深度学习与图神经网络核心技术实践应用高级研修班-Day1小样本学习与元学习
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习与图神经网络核心技术实践应用高级研修班-Day1小样本学习与元学习相关的知识,希望对你有一定的参考价值。
深度学习的常用模型及方法-小样本学习与元学习


1. 小样本学习
Few-shot 的训练集中包含很多类别,每个类别中有多个样本。
- 在训练阶段,在训练集中随机抽取 C 个类别,每个类别 K 个样本(总共 CK 个数据),构建一个 meta-task,作为模型的支撑集(support set)输入;
- 再从这 C 个类中剩余的数据中抽取一批(batch)样本作为模型的预测对象(batch set)。
即要求模型从 C*K 个数据中学会如何区分这 C 个类别—— C-way K-shot 问题。
1.1 2-way 5-shot 示例
- meta training 阶段:构建了一系列 meta-task 来让模型学习如何根据support set 预测 batch set 中的样本的标签;
- meta testing 阶段:输入数据的形式与训练阶段一致(2-way 5-shot),但是会在全新的类别上构建 support set 和 batch。

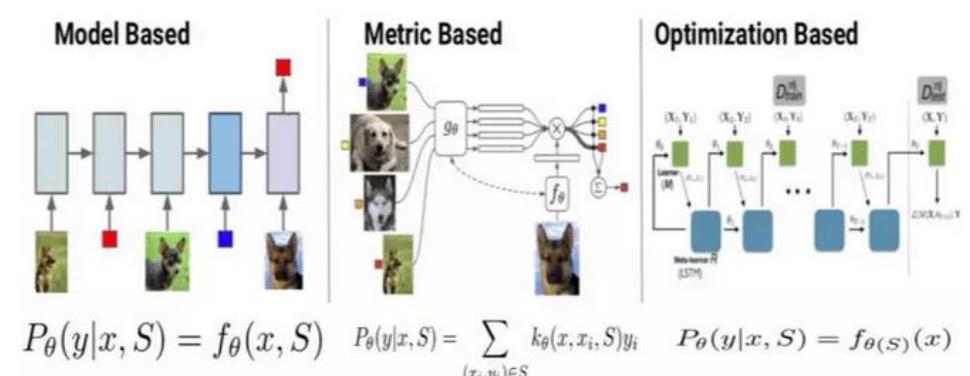
Few-shot Learning 模型大致可分为三类:
- 基于模型的方法 (Model Based)
Model Based 方法旨在通过模型结构的设计快速在
少量样本上更新参数,直接建立输入 x 和预测值 P
的映射函数; - 基于度量的方法 (Metric Based)
Metric Based方法通过度量 batch 集的样本和support 集样本的距离,借助最近邻思想完成分类; - 基于优化的方法 (Optimization Based)
Optimization Based 方法认为普通的梯度下降方法
难以在 few-shot 场景下拟合,因此通过调整优化方法来完成小样本分类的任务。
1.2 基于模型的方法
使用记忆增强的方法来解决 Few-shot Learning 任务[Santoro et al. 2016]
基于神经网络图灵机(NTMs)的思想,因为 NTMs 能通过外部存储(external memory)进行短时记忆,并能通过缓慢权值更新来进行长时记忆,NTMs可以学习将表达存入记忆的策略,并用这些表达来进行预测。
方法可以快速准确地预测那些只出现过一次的数据。
方法基于LSTM等RNN模型,将数据看成序列来训练,在测试时输入新类的样本进行分类
具体地,在 t 时刻,模型输入(xt,yt-1) 也就是在当前时刻预测输入样本的类别,在下一时刻给出真实的 label,并且添加 external memory 存储上一次的 x 输入,这使得下一次输入后进行反向传播时,可以让 y (label) 和 x 建立联系,使得之后的 x 能够通过外部记忆获取相关图像进行比对来实现更好的预测。

在 Few-shot Learning 任务中去训练普通的基于 cross-entropy 的神经网络分类器——>过拟合,因为神经网络分类器中有数以万计的参数需要优化。
很多非参数化的方法(最近邻、K-近邻、K-means)不需要优化参数,因此可以在 meta-learning 的框架下构造一种可以端到端训练的 few-shot 分类器。该方法是对样本间距离分布进行建模,使得同类样本靠近,异类样本远离。
1.3 基于度量的方法
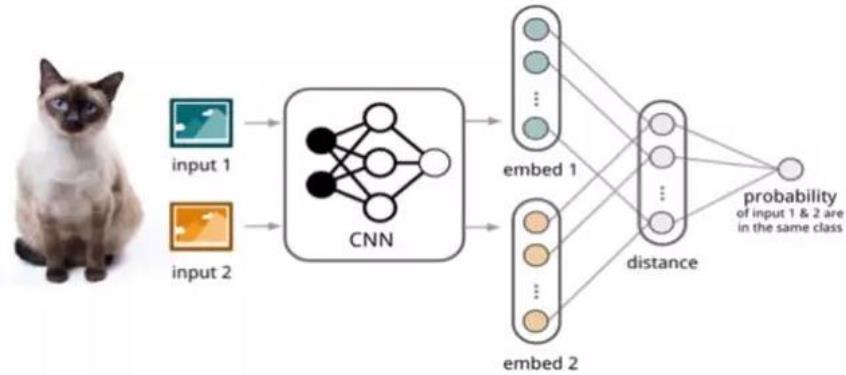
孪生网络(Siamese Network)[Koch et al. 2015]:通过有监督的方式训练孪生网络,重用网络所提取的特征进行one/few-shot 学习。
- 双路的神经网络
- 训练时,通过组合的方式构造不同的成对样本,输入网络进行训练,在最上层通过样本对的距离判断他们是否属于同一个类,并产生对应的概率分布。
- 预测阶段,孪生网络处理测试样本和支撑集之间每一个样本对,最终预测结果为支撑集上概率最高的类别。
-
匹配网络(Match Network)[Oriol Vinyals et al. 2016]:为支撑集和Batch 集构建不同的编码器,最终分类器的输出是支撑集样本和 query 之间预测值的加权求和。
-
在不改变网络模型的前提下能对未知类别生成标签
-
主要创新体现在建模过程和训练过程上。对于建模过程的创新,提出了基于memory 和 attention 的 matching nets,使得可以快速学习。

训练过程的创新:
方法基于传统机器学习的一个原则,即训练和测试是要在同样条件下进行的,提出在训练的时候不断地让网络只看每一类的少量样本,这和测试的过程一致。

它通过如下两个方面来解决:
1)基于双向 LSTM 学习训练集的 embedding,使得每个支撑样本的 embedding 是其它训练样本的函数;
2)基于 attention-LSTM 来对测试样本 embedding,使得每个 Query 样本的embedding 是支撑集 embedding 的函数。文章称其为 FCE (fully-conditional embedding)。
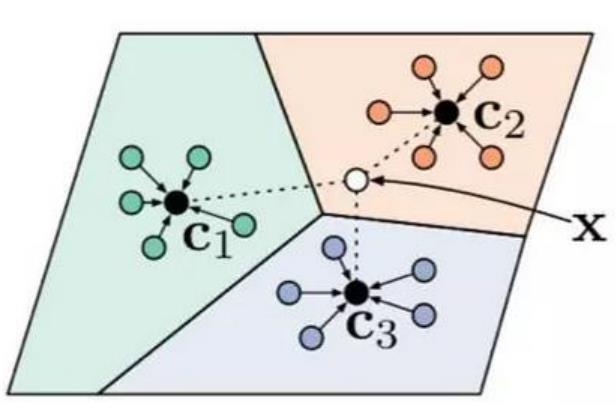
原型网络(Prototype Network)[Snell et al. 2017]:每个类别都存在一个原型表达,该类的原型是 support set 在 embedding 空间中的均值。分类问题变成在 embedding 空间中的最近邻。
c1、c2、c3 分别是三个类别的均值中心(称 Prototype),将测试样本 x 进行embedding 后,与这 3 个中心进行距离计算,从而获得 x 的类别。
Relation Network [ Sung et al. 2018]:度量方式也是网络中非常重要的一环,需要对其进行建模,所以该网络不满足单一且固定的距离度量方式,
而是训练一个网络来学习(例 如 CNN)距离的度量方式,在loss 方面也有所改变,考虑到relation network 更多的关注relation score,更像一种回归,而非 0/1 分类,所以使用了 MSE 取代了 cross-entropy。
Relation Network
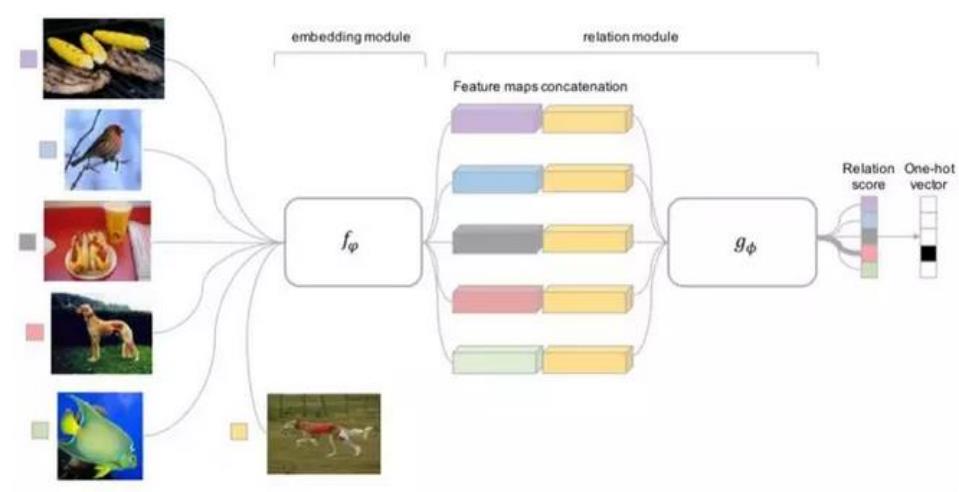
1.4 基于优化的方法
在少量数据下,基于梯度的优化算法失败的原因:无法直接用于 meta learning。
- 这些梯度优化算法包括 momentum, adagrad, adadelta, ADAM 等,无法在几步内完成优化,特别是在非凸的问题上,多种超参的选取无法保证收敛的速度。
- 其次,不同任务分别随机初始化会影响任务收敛到好的解上。虽然 finetune 这种迁移学习能缓解这个问题,但当新数据相对原始数据偏差比较大时,迁移学习的性能会大大下降。应该一个系统的学习通用初始化,使得训练从一个好的点开始,它和迁移学习不同的是,它能保证该初始化能让 finetune 从一个好的点开始。
基于度量的方法
[Ravi et al. 2016] 学习的是一个模型参数的更新函数或更新规则。它不是在多轮的episodes 学习一个单模型,而是在每个 episode 学习特定的模型。
具体地,学习基于梯度下降的参数更新算法,采用 LSTM 表达 meta learner,用其状态表达目标分类器的参数的更新,最终学会如何在新的分类任务上,对分类器网络(learner)进行初始化和参数更新。这个优化算法同时考虑一个任务的短时知识和跨多个任务的长时知识。
方法的目标为通过少量的迭代步骤捕获优化算法的泛化能力,由此 meta learner可以训练让 learner 在每个任务上收敛到一个好的解。另外,通过捕获所有任务之前共享的基础知识,进而更好地初始化 learner。
基于度量的方法
以miniImage 数据集为例
训练过程:从训练集(64 个类,每类 600 个样本)中随机采样 5 个类,每个类 5个样本,构成支撑集,去学习 learner;从训练集的样本(采出的 5 个类,每类剩下的样本)中采样构成 Batch 集,集合中每类有 15 个样本,用来获得 learner的 loss,去学习 meta leaner。
测试:从测试集(16 个类,每类 600 个样本)中随机采样 5 个类,每个类 5 个样本,构成支撑集 Support Set,去学习 learner;从测试集剩余的样本(采出的5 个类,每类剩下的样本)中采样构成 Batch 集,集合中每类有 15 个样本,用来获得 learner 的参数,进而得到预测的类别概率。这两个过程分别如图中虚线左侧和右侧。
基于度量的方法
meta learner 的目标是在各种不同的学习任务上学出一个模型,使得可以仅用少量的样本就能解决一些新的学习
任务。这种任务的挑战是模型需要结合之前的经验和当前新任务的少量样本信息,并避免在新数据上过拟合。

基于度量的方法
[Finn et al. 2017]:在少量样本上,用少量的迭代步骤可以获得较好的泛化性能,而且模型是容易 fine-tine 的。这个方法无需关心模型的形式,也不需要为 metalearning 增加新的参数,直接用梯度下降来训练 learner。
核心思想是学习模型的初始化参数使得在一步或几步迭代后在新任务上的精度最大化。
方法可以学习任意标准模型的参数,并让该模型能快速适配。中间表达更加适合迁移,比如神经网络的内部特征,因此面向泛化性的表达是有益的。因为会基于梯度下降策略在新的任务上进行 finetune,所以目标是学习这样一个模型,它能对新的任务从之前任务上快速地进行梯度下降,而不会过拟合。事实上,是要找到一些对任务变化敏感的参数,使得当改变梯度方向,小的参数改动也会产生较大的 loss。
1.5 数据集
- FewRel 数据集 [Han et al. 2018]:小样本关系分类数据集,包含64种关系用于训练,16种关系用于验证和20种关系用于测试,每种关系下包含700个样本。
- ARSC 数据集 [Yu et al. 2018]:取自亚马逊多领域情感分类数据,该数据集包含23 种亚马逊商品的评论数据,对于每一种商品,构建三个二分类任务,将其评论按分数分为 5、4、 2 三档,每一档视为一个二分类任务,则产生 23 ∗ 3 23*3 23∗3=69 个 task,然后取其中 12 个 task(4*3)作为测试集,其余 57 个 task 作为训练集。
- ODIC 数据集来自阿里巴巴对话工厂平台的线上日志,用户会向平台提交多种不同的对话任务,和多种不同的意图,但是每种意图只有极少数的标注数据,这形成了一个典型的 Few-shot Learning 任务,该数据集包含 216 个意图,其中 159 个用于训练,57个用于测试。
1.6 基于混合注意力的原型网络
基于混合注意力的原型网络结构[Gao et al. 2019]
- 使用 instance-level 的 attention 从支撑集中选出和 query 更为贴近的实例,同时降低噪声实例所带来的影响。(文本与图像的一大区别在于其多样性和噪音更大)
- feature-level 的实例能够衡量特征空间中的哪些维度对分类更为重要,从而为每种不同的关系都生成相适应的距离度量函数,从而使模型能够有效处理特征稀疏的问题。

基于度量的方法
之前的 Few-shot Learning 方法只需使用一个 meta model 即可解决剩余的 few-shot 任务。现实场景当中,不同的 meta task 可能来自完全不同的领域,因此使用单独的度量方式不足以衡量所有的 meta task。
在这种场景下,[Yu et al. 2018]提出使用多种度量方式融合来解跨领域的 Few-shotLearning 问题。在训练阶段,meta learner 通过任务聚类选择和结合多种度量方式来学习目标任务,不同领域的 meta task 首先通过聚类来划分,因此同一个簇内的task 可以认为是相关的,然后在该簇中训练一个深度神经网络作为度量函数,这种机制保证了只有在同一个簇中的 task 才会共享度量函数。
2. 元学习
2.1 元学习基础知识

- 当前的机器学习模型通常需要训练大量的样本且针对于每个新的任务都需要从头训练
- 人类可以更快且更有效地学习新的概念和技能。比如,只看过几次猫和鸟,儿童可以迅速分辨它们;懂得如何骑自行车的人在很少的示范下可以快速骑摩托车
- 是否可以设计一个具有类似特性的机器学习模型-通过一些培训示例快速学习新概念和技能?
- 这实质上就是元学习旨在解决的问题
2.2 元学习实际应用
- 神经网络和超参数优化
- 网络架构搜索
- 小样本学习
- 快速强化学习

2.3 元学习经典算法

2.4 元学习经典算法 - MAML
- MAML 的思路就是直接针对初始表示进行优化,其中这种初始表示可以通过少量示例进行有效地调整
- MAML 是通过许多 tasks 进行训练,训练所得表征可以通过很少梯度迭代就能适应新任务。MAML 试图寻找这样一种初始化,不仅有效适用不同任务,而且要快速适应(仅需要几步)和有效适应(只使用很少样例)。

-
步骤1:随机初始化模型参数;
-
步骤2:是一个循环,可以理解为一轮迭代过程或一个Epoch,当然,预训练过程也可以有多个 Epoch,相当于设置 Epoch;
-
步骤3:随机对若干个(e.g., 4 个)task 进行采样,形成一个 batch;
-
步骤4 ∼∼ 步骤7:第一次梯度更新过程。注意这里我们可以理解为copy了一个原模型,计算出新的参数,用在第二轮梯度的计算过程中。 MAML是gradient by gradient的,有两次梯度更新的过程。步骤4~7中,利用batch中的每一个task,分别对模型的参数进行更新(4个task即更新4次)。 注意这个过程在算法中是可以反复执行多次的,但是伪代码没有体现这一层循
环 。 -
步骤5: 利用 batch 中的某一个 task 中的 support set(在 N-way K-shot 的设置下,这里的support set 应该有 NK 个),计算每个参数的梯度。 注意: 这里的loss计算方法,在回归问题中,就是MSE;在分类问题中,就是cross-entropy。
-
步骤4 ∼∼ 步骤7: 结束后,MAML完成了第一次梯度更新。接下来要做的,是根据第一次梯度更新得到的参数,通过gradient by gradient,计算第二次梯度更新。第二次梯度更新时计算出的梯度,直接通过SGD作用于原模型上,也就是模型真正用于更新其参数的梯度。
-
步骤8:这里对应第二次梯度更新的过程。这里的loss计算方法,大致与步骤5相同,但是不同点有两处:第一处是不再分别利用每个task的loss更新梯度,而是像常见的模型训练过程一样,计算一个batch的loss总和,对梯度进行随机梯度下降SGD;第一处是这里参与计算的样本,是task中的 query set,在我们的例子中,即5-way*15=75个样本,目的是增强模型在task上的泛化能力,避免过拟合 support set。步骤8结束后,模型结束在该batch中的训练,开始回到步骤3,继续采样下一个batch。
精调过程于预训练过程大致相同,不同之处有以下几点:
- 步骤 1 中,fine-tune 不用再随机初始化参数,而是利用训练好的 𝑀𝑚𝑒𝑡𝑎初始化参数;
- 步骤 3 中,fine-tune只需要抽取一个task进行学习,自然也不用形成batch。fine-tune利用这个task的support set训练模型,利用query set测试模型。 实际操作中,我们会在 𝐷𝑚𝑒𝑡𝑎−𝑡𝑒𝑠𝑡上随机抽取多个 task(e.g., 500 个),分别微调模型 𝑀𝑚𝑒𝑡𝑎,并对最后测试结果进行平均,避免极端情况;
- fine-tune 没有步骤 8, 因为task的query set是用来测试模型的,标签对模型是未知的。因此fine-tune过程没有第二次梯度更新,而是直接利用第一次梯度计算的结果更新参数。


以上是关于深度学习与图神经网络核心技术实践应用高级研修班-Day1小样本学习与元学习的主要内容,如果未能解决你的问题,请参考以下文章