深度学习与图神经网络核心技术实践应用高级研修班-Day1卷积神经网络(CNN详解)
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习与图神经网络核心技术实践应用高级研修班-Day1卷积神经网络(CNN详解)相关的知识,希望对你有一定的参考价值。
卷积神经网络

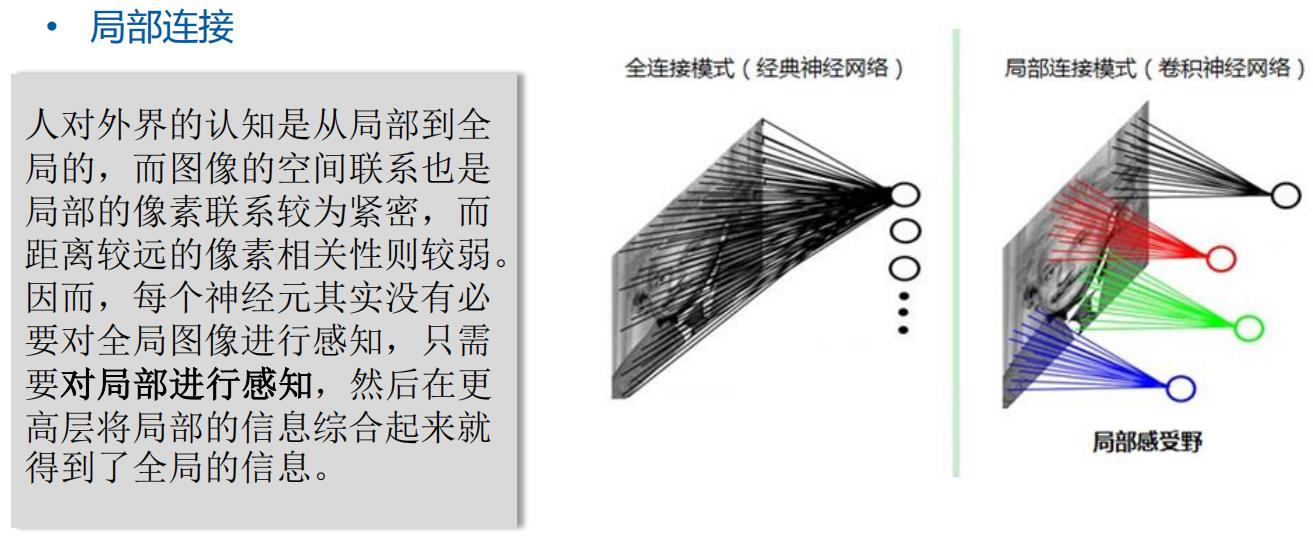
1. 从神经元到多层神经网络


1.1 深度学习方法->反向传播
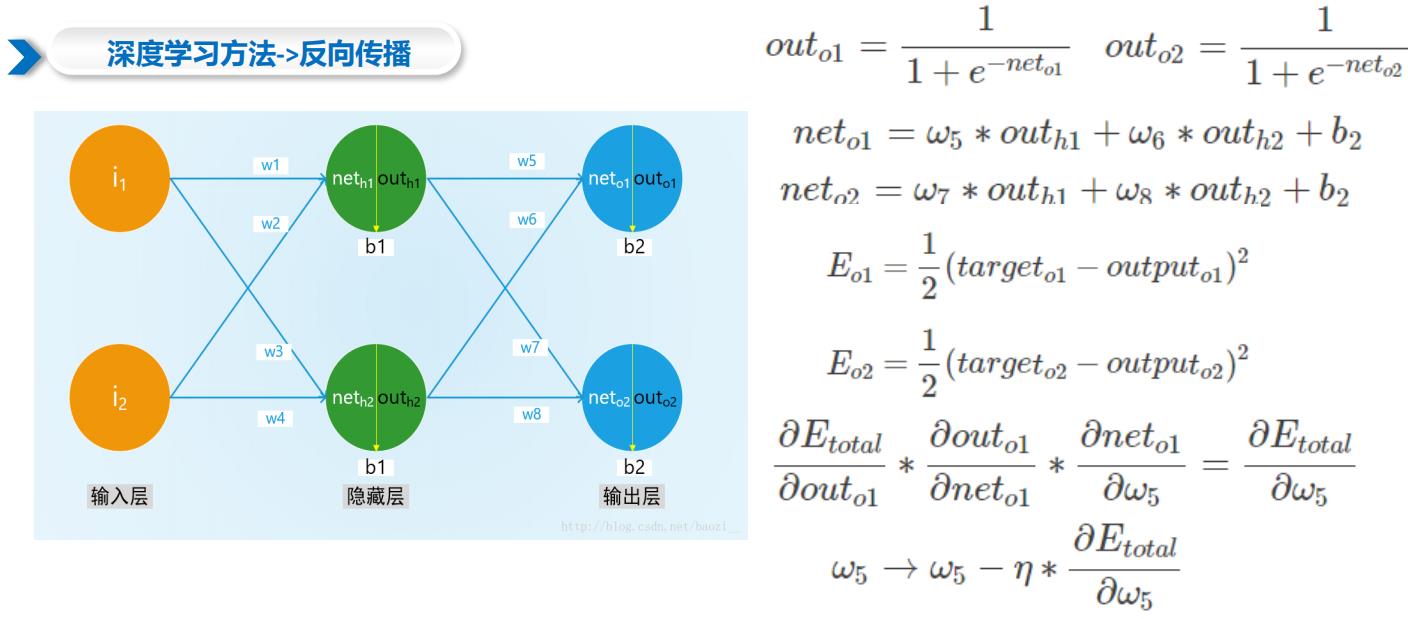
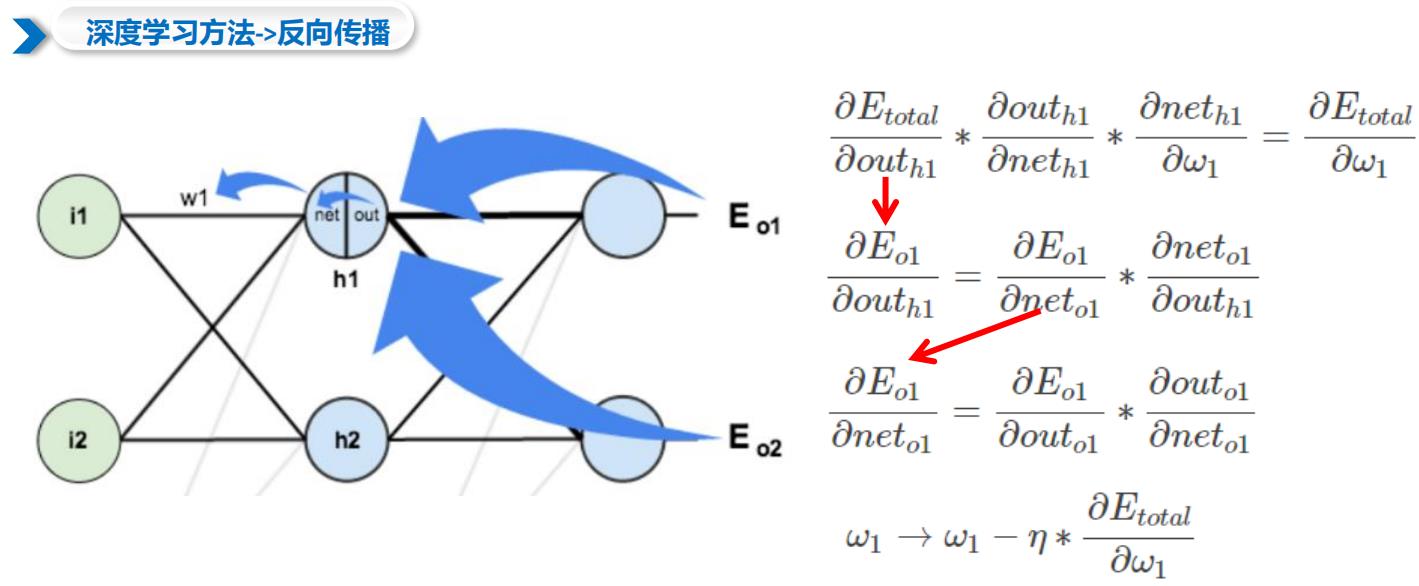
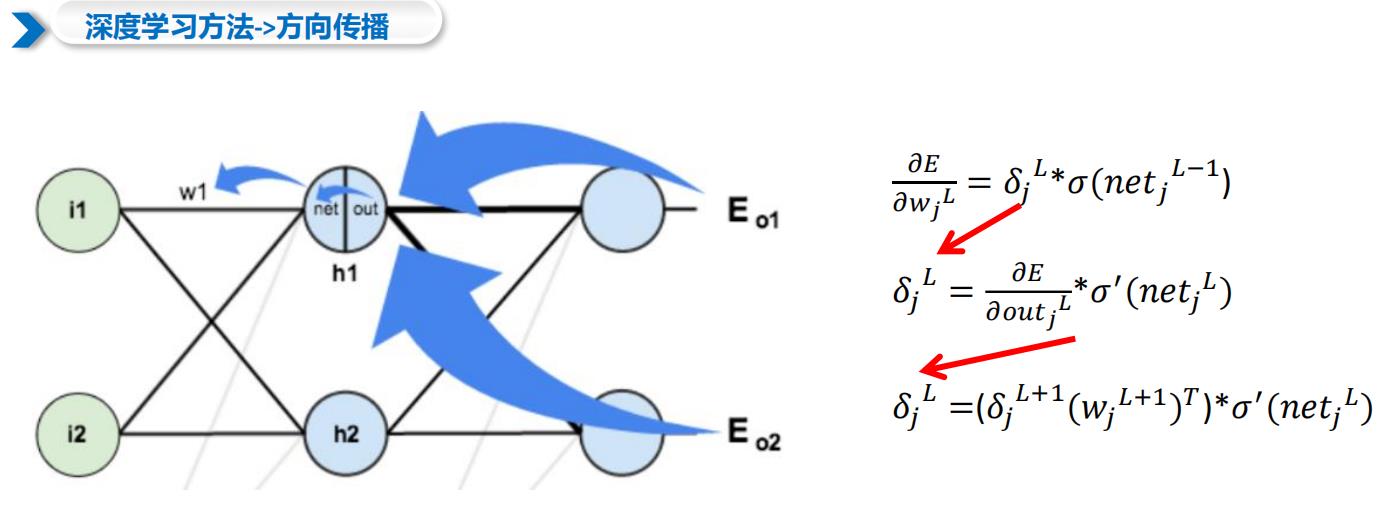
1.2 常见损失函数
1.2.1 均方误差

均方误差是指真实值与预测值之差平方的期望值,常用于回归问题
1.2.2 交叉熵损失函数

交叉熵是指真实类标签分布与模型预测的类标签分布之间的距离,常用于分类问题
深度学习方法

2. 卷积神经网络
2.1 卷积神经网络的产生背景
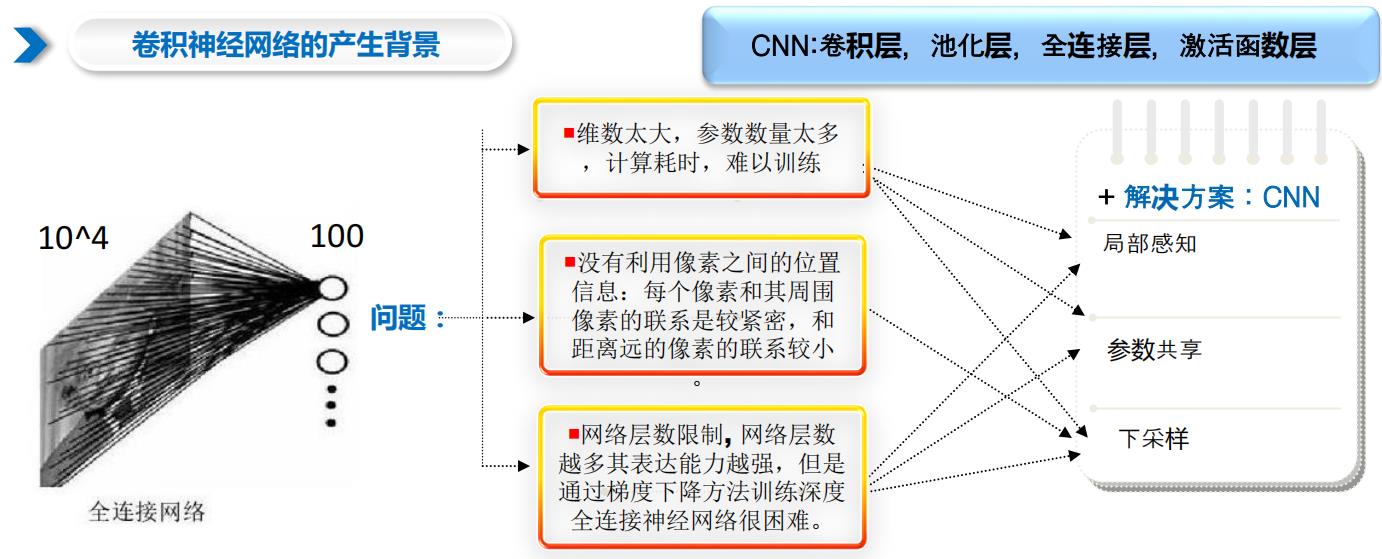
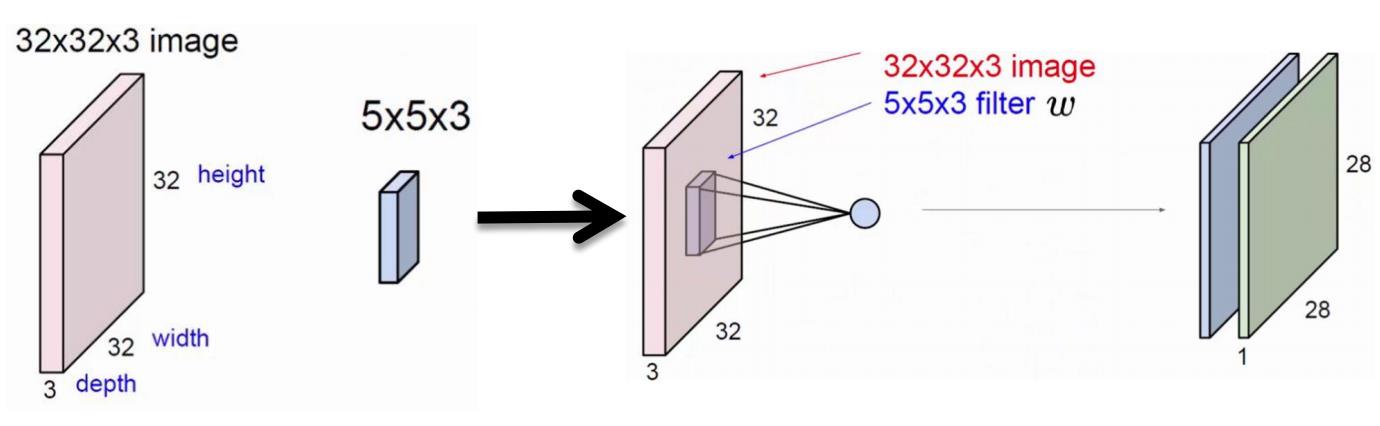
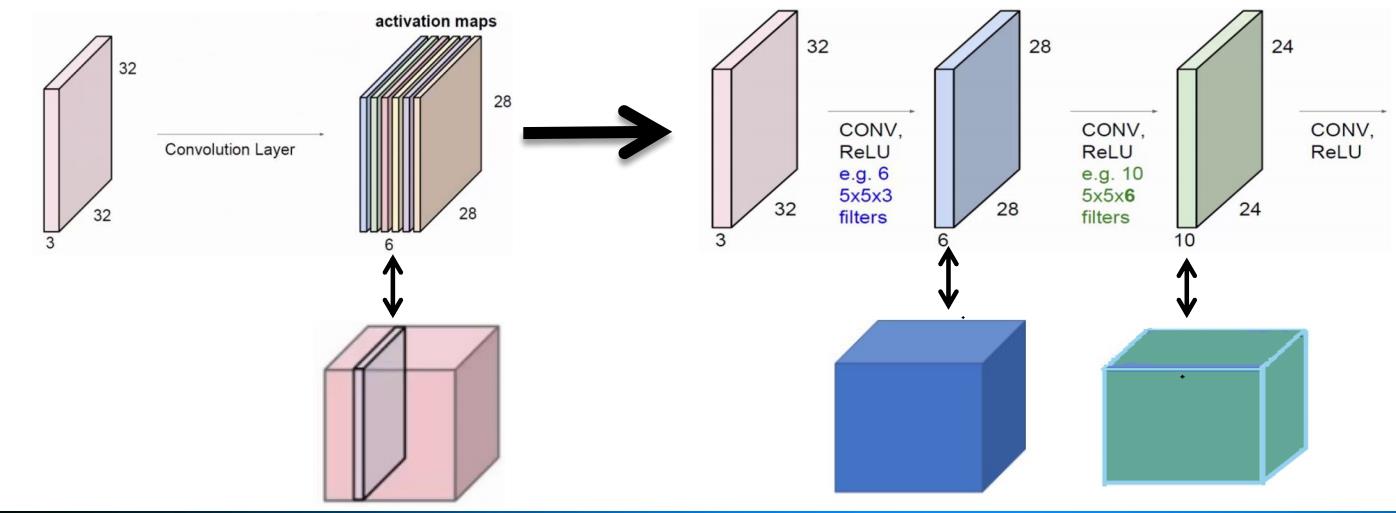
2.2 卷积层






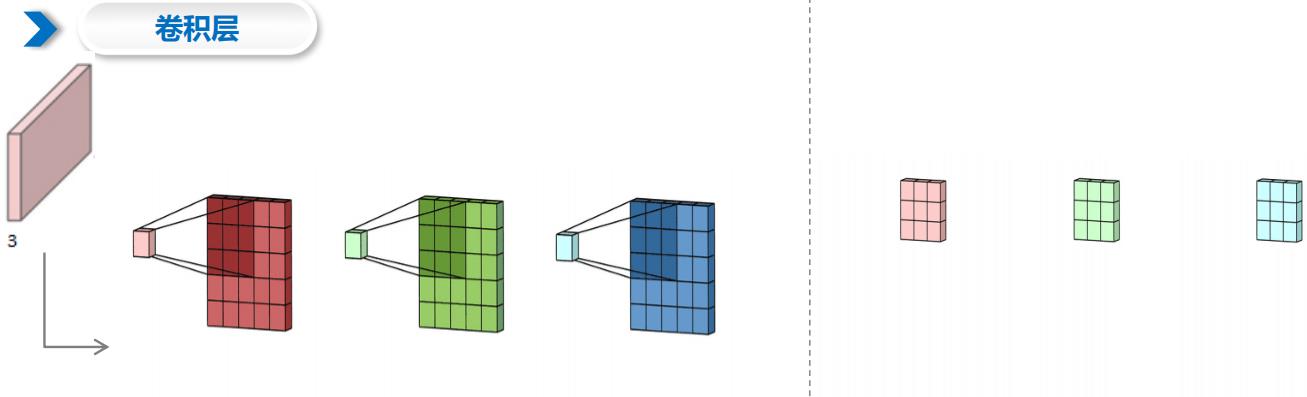

2.3 滤波器与通道数


2.4 池化层
池化:用一个值来代替一块区域

2.5 全连接层
作用:融合学到的深度特征,学习到这些非线性组合特征
将输出值送给分类器

2.6 激活函数层

激活函数作用
模拟人的神经系统,只对部分神经元的输入做出反应;提供网络的非线性建模能力,保证神经网络分层的非线性映射学习能力。
激活函数性质
(1)非线性。
(2)连续可微。梯度下降法的要求。
(3)范围最好不饱和,若系统优化进入饱和阶段,梯度近
似为0,网络的学习就会停止。
(4)单调性,当激活函数是单调时,单层神经网络的误差
函数是凸的,好优化。
(5)在原点处近似线性。这样当权值初始化为接近0的随机值时,网络可以学习的较快,不用可以调节网络的初始值。
**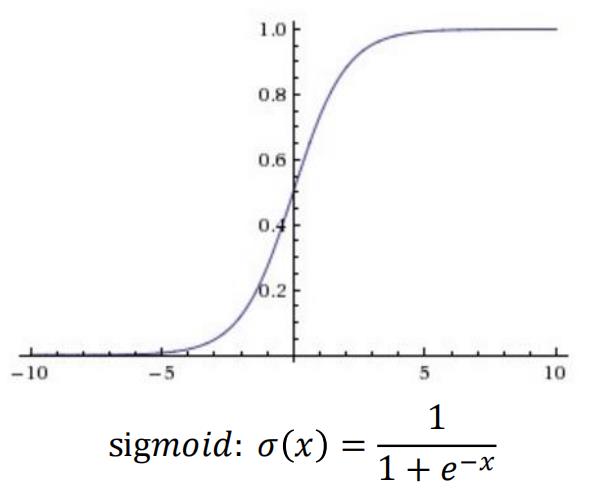
缺点:
1、梯度饱和问题Saturation gradient .
2、Sigmoid 的输出不是零均值的
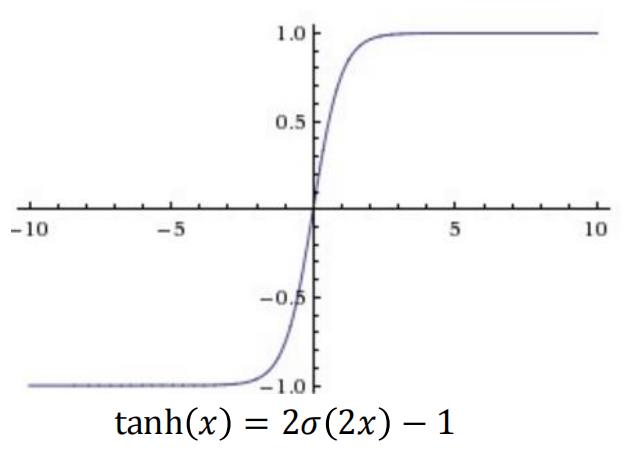
双曲正切函数
存在梯度饱和的问题

优点:ReLU 得到的SGD的收敛速度快(linear), 因为它梯度不会饱和。反向传播算法中,下降梯度等于敏感度乘以前一层的输出值,所以前一层输出越大,下降的梯度越多。
缺点: ReLU在训练的时候很”脆弱”,一不小心有可能导致神经元”坏死”。

 Dead ReLU Problem:指的是带有Relu的某些
Dead ReLU Problem:指的是带有Relu的某些
神经元可能永远不会被激活,导致相应的参数永远不能被更新。
原因:learning rate太高导致在训练过程中参数更新太大,不幸使网络进入这种状态。
解决方案:避免将learning rate设置太大或使用α等自动调节learning rate的算法, α 是通过训练得到的。

激活函数层

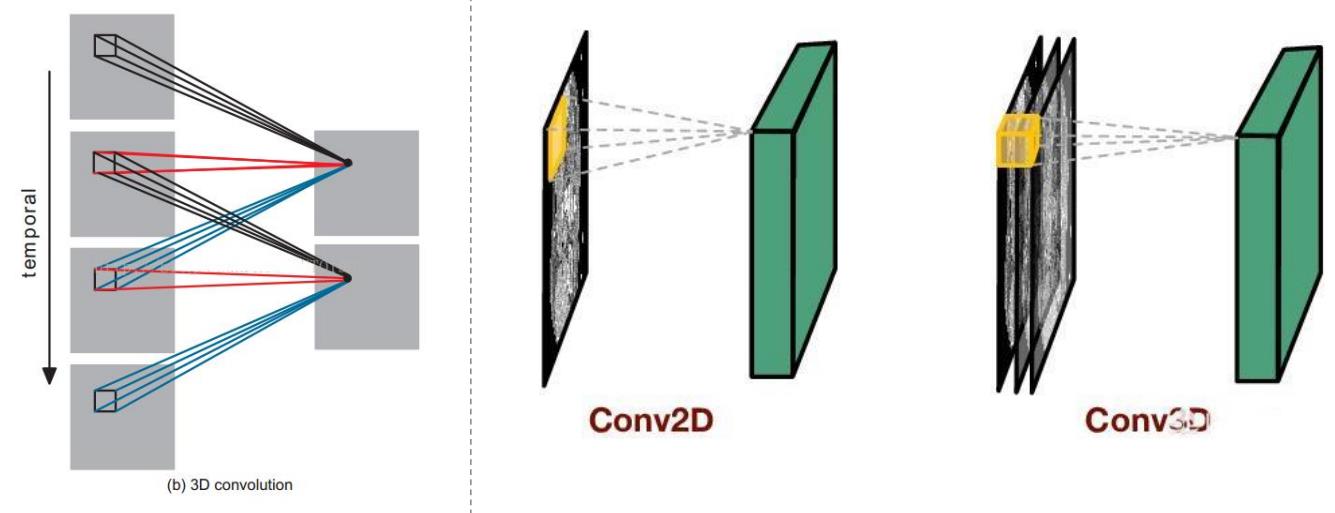
2.7 3D CNN
以上是关于深度学习与图神经网络核心技术实践应用高级研修班-Day1卷积神经网络(CNN详解)的主要内容,如果未能解决你的问题,请参考以下文章