惊!brat安装后进行标注-实战,并且通过一行代码自动标注为BIO格式,便于模型训练-and 错误解决
Posted Coding With you.....
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了惊!brat安装后进行标注-实战,并且通过一行代码自动标注为BIO格式,便于模型训练-and 错误解决相关的知识,希望对你有一定的参考价值。
安装可查看文章:https://blog.csdn.net/weixin_42565135/article/details/119460805
安装后可以继续看下文哦
目录
输入实体识别模型中可以直接训练,不同模型的输入可能不相同,稍微修改数据样式即可
为什么选择brat标注工具。在刚开始进行标注时,是选择的stanford npl工具进行标注的,那个对英文的数据集标注效果是不错的,但进行尝试后发现,比如人工智能这个词,会将人工标注为形容词 智能标注为实体,而且在进行实体识别模型训练的时候,大多数模型需要对标签进行处理,采用的是BIO的标注方式:
- B,即Begin,表示开始
- I,即Intermediate,表示中间
- O,即Other,表示其他,用于标记无关字符
而且在一些知识图谱构建的比赛中也是提到了使用brat进行标注,这样参考的资料也多一些
流程
1.首先是数据集的处理
因为是爬取的英文论文中数据,属于非结构化数据,在实验中计划先取2000条数据进行标注。这2000条数据在一个csv文件中,因此要对数据进行清理,并将每一篇摘要保存到一个txt文件中,每一行为一句话。
import csv
with open('/home/jtt/ai-ner/2021-scopus.csv') as f:
csv_write = csv.reader(f)
for i, row in enumerate(csv_write):
if i == 10:
break
else:
name_='/home/jtt/ai-ner/2021-'+str(i+1)+'.txt'
ff = open(name_, 'a')
# resul=row[1].split('.')
# print(len(resul))
list_ret = list()
for s_str in row[1].split('.'): # 对输入进行处理 (用英文结尾句号.来划分句子)
s_str = s_str.replace('\\n', '') # 去掉句子中的\\n换行
if '?' in s_str:
list_ret.extend(s_str.split('?'))
elif '!' in s_str:
list_ret.extend(s_str.split('!'))
else:
list_ret.append(s_str)
for xx,xc in enumerate(list_ret):
#print(xc.strip(),'\\n')
if xc.strip()!='':
tmp=xc.strip()+'.\\n'
ff.write(tmp)
ff.close()
print('okokokoo')
2.将要标注的数据导入
下面有坑【解决方法是将新建文件家ainer移动到/var/www/html/brat/data下面在标注的时候才能找到,要不咋也找不到文件,即导入的数据得放在/var/www/html/brat/data下】:在主目录/var/www/html/brat下新建文件夹ainer[命令:mkdir ainer],将主目录下的annotation.conf和visual.conf两个文件复制到新建文件夹ainer中【命令:cp annotation.conf /var/www/html/brat/ainer/annotation.conf和cp visual.conf /var/www/html/brat/ainer/visual.conf】;
jtt@jtt-System-Product-Name:/var/www/html/brat$ cd ainer
jtt@jtt-System-Product-Name:/var/www/html/brat/ainer$ ls
annotation.conf visual.conf
jtt@jtt-System-Product-Name:/var/www/html/brat/ainer$ mkdir data
jtt@jtt-System-Product-Name:~/ai-ner$ mv all-txt /var/www/html/brat/ainer/data/
jtt@jtt-System-Product-Name:~$ cd /var/www/html/brat/ainer/data/
jtt@jtt-System-Product-Name:/var/www/html/brat/ainer/data$ ls
all-txt
find 文件夹名称 -name '*.txt'|sed -e 's|\\.txt|.ann|g'|xargs touch,其意思是对每个txt文件都创建一个空的标引文件.ann,因为BRAT是要求的collection中,每个txt文件是必须有一个对应的.ann文件的,方便放置标引内容,这个ann文件的格式也挺规范。
jtt@jtt-System-Product-Name:/var/www/html/brat/ainer/data$ find all-txt -name '*.txt'|sed -e 's|\\.txt|.ann|g'|xargs touch
jtt@jtt-System-Product-Name:/var/www/html/brat/ainer/data$ ls
all-txt
jtt@jtt-System-Product-Name:/var/www/html/brat/ainer/data$ cd all-txt
jtt@jtt-System-Product-Name:/var/www/html/brat/ainer/data/all-txt$ ls
2021-10.ann 2021-2.ann 2021-4.ann 2021-6.ann 2021-8.ann
2021-10.txt 2021-2.txt 2021-4.txt 2021-6.txt 2021-8.txt
2021-1.ann 2021-3.ann 2021-5.ann 2021-7.ann 2021-9.ann
2021-1.txt 2021-3.txt 2021-5.txt 2021-7.txt 2021-9.txt
3.标注
在自己要标注的数据目录添加配置文件annotation.conf,编辑标引规范,就是写明白自己标注的都有哪些命名实体、哪些语义关系。eg:
[entities]
OTH
LOC
NAME
ORG
TIME
TIL
NUM
[relations]
[events]
[attributes]
jtt@jtt-System-Product-Name:~$ cd /var/www/html/brat/ainer
jtt@jtt-System-Product-Name:/var/www/html/brat/ainer$ ls
annotation.conf data visual.conf
jtt@jtt-System-Product-Name:/var/www/html/brat/ainer$ vi annotation.conf
点击键盘 i 进行实体类别编辑,如下修改
Method-tech
Area-subject
Time
Other
关系
Applyied Arg1:Method-tech,Arg2:Area-subject
Associate Arg1:Method-tech,Arg2:Method-tech
Associate2 Arg1:Area-subject,Arg2:Area-subject
Emergence Arg1:Method-tech,Arg2:Time
Located Arg1:Other, Arg2:Other
Geographical_part Arg1:Other, Arg2:Other
Family Arg1:Person, Arg2:Other
Employment Arg1:Other, Arg2:Other
Ownership Arg1:Other, Arg2:Other
属性
Merge-time Arg:<RELATION>
点击esc退出编辑
光标到最后输入:wq即可返回命令界面
点击BRAT页面,用自己的账号登录,从页面上直接进入collection中,找到文件进行标引。
命名实体标引直接用光标拖拽,关系标引用鼠标将一个实体指向另一个实体即可。
jtt@jtt-System-Product-Name:~$ cd /var/www/html/brat
jtt@jtt-System-Product-Name:/var/www/html/brat$ python2 standalone.py
Serving brat at http://127.0.0.1:8001
现在遇到一个问题:找不到要标注的数据在哪里,然后通过代码测试 总算找到了。之后将配置文件和数据移动到了正确位置中。【这就是坑-跳出来了】总结:在data中新建一个文件夹/var/www/html/brat/data/all-txt,里面包含文本/.ann/以及配置文件annotation.conf 和 visual.conf
jtt@jtt-System-Product-Name:/var/www/html/brat$ cd data
jtt@jtt-System-Product-Name:/var/www/html/brat/data$ ls
6.ann 6.txt examples tutorials
移动:jtt@jtt-System-Product-Name:/var/www/html/brat/ainer/data$ mv all-txt /var/www/html/brat/data/
jtt@jtt-System-Product-Name:/var/www/html/brat$ cd data
jtt@jtt-System-Product-Name:/var/www/html/brat/data$ ls
6.ann 6.txt all-txt examples tutorials
jtt@jtt-System-Product-Name:/var/www/html/brat/data$ rm 6.ann
jtt@jtt-System-Product-Name:/var/www/html/brat/data$ rm 6.txt
jtt@jtt-System-Product-Name:/var/www/html/brat/data$ ls
all-txt examples tutorials
ok了
接下来将配置文件重新修改一下
jtt@jtt-System-Product-Name:/var/www/html/brat$ vi annotation.conf
修改完成后进行标注可以看到图中有了数据了
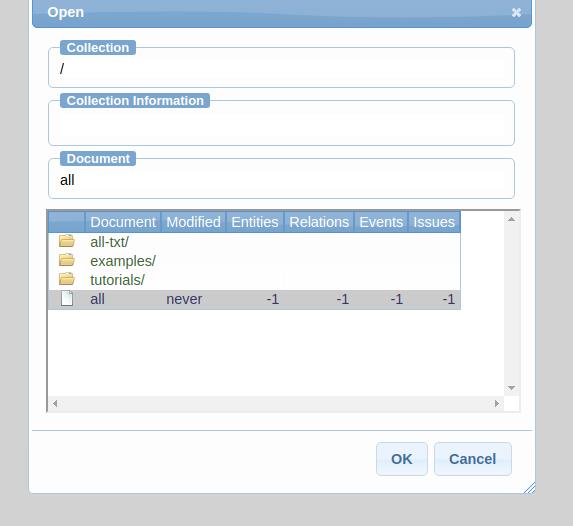
三.实战标注过程
选择要标注的实体,直接弹出框框进行标注,最后可以将标注好的数据导出
四.模型
根据标注的结果转化成BIO标注,选择bert-bilstm-crf模型进行标注。
怎么标注呢
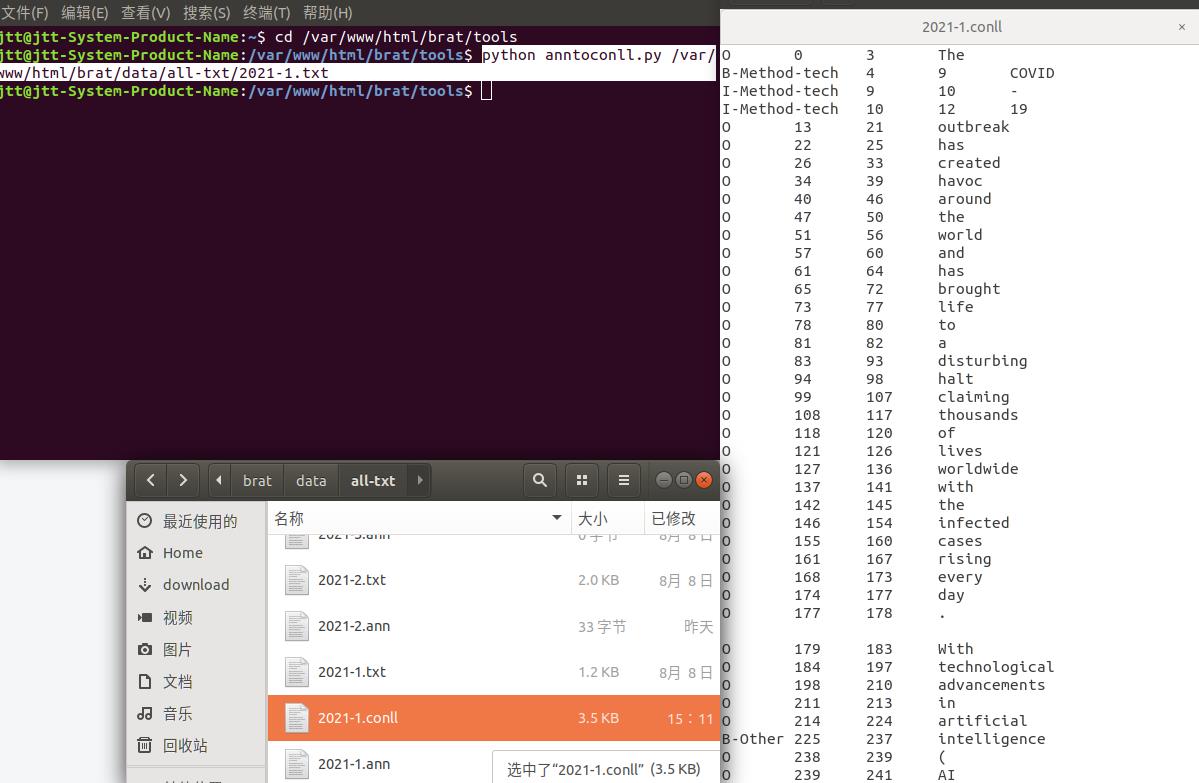
1.自动标注的流程及结果展示
进入目录/var/www/html/brat/tools;
输入:python anntoconll.py 要进行BIO标注的文本文件
ok
eg:
ann文件标注了两个实体:T1 Method-tech 4 12 COVID-19
T2 Other 225 237 intelligence
运行代码:python anntoconll.py /var/www/html/brat/data/all-txt/2021-1.txt
生成了标注后的文件:文件名.conll
结果:
2.写代码标注:也很简单,这里说说思路
根据标注的.ann文件,找到是实体的标注
第一个识别的标为B,判断如果他后面的词还是实体,就给标注为I
当不是实体的其他标为O
3.模型训练
输入实体识别模型中可以直接训练,不同模型的输入可能不相同,稍微修改数据样式即可
错误解决
正常的配置文件,在实体标注时可以,在bio标注时报错。同样在bio标注时正确,在实体识别时报错,究其原因及解决办法--如下
原因:
py文件中代码报错
解决办法:
在brat/server/src/sspostproc.py文件中,实体标注时代码:
jtt@jtt-System-Product-Name:~$ cd /var/www/html/brat
jtt@jtt-System-Product-Name:/var/www/html/brat$ python2 standalone.py
Serving brat at http://127.0.0.1:8001
文件内容为
#!/usr/bin/env python
# Python version of geniass-postproc.pl. Originally developed as a
# heuristic postprocessor for the geniass sentence splitter, drawing
# in part on Yoshimasa Tsuruoka's medss.pl.
from __future__ import with_statement
import re
INPUT_ENCODING = "UTF-8"
OUTPUT_ENCODING = "UTF-8"
DEBUG_SS_POSTPROCESSING = False
__initial = []
# TODO: some cases that heuristics could be improved on
# - no split inside matched quotes
# - "quoted." New sentence
# - 1 mg .\\nkg(-1) .
# breaks sometimes missing after "?", "safe" cases
__initial.append((re.compile(r'\\b([a-z]+\\?) ([A-Z][a-z]+)\\b'), r'\\1\\n\\2'))
# breaks sometimes missing after "." separated with extra space, "safe" cases
__initial.append((re.compile(r'\\b([a-z]+ \\.) ([A-Z][a-z]+)\\b'), r'\\1\\n\\2'))
# join breaks creating lines that only contain sentence-ending punctuation
__initial.append((re.compile(r'\\n([.!?]+)\\n'), r' \\1\\n'))
# no breaks inside parens/brackets. (To protect against cases where a
# pair of locally mismatched parentheses in different parts of a large
# document happen to match, limit size of intervening context. As this
# is not an issue in cases where there are no interveining brackets,
# allow an unlimited length match in those cases.)
__repeated = []
# unlimited length for no intevening parens/brackets
__repeated.append((re.compile(r'(\\([^\\[\\]\\(\\)]*)\\n([^\\[\\]\\(\\)]*\\))'),r'\\1 \\2'))
__repeated.append((re.compile(r'(\\[[^\\[\\]\\(\\)]*)\\n([^\\[\\]\\(\\)]*\\])'),r'\\1 \\2'))
# standard mismatched with possible intervening
__repeated.append((re.compile(r'(\\([^\\(\\)]{0,250})\\n([^\\(\\)]{0,250}\\))'), r'\\1 \\2'))
__repeated.append((re.compile(r'(\\[[^\\[\\]]{0,250})\\n([^\\[\\]]{0,250}\\])'), r'\\1 \\2'))
# nesting to depth one
__repeated.append((re.compile(r'(\\((?:[^\\(\\)]|\\([^\\(\\)]*\\)){0,250})\\n((?:[^\\(\\)]|\\([^\\(\\)]*\\)){0,250}\\))'), r'\\1 \\2'))
__repeated.append((re.compile(r'(\\[(?:[^\\[\\]]|\\[[^\\[\\]]*\\]){0,250})\\n((?:[^\\[\\]]|\\[[^\\[\\]]*\\]){0,250}\\])'), r'\\1 \\2'))
__final = []
# no break after periods followed by a non-uppercase "normal word"
# (i.e. token with only lowercase alpha and dashes, with a minimum
# length of initial lowercase alpha).
__final.append((re.compile(r'\\.\\n([a-z]{3}[a-z-]{0,}[ \\.\\:\\,\\;])'), r'. \\1'))
# no break in likely species names with abbreviated genus (e.g.
# "S. cerevisiae"). Differs from above in being more liberal about
# separation from following text.
__final.append((re.compile(r'\\b([A-Z]\\.)\\n([a-z]{3,})\\b'), r'\\1 \\2'))
# no break in likely person names with abbreviated middle name
# (e.g. "Anton P. Chekhov", "A. P. Chekhov"). Note: Won't do
# "A. Chekhov" as it yields too many false positives.
__final.append((re.compile(r'\\b((?:[A-Z]\\.|[A-Z][a-z]{3,}) [A-Z]\\.)\\n([A-Z][a-z]{3,})\\b'), r'\\1 \\2'))
# no break before CC ..
__final.append((re.compile(r'\\n((?:and|or|but|nor|yet) )'), r' \\1'))
# or IN. (this is nothing like a "complete" list...)
__final.append((re.compile(r'\\n((?:of|in|by|as|on|at|to|via|for|with|that|than|from|into|upon|after|while|during|within|through|between|whereas|whether) )'), r' \\1'))
# no sentence breaks in the middle of specific abbreviations
__final.append((re.compile(r'\\b(e\\.)\\n(g\\.)'), r'\\1 \\2'))
__final.append((re.compile(r'\\b(i\\.)\\n(e\\.)'), r'\\1 \\2'))
__final.append((re.compile(r'\\b(i\\.)\\n(v\\.)'), r'\\1 \\2'))
# no sentence break after specific abbreviations
__final.append((re.compile(r'\\b(e\\. ?g\\.|i\\. ?e\\.|i\\. ?v\\.|vs\\.|cf\\.|Dr\\.|Mr\\.|Ms\\.|Mrs\\.)\\n'), r'\\1 '))
# or others taking a number after the abbrev
__final.append((re.compile(r'\\b([Aa]pprox\\.|[Nn]o\\.|[Ff]igs?\\.)\\n(\\d+)'), r'\\1 \\2'))
# no break before comma (e.g. Smith, A., Black, B., ...)
__final.append((re.compile(r'(\\.\\s*)\\n(\\s*,)'), r'\\1 \\2'))
def refine_split(s):
"""
Given a string with sentence splits as newlines, attempts to
heuristically improve the splitting. Heuristics tuned for geniass
sentence splitting errors.
"""
if DEBUG_SS_POSTPROCESSING:
orig = s
for r, t in __initial:
s = r.sub(t, s)
for r, t in __repeated:
while True:
n = r.sub(t, s)
if n == s: break
s = n
for r, t in __final:
s = r.sub(t, s)
# Only do final comparison in debug mode.
if DEBUG_SS_POSTPROCESSING:
# revised must match original when differences in space<->newline
# substitutions are ignored
r1 = orig.replace('\\n', ' ')
r2 = s.replace('\\n', ' ')
if r1 != r2:
print >> sys.stderr, "refine_split(): error: text mismatch (returning original):\\nORIG: '%s'\\nNEW: '%s'" % (orig, s)
s = orig
return s
if __name__ == "__main__":
import sys
import codecs
# for testing, read stdin if no args
if len(sys.argv) == 1:
sys.argv.append('/dev/stdin')
for fn in sys.argv[1:]:
try:
with codecs.open(fn, encoding=INPUT_ENCODING) as f:
s = "".join(f.read())
sys.stdout.write(refine_split(s).encode(OUTPUT_ENCODING))
except Exception, e:
print >> sys.stderr, "Failed to read", fn, ":", e
BIO标注时代码:
jtt@jtt-System-Product-Name:~$ cd /var/www/html/brat/tools
jtt@jtt-System-Product-Name:/var/www/html/brat/tools$ python anntoconll.py /var/www/html/brat/data/2021-pre2000/2021-1.txt
内容为
#!/usr/bin/env python
# Python version of geniass-postproc.pl. Originally developed as a
# heuristic postprocessor for the geniass sentence splitter, drawing
# in part on Yoshimasa Tsuruoka's medss.pl.
import re
INPUT_ENCODING = "UTF-8"
OUTPUT_ENCODING = "UTF-8"
DEBUG_SS_POSTPROCESSING = False
__initial = []
# TODO: some cases that heuristics could be improved on
# - no split inside matched quotes
# - "quoted." New sentence
# - 1 mg .\\nkg(-1) .
# breaks sometimes missing after "?", "safe" cases
__initial.append((re.compile(r'\\b([a-z]+\\?) ([A-Z][a-z]+)\\b'), r'\\1\\n\\2'))
# breaks sometimes missing after "." separated with extra space, "safe" cases
__initial.append((re.compile(r'\\b([a-z]+ \\.) ([A-Z][a-z]+)\\b'), r'\\1\\n\\2'))
# join breaks creating lines that only contain sentence-ending punctuation
__initial.append((re.compile(r'\\n([.!?]+)\\n'), r' \\1\\n'))
# no breaks inside parens/brackets. (To protect against cases where a
# pair of locally mismatched parentheses in different parts of a large
# document happen to match, limit size of intervening context. As this
# is not an issue in cases where there are no interveining brackets,
# allow an unlimited length match in those cases.)
__repeated = []
# unlimited length for no intevening parens/brackets
__repeated.append(
(re.compile(r'(\\([^\\[\\]\\(\\)]*)\\n([^\\[\\]\\(\\)]*\\))'), r'\\1 \\2'))
__repeated.append(
(re.compile(r'(\\[[^\\[\\]\\(\\)]*)\\n([^\\[\\]\\(\\)]*\\])'), r'\\1 \\2'))
# standard mismatched with possible intervening
__repeated.append(
(re.compile(r'(\\([^\\(\\)]{0,250})\\n([^\\(\\)]{0,250}\\))'), r'\\1 \\2'))
__repeated.append(
(re.compile(r'(\\[[^\\[\\]]{0,250})\\n([^\\[\\]]{0,250}\\])'), r'\\1 \\2'))
# nesting to depth one
__repeated.append(
(re.compile(r'(\\((?:[^\\(\\)]|\\([^\\(\\)]*\\)){0,250})\\n((?:[^\\(\\)]|\\([^\\(\\)]*\\)){0,250}\\))'),
r'\\1 \\2'))
__repeated.append(
(re.compile(r'(\\[(?:[^\\[\\]]|\\[[^\\[\\]]*\\]){0,250})\\n((?:[^\\[\\]]|\\[[^\\[\\]]*\\]){0,250}\\])'),
r'\\1 \\2'))
__final = []
# no break after periods followed by a non-uppercase "normal word"
# (i.e. token with only lowercase alpha and dashes, with a minimum
# length of initial lowercase alpha).
__final.append((re.compile(r'\\.\\n([a-z]{3}[a-z-]{0,}[ \\.\\:\\,\\;])'), r'. \\1'))
# no break in likely species names with abbreviated genus (e.g.
# "S. cerevisiae"). Differs from above in being more liberal about
# separation from following text.
__final.append((re.compile(r'\\b([A-Z]\\.)\\n([a-z]{3,})\\b'), r'\\1 \\2'))
# no break in likely person names with abbreviated middle name
# (e.g. "Anton P. Chekhov", "A. P. Chekhov"). Note: Won't do
# "A. Chekhov" as it yields too many false positives.
__final.append(
(re.compile(r'\\b((?:[A-Z]\\.|[A-Z][a-z]{3,}) [A-Z]\\.)\\n([A-Z][a-z]{3,})\\b'),
r'\\1 \\2'))
# no break before CC ..
__final.append((re.compile(r'\\n((?:and|or|but|nor|yet) )'), r' \\1'))
# or IN. (this is nothing like a "complete" list...)
__final.append((re.compile(
r'\\n((?:of|in|by|as|on|at|to|via|for|with|that|than|from|into|upon|after|while|during|within|through|between|whereas|whether) )'), r' \\1'))
# no sentence breaks in the middle of specific abbreviations
__final.append((re.compile(r'\\b(e\\.)\\n(g\\.)'), r'\\1 \\2'))
__final.append((re.compile(r'\\b(i\\.)\\n(e\\.)'), r'\\1 \\2'))
__final.append((re.compile(r'\\b(i\\.)\\n(v\\.)'), r'\\1 \\2'))
# no sentence break after specific abbreviations
__final.append(
(re.compile(r'\\b(e\\. ?g\\.|i\\. ?e\\.|i\\. ?v\\.|vs\\.|cf\\.|Dr\\.|Mr\\.|Ms\\.|Mrs\\.)\\n'),
r'\\1 '))
# or others taking a number after the abbrev
__final.append(
(re.compile(r'\\b([Aa]pprox\\.|[Nn]o\\.|[Ff]igs?\\.)\\n(\\d+)'), r'\\1 \\2'))
# no break before comma (e.g. Smith, A., Black, B., ...)
__final.append((re.compile(r'(\\.\\s*)\\n(\\s*,)'), r'\\1 \\2'))
def refine_split(s):
"""Given a string with sentence splits as newlines, attempts to
heuristically improve the splitting.
Heuristics tuned for geniass sentence splitting errors.
"""
if DEBUG_SS_POSTPROCESSING:
orig = s
for r, t in __initial:
s = r.sub(t, s)
for r, t in __repeated:
while True:
n = r.sub(t, s)
if n == s:
break
s = n
for r, t in __final:
s = r.sub(t, s)
# Only do final comparison in debug mode.
if DEBUG_SS_POSTPROCESSING:
# revised must match original when differences in space<->newline
# substitutions are ignored
r1 = orig.replace('\\n', ' ')
r2 = s.replace('\\n', ' ')
if r1 != r2:
print("refine_split(): error: text mismatch (returning original):\\nORIG: '%s'\\nNEW: '%s'" % (orig, s), file=sys.stderr)
s = orig
return s
if __name__ == "__main__":
import sys
import codecs
# for testing, read stdin if no args
if len(sys.argv) == 1:
sys.argv.append('/dev/stdin')
for fn in sys.argv[1:]:
try:
with codecs.open(fn, encoding=INPUT_ENCODING) as f:
s = "".join(f.read())
sys.stdout.write(refine_split(s).encode(OUTPUT_ENCODING))
except Exception as e:
print("Failed to read", fn, ":", e, file=sys.stderr)
以上是关于惊!brat安装后进行标注-实战,并且通过一行代码自动标注为BIO格式,便于模型训练-and 错误解决的主要内容,如果未能解决你的问题,请参考以下文章
brat进行英文数据集的标注-实战(标注后编写成BIO格式便于模型训练)
安装brat附安装包进行实体标注过程中出现的问题及解决-超级全