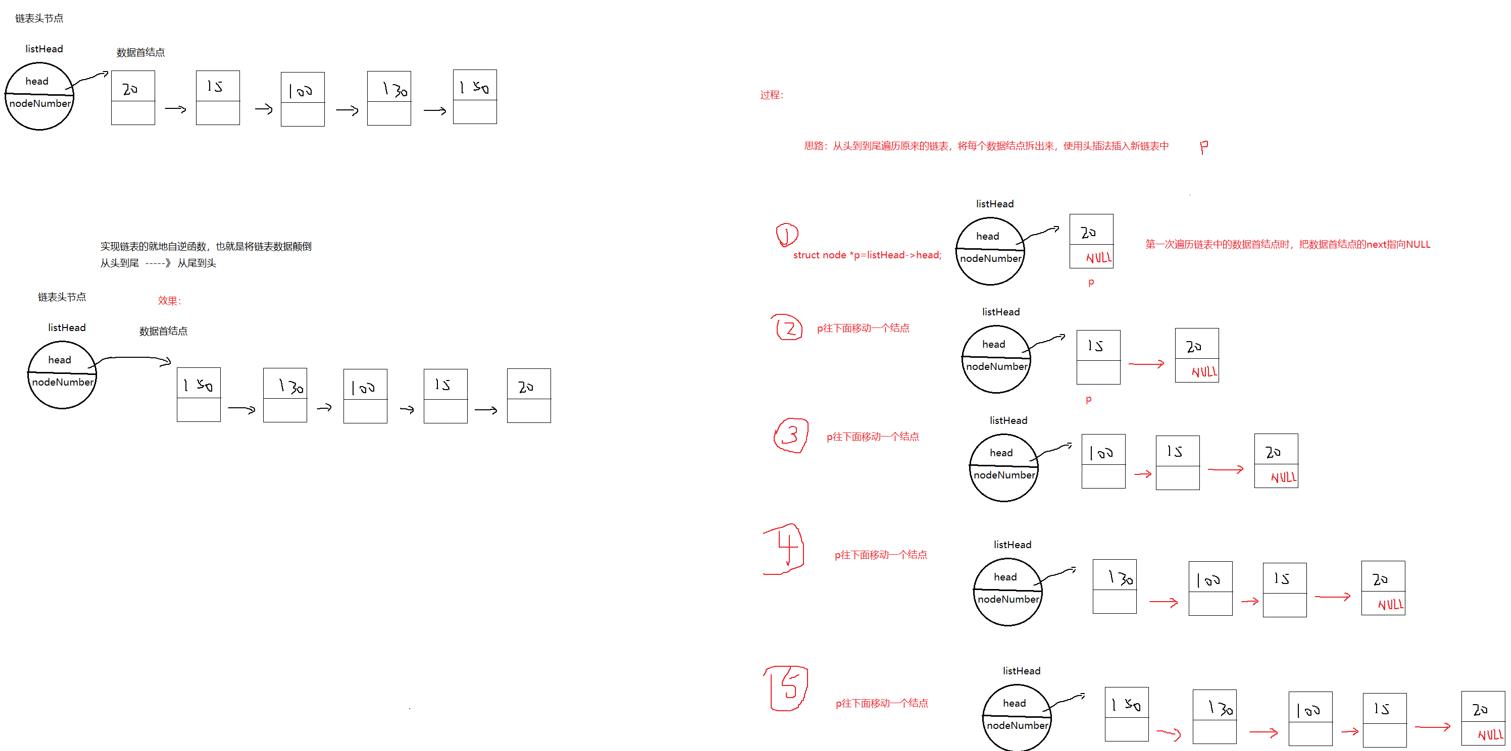
/*
reverse_allToList:实现链表的就地自逆函数,也就是将链表数据颠倒
从头到尾 -----》 从尾到头
返回值:返回 新链表的头节点
注意:所谓的链接或者指向 的意思是 当前结点的next指针变量存储下一个结点的地址
*/
struct list* reverse_allToList(struct list *listHead)
{
//1、遍历原本的链表 ,每个结点都拆下来
//2、遍历的时候,记录当前拆下来的链表结点p 和 当前结点的下一个结点nextNode
struct node *p = listHead->head;
struct node *nextNode=NULL;//记录当前结点的下一个结点
while(p)
{
nextNode = p->next;
//3、拆下来的每个结点 ,先断链接 p->next = NULL
p->next = NULL; //每次拆下来的结点先断链接
//最开始拆的是原链表的数据首结点
if(p == listHead->head)
{
//此时这里可以不做处理
}
else{ //拆的是 原链表中的 中间结点
//4、将拆下来的结点p 插入到新链表中,使用头插法,更新首结点
p->next = listHead->head;
listHead->head = p;
}
//p结点往下面移动
p = nextNode;
}
return listHead;
}三、实现链表就地排序,也就是将一个已经建好的链表,根据某个数据(data),按照从小到大的顺序进行排列
思路: 遍历原本的链表,从头到尾遍历,每个结点都拆下来,然后有序地插入到新链表中
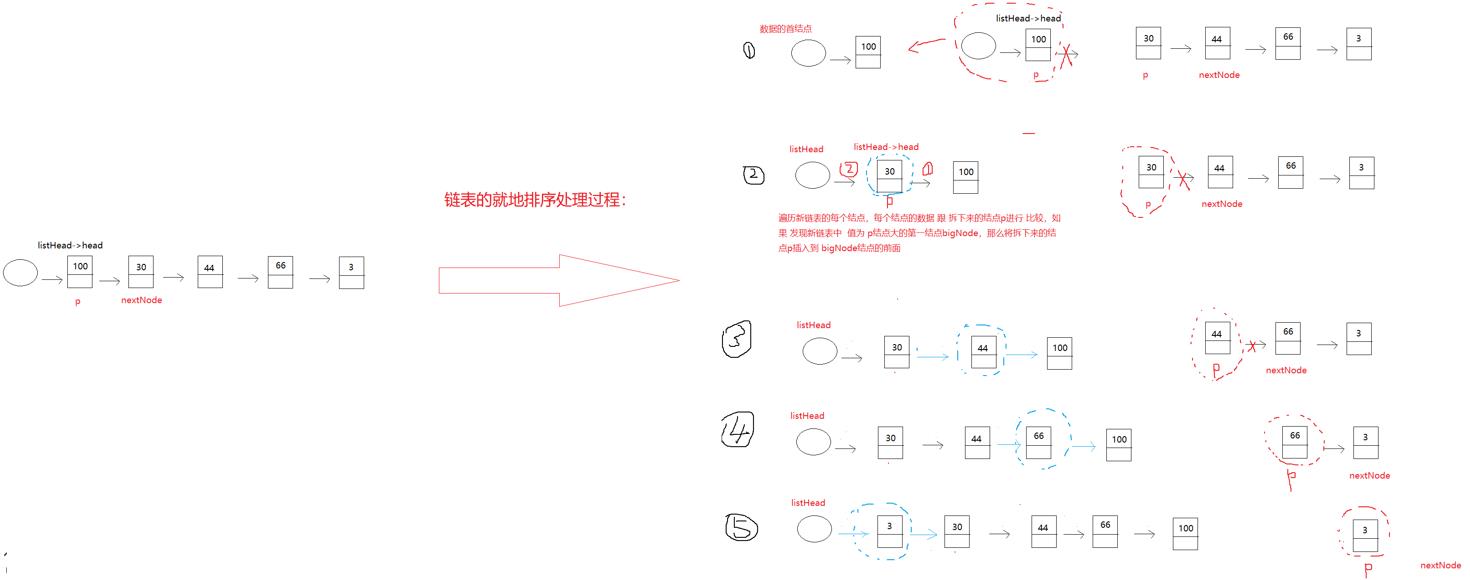
/*
sort_allToList:实现链表就地排序,也就是将一个已经建好的链表,根据某个数据(data),按照从小到大的顺序进行排列
思路: 遍历原本的链表,从头到尾遍历,每个结点都拆下来,然后有序地插入到新链表中
返回值:返回 新链表的头节点
*/
struct list* sort_allToList(struct list *listHead)
{
struct node *p = listHead->head;
struct node *nextNode=NULL;//记录当前结点的下一个结点
//1、遍历原链表 ,从头到尾遍历,每个结点都拆下来
while(p)
{
//2、遍历的时候 ,记录当前拆下来的结点p 和 下一个结点nextNode
nextNode = p->next;
//3、每个拆下来的结点 断链接
p->next = NULL;
//4、新链表从无到有 ,也就是 如果拆下来的结点是首结点 ,不做处理
if(p == listHead->head)
{
//此时这里可以不做处理
}
else{//拆下来的结点是中间结点 p
struct node *pnew = listHead->head;
struct node *prenew = NULL; //记录的是上一个结点
//遍历新链表的每个结点
while(pnew)
{
//找到了找到新链表中 值比 拆下来的p结点大的第一结点bigNode,
if(pnew->data > p->data)//
{
break;
}
else{
prenew = pnew;//记录的是上一个结点
pnew = pnew->next;
}
}
//遍历完成之后,有两种情况: //此时 pnew 就是 bigNode
//1、找到
if(pnew != NULL)
{
//那么将拆下来的结点p插入到 bigNode结点的前面
//1)如果找到bigNode结点是 首结点,使用头插
if(pnew == listHead->head)
{
//拆下来的结点p插在新链表的首结点前面
p->next = listHead->head;
listHead->head = p;
}
else{//找到的bigNode结点 是中间结点,使用中间插法
//prenew p pnew(bigNode)
p->next = pnew;
prenew->next = p;
}
}
else{//2、没找到 ,说明拆下来的结点p比新链表的每个结点都大,所以使用尾插
//prenew就是新链表的尾结点
prenew->next = p;
}
}
//p结点往下面移动
p = nextNode;
}
return listHead;
}四、利用两个有序链表的自身的结点,归并成一条链表,而且归并后的新链表也是有序的。
链表listA: 20 30 40 50 60 77 100
链表listB: 10 15 20 30 45 66 99
/*
merge_two_list:利用两条有序链表的自身的结点,归并成一条新链表,而且归并后的新链表也是有序的。
思路:1、先申请新链表的头节点,并且初始化-----
2、同时遍历两条链表pA和pB,每次进行比较结点的数据大小,小的结点从原链表中拆出来,拆的那条链表往下面移动一个结点,没拆的不动
3、拆出来的结点pnew 作为新结点插入到新链表中
4、循环操作上面两个步骤,直到有一条链表全部拆完,剩下的那条链表的所有结点 直接插入新链表的尾部
5、最后释放两条链表pA和pB的头结点
返回值:
返回 新链表头节点
*/
struct list* merge_two_list(struct list *listHeadA,struct list *listHeadB)
{
//1、先申请新链表的头节点
struct list *newHead = malloc(sizeof(struct list));
if(newHead == NULL)
{
printf("malloc newHead error\\n");
return NULL;
}
//初始化
newHead->head = NULL;
newHead->nodeNumber = listHeadA->nodeNumber + listHeadB->nodeNumber ;
struct node *pA = listHeadA->head;
struct node *pB = listHeadB->head;
struct node *pnew=NULL;//记录当前拆出来的结点
//2、同时遍历两条链表pA和pB,
while(pA && pB)
{
//每次比较两条链表结点的数据大小,小的结点从原链表中拆出来,拆的那条链表往下面一个结点,没拆的不动
if(pA->data < pB->data)//pA小,拆链表A的结点
{
//拆的那条链表往下面移动一个结点,没拆的不动
//1)移动之前先保存当前拆出来的结点
pnew = pA ;
//2)移动
pA = pA ->next;
//3、拆出来的结点的next指向NULL 也就是从原链表中断开链接
pnew->next = NULL;
}
else{ //pB小 拆链表B的结点
//1)移动之前先保存当前拆出来的结点
pnew = pB ;
//2)移动
pB = pB ->next;
//3、拆出来的结点的next指向NULL 也就是从原链表中断开链接
pnew->next = NULL;
}
//3、拆出来的结点pnew 作为新结点插入到新链表中
//如果新链表是空的,那么第一个拆出来的结点作为新链表的首结点
if(newHead->head == NULL)//从无到有
{
newHead->head = pnew;
}
else{//从少到多 ,使用尾插法
//遍历新链表,找出尾结点
struct node *p = newHead->head;
struct node *pre = NULL;
while(p)
{
pre = p;
p = p->next;
}
//此时 pre就是尾结点
pre->next = pnew;
}
}
//pnew就是新链表的尾结点
//剩下的那条链表的所有结点 直接插入新链表的尾部
if(pA !=NULL)//说明pA有剩余结点,而且剩余的结点都是有序的,因为原链表就是有序的
{
pnew->next = pA;
}
else{//说明pB有剩余结点
pnew->next = pB;
}
free(listHeadA);
free(listHeadB);
return newHead;
}
以上是关于数据结构第四章:带头节点的拆链表的主要内容,如果未能解决你的问题,请参考以下文章