[MNIST04]学习率和模型初调
Posted AIplusX
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[MNIST04]学习率和模型初调相关的知识,希望对你有一定的参考价值。
写在前面
前几天看了篇NLP的论文,写了篇论文阅读笔记,所以耽搁了几天,今天来继续更新啦~
今天主要是分享将纯python代码文件在GPU上跑起来,并且实现程序加速的程序,记录一下numba库的使用方法。在此基础上实现之前分享的神经网络。
正文
主要内容在我的古月居博客:
[MNIST04]学习率和模型初调
昨天遗留
1:我将MNIST的训练集文件取出了3.2w张(6w张训练时间实在是太久了),一个epoch训练3.2w张图片,并且在一个epoch中训练集换成了320份,每份100张,每次训练的时候会记录这100张训练集上的参数求均值再更新,这样可以使得梯度下降得更高效;
2:学习率对于模型表现的影响将在下面进行分析;
今日工作
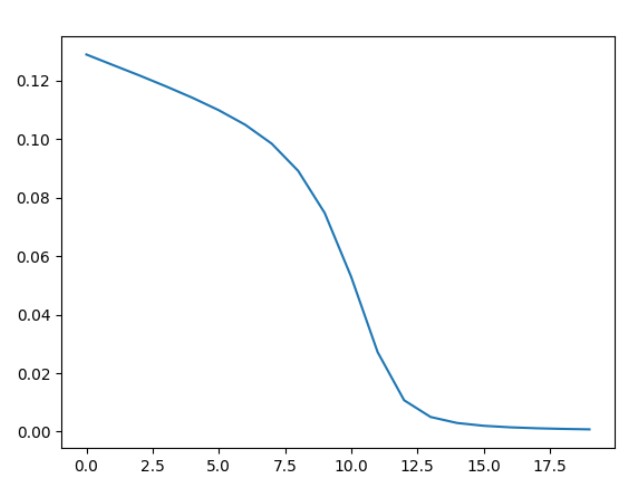
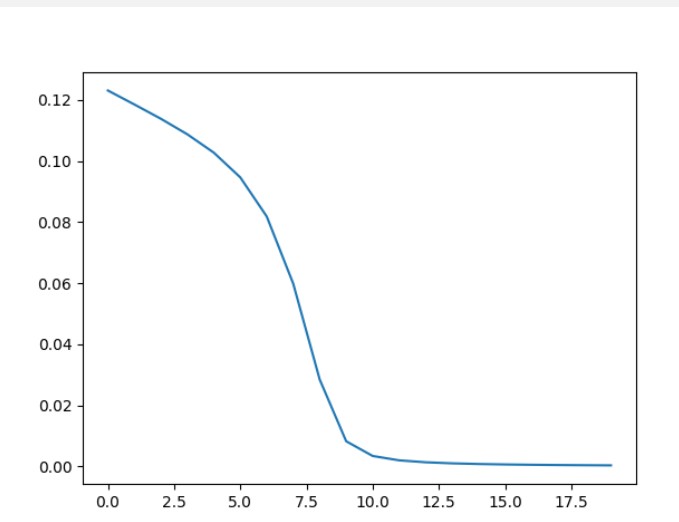
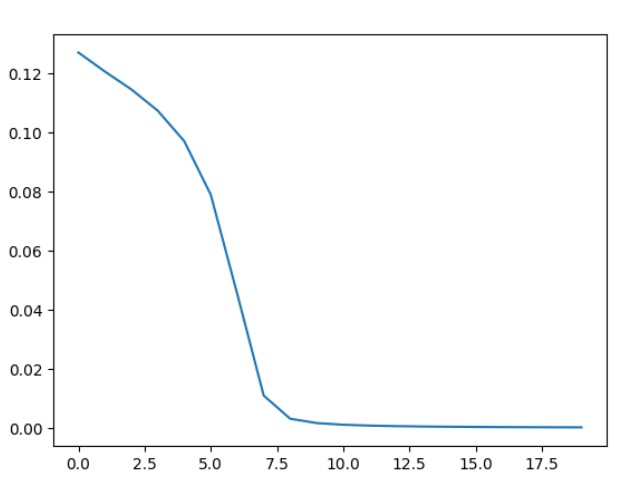
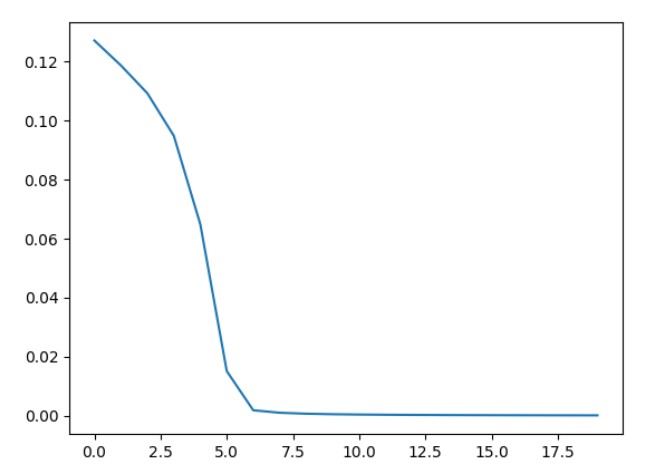
明天问题
1:初步使用ROC曲线等方法评估模型的性能;
正文
主要内容在我的古月居博客:
[MNIST04]学习率和模型初调

总体程序:
# from inputDataSet import DataSetProcess
from numba import jit
import numpy as np
import struct
# import matplotlib.pyplot as plt
import random
import datetime
import time
# import math
# import tensorflow as tf
total_n = 60000
verify_n = 10000
train_aside_n = 32000
epoch = 20
division = 100
study_step = 0.5
sub_train = train_aside_n / division
start_rand_max = 0.1
img_size_bit = struct.calcsize('>784B')
lab_size_bit = struct.calcsize('>1B')
n_num = 16
m_num = 16
total_x = 784
total_y = 10
# @jit
def readFile(type=0): # 0 is traindata,1 is testdata
if (type == 0):
with open('./dataSet/train-images.idx3-ubyte', 'rb') as ti:
train_image = ti.read()
with open('./dataSet/train-labels.idx1-ubyte', 'rb') as tl:
train_labels = tl.read()
return train_image, train_labels
elif (type == 1):
with open('./dataSet/t10k-images.idx3-ubyte', 'rb') as t_i:
test_image = t_i.read()
with open('./dataSet/t10k-labels.idx1-ubyte', 'rb') as t_l:
test_labels = t_l.read()
return test_image, test_labels
# @jit
def getImages(image, n, startidx=0):
img = []
index = struct.calcsize('>IIII') + img_size_bit * startidx
for i in range(n):
temp = struct.unpack_from('>784B', image, index)
img.append(np.reshape(temp, (28, 28)))
index += img_size_bit
return img
# @jit
def getLabels(label, n, startidx=0):
lab = []
index = struct.calcsize('>II') + lab_size_bit * startidx
for i in range(n):
temp = struct.unpack_from('>1B', label, index)
lab.append(temp[0])
index += lab_size_bit
return lab
@jit
def sigmoid(x):
s = 1 / (1 + np.exp(-x))
# print("sig:", s)
return s
@jit
def dsigmoid(x):
s = sigmoid(x) * (1 - sigmoid(x))
return s
@jit
def ReLU(x):
if x > 0:
s = x
else:
s = 0
return s
@jit
def dReLU(x):
if x > 0:
s = 1
else:
s = 0
return s
@jit
def normalization(x):
max = float(0)
min = float(999)
for i in range(0, total_x):
if (x[i] > max):
max = x[i]
elif (x[i] < min):
min = x[i]
for i in range(0, total_x):
x[i] = (x[i] - min) / (max - min)
# print(x)
return x
# @jit
def VerifyModel(verify_img, verify_lab):
# print("VerifyModel start")
right_cnt = 0
all_img = np.zeros(((verify_n, total_x)), dtype=float)
# print(verify_lab)
for i in range(verify_n):
all_img[i, :] = normalization((verify_img[i].flatten()).astype(float))
w = np.loadtxt("w.csv", delimiter=",")
v = np.loadtxt("v.csv", delimiter=",")
gamma= np.loadtxt("gamma.csv", delimiter=",")
theta_1 = np.loadtxt("theta_1.csv", delimiter=",")
theta_2 = np.loadtxt("theta_2.csv", delimiter=",")
theta_3 = np.loadtxt("theta_3.csv", delimiter=",")
for i in range(verify_n):
x = all_img[i]
max_y = 0
out_put_num = 10
m = np.dot(x, w) - theta_1
for j in range(m_num):
m_out[0][j] = ReLU(m[j])
n = np.dot(m_out, v) - theta_2
for j in range(n_num):
n_out[0][j] = ReLU(n[0][j])
y_pre = np.dot(n, gamma) - theta_3
for j in range(total_y):
y_out[0][j] = sigmoid(y_pre[0][j])
if y_out[0][j] > 0.8:
out_put_num = j
break
if out_put_num == verify_lab[i]:
right_cnt = right_cnt + 1
print("right/total: %d/%d ,rightpercent: %.3f" % (right_cnt , verify_n, (right_cnt/verify_n)))
@jit
def TrainBody(w, v, gamma, theta_1, theta_2, theta_3, x,\\
dw, dv, dgamma, dtheta_1, dtheta_2, dtheta_3, \\
m, m_out, n, n_out, y, y_out, y_pre):
for i in range(total_y):
dtheta_3[0][i] = dtheta_3[0][i] + (y[0][i] - y_out[0][i]) * dsigmoid(y_pre[0][i])
for i in range(n_num):
for k in range(total_y):
dtheta_2[0][i] = dtheta_2[0][i] + (y[0][k] - y_out[0][k]) * dsigmoid(y_pre[0][k]) * \\
gamma[i][k] * dReLU(n[0][i])
for i in range(m_num):
for j in range(total_y):
for k in range(n_num):
dtheta_1[0][i] = dtheta_1[0][i] + (y[0][j] - y_out[0][j]) * dsigmoid(y_pre[0][j]) * \\
gamma[k][j] * dReLU(n[0][k]) * v[i][k] * dReLU(m[0][i])
for i in range(n_num):
for j in range(total_y):
dgamma[i][j] = dgamma[i][j] + (y_out[0][j] - y[0][j]) * n_out[0][i] * dsigmoid(y_pre[0][j])
for i in range(m_num):
for j in range(n_num):
for k in range(total_y):
dv[i][j] = dv[i][j] + (y_out[0][k] - y[0][k]) * gamma[j][k] * dsigmoid(y_pre[0][k]) * \\
m_out[0][i] * dReLU(n[0][j])
for i in range(total_x):
for j in range(m_num):
for k in range(total_y):
for l in range(n_num):
dw[i][j] = dw[i][j] + (y_out[0][k] - y[0][k]) * dsigmoid(y_pre[0][k]) * gamma[l][k] * \\
dReLU(n[0][l]) * v[j][l] * dReLU(m[0][j]) * x[i]
return dw, dv, dgamma, theta_1, theta_2, theta_3
# print(type(theta_1))
if __name__ == '__main__':
print("BPnet")
time1 = time.time()
start_train_idx = 5000
# take os time as random seed
random.seed(datetime.datetime.now())
image, label = readFile()
train_img = getImages(image, train_aside_n, start_train_idx)
train_lab = getLabels(label, train_aside_n, start_train_idx) # set aside deal
image_verify, label_verify = readFile(1)
verify_img = getImages(image_verify, verify_n)
verify_lab = getLabels(label_verify, verify_n) # set verify deal
all_img = np.zeros(((train_aside_n, total_x)), dtype=float)
for i in range(train_aside_n):
all_img[i, :] = normalization((train_img[i].flatten()).astype(float))
# we can change train data numbers here
train_n = train_aside_n
# showImgLabel(train_aside_n,train_img,train_lab)
#we get the data but can not use directly,we get tuple,but we use array
w = np.loadtxt("w.csv", delimiter=",")
v = np.loadtxt("v.csv", delimiter=",")
gamma = np.loadtxt("gamma.csv", delimiter=",")
theta_1 = np.loadtxt("theta_1.csv", delimiter=",")
theta_2 = np.loadtxt("theta_2.csv", delimiter=",")
theta_3 = np.loadtxt("theta_3.csv", delimiter=",")
dw = np.zeros(((total_x, m_num)), dtype=float) # (()) is used to confirm line and row
dv = np.zeros((m_num, n_num), dtype=float)
dgamma = np.zeros((n_num, total_y), dtype=float)
dtheta_1 = np.zeros(((1, m_num)), dtype=float)
dtheta_2 = np.zeros(((1, n_num)), dtype=float)
dtheta_3 = np.zeros(((1, total_y)), dtype=float)
#gradient
m = np.ones(((1, m_num)), dtype=float)
m_out = np.ones(((1, m_num)), dtype=float)
n = np.ones(((1, n_num)), dtype=float)
n_out = np.ones(((1, n_num)), dtype=float)
y = np.ones((1, total_y), dtype=float) # read mark
y_out = np.ones((1, total_y), dtype=float)
y_pre = np.ones((1, total_y), dtype=float)
#make the data dimension same
w = w - (study_step * dw) / division
v = v - (study_step * dv) / division
gamma = gamma - (study_step * dgamma) / division
theta_1 = theta_1 - (study_step * dtheta_1) / division
theta_2 = theta_2 - (study_step * dtheta_2) / division
theta_3 = theta_3 - (study_step * dtheta_3) / division
det_Ek_v = np.zeros(epoch, dtype=float)
Ek_cnt = 0
for i in range(0, epoch):
det_Ek_v[Ek_cnt] = np.mean(np.square(y_out - y)) * 0.5
Ek_cnt = Ek_cnt + 1
print("epoch: %d,cost: %.2fs" % (i, time.time() - time1))
VerifyModel(verify_img, verify_lab)
time1 = time.time()
for k in range(0, train_n):
x = all_img[k]
y = np.zeros((1, total_y), dtype=float) # read mark
y[0][train_lab[k]] = 1
# update values
m = np.dot(x, w) - theta_1
for i in range(0, m_num):
m_out[0][i] = ReLU(m[0]