16.4 多模态情感识别
Posted 炫云云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了16.4 多模态情感识别相关的知识,希望对你有一定的参考价值。
文章目录
1、前言
在人类情感交流中, 每个人作为个体, 通过聆听语言、观察表情以及分析语言内容等方式, 感受其他人的情感变化, 识别情感状态信息, 进而进行情感交流。如果想让模型如同人类一样理解情感, 就需要对人类多种情感的表达**(视觉、语音和文本)**进行识别, 让机器具有捕捉多模态情感特征并进行处理, 最后表达出相应人类情感的能力。
目前, 大多数关于情感识别模型的研究集中在语言(尤其是文本)模态上, 但是单模态文本情感识别存在识别率不够高和鲁棒性差等缺点。多模态情感识别可以有效地利用多种模态识别包含的信息, 捕捉模态之间的互补信息, 从而提升模型的识别能力和泛化能力。在进行模态融合之前, 若能够更好地挖掘视觉和语音模态的情感倾向特征, 则 3 种模态表示之间的任务相关性更强, 也更有助于模态的融合。
在多模态情感分析领域, 已经提出大量计算模型, 包括张量融合网络 1、记忆融合网络2和多级注意力循环网络3等。传统的多模态情感分析模型通常将单个模态信号建模为独立的向量表示, 通过模态融合, 进行模态之间相互关联的建模, 但是在模态融合前, 缺少对情感特征的提取, 导致模态间的共享情感特征不易被识别。为了解决这一问题, Akhtar 等4提出使用多任务学习框架, 对情绪识别任务和情感识别任务间的关联建模, 通过相关任务之间的关联性, 对不同模态中的情感特征进行提取。
2、相关工作
文本情感分析
广大学者也越来越重视深度学习在文本情感分析中的应用与研究。
- 文本情感分类:通过卷积等操作显式获取文本的局部和全局的信息,能够快速地处理句子以获取文本特征表达,从而进行分类。
- 篇章情感分类方法:采用了循环卷积和循环相关操作来计算评价文档中的单词与该评价文档的评价对象之间的相关性权重,并将文档中词向量的加权和作为文档向量的表达﹐从而进行情感分类。
- 文档级的情感分类:首先利用卷积神经网络或长短时记忆模型学习句子表示,然后利用门控递归神经网络对句子进行自适应编码以获取文档表示。
图像情感分析
由于图像的情感是更为抽象主观的,图像情感分析任务相比文本情感分析更为复杂。
- 基于图像低级特征的方法,采用视觉词袋模型获取的图像特征和颜色分布来预测图像情感。
- 基于图像中级特征的方法,构建了1200个形容词-名词对(ANP),并以此抽取视觉情感本体,从而对图像进行情感分类。
- 提高局部区域识别力:采用注意力机制自发检测到图像情感相关的视觉区域,
多模态情感识别
多模态机器学习的研究分为模态表示、模态传译、模态对齐、模态融合和联合学习 5 个方面, 多模态情感识别研究主要涉及模态表示、模态对齐、模态融合和联合学习 4 个方面, 当前多集中在模态融合层面。
模态融合的目的是将不同单模态中提取的信息整合到一个紧凑的多模态表示中。根据融合发生的阶段, 分为早期融合、晚期融合和混合融合。
- 早期融合指在编码前对多模态的特征进行融合, 是特征层面的融合。由于发生在特征提取阶段, 早期融合能够有效地提取模态间的交互信息, 但可能忽略单模态内的交互信息。较典型的早期融合模型是EF-LSTM3, 该模型将文本、语音和图像 3 种模态的特征表示进行拼接, 得到多模态表示, 再输入LSTM 中进行编码。
- 晚期融合发生在解码之后, 是决策层面上的融合, 能够提取模态内的交互信息, 但无法提取模态间的交互信息, 常用的方法有平均、投票和加权等。
- 混合融合则组合了前两种融合方法。由于深度学习方法主要用于特征层的处理, 基于深度学习的模态融合方法大多采用早期融合策略和混合策略。
在社交媒体多模态数据的情感分析研究中主要有两个挑战。
- 首先,不同模态数据所包含的情感信息是不同的,在进行多模态数据的情感分析时需要有效地获取各模态数据的情感特征。
- 其次,不同模态的数据采用不同维度和不同属性的底层特征来表达 。
与传统的单一模态情感分析相比,多模态情感分析需要正确结合各模态信息的有效方式,以最大化地保存各模态信息与各模态间的交互信息。
多模态偏移门的模态融合
Rahman 等5提出的 M-BERT 模型将预训练模型应用在多模态情感识别任务中。与 BERT 不同, M-BERT 在输入层与编码层之间加入模态融合层, 并使用多模态偏移门限机制6 ( MSG), 实现 3 种模态的融合。MSG 通过将词向量分别与视觉、语音模态的特征向量拼接, 用于产生两个模态的门向量, 作为模态融合的权重, 生成偏移向量。偏移向量乘上一个比例因子后与词向量相加, 得到修正后的多模态词向量。
多任务学习
多任务学习(multi-task learning, MTL)是机器学习的一个子领域, 其训练过程中包含多个学习任务, 通过利用不同任务间的共性和差异来提高模型的泛化能力和预测准确率。一般来说, 训练不同种类任务需要不同的模型结构, 要实现多任务学习, 就需要实现模型间的参数共享。因此, 多任务学习模型是由多个结构重叠的机器学习模型的组合, 重叠的部分是多个学习任务在反向传播过程中都必须经过的, 称为共享层(shared layers)。
多任务学习模型的参数共享策略主要有硬共享和软共享两种, 其次还有分层共享(hierarchical sharing)和稀疏共享7 (sparse sharing)等。硬共享是最常见的共享策略, 不同任务共享除输出层外的模型部分。硬共享可以同时训练多个任务的通用表示, 有效地避免由于训练数据较少导致的过拟合风险。软共享策略不直接共享模型结构, 每个任务都有自己的模型和参数, 通过对模型相似部分的参数进行正则化来保证模型的参数相似性。
3、模型结构
多任务学习的多模态
图
1
:
基
于
多
任
务
学
习
的
多
模
态
情
感
识
别
框
架
图1 :基于多任务学习的多模态情感识别框架
图1:基于多任务学习的多模态情感识别框架
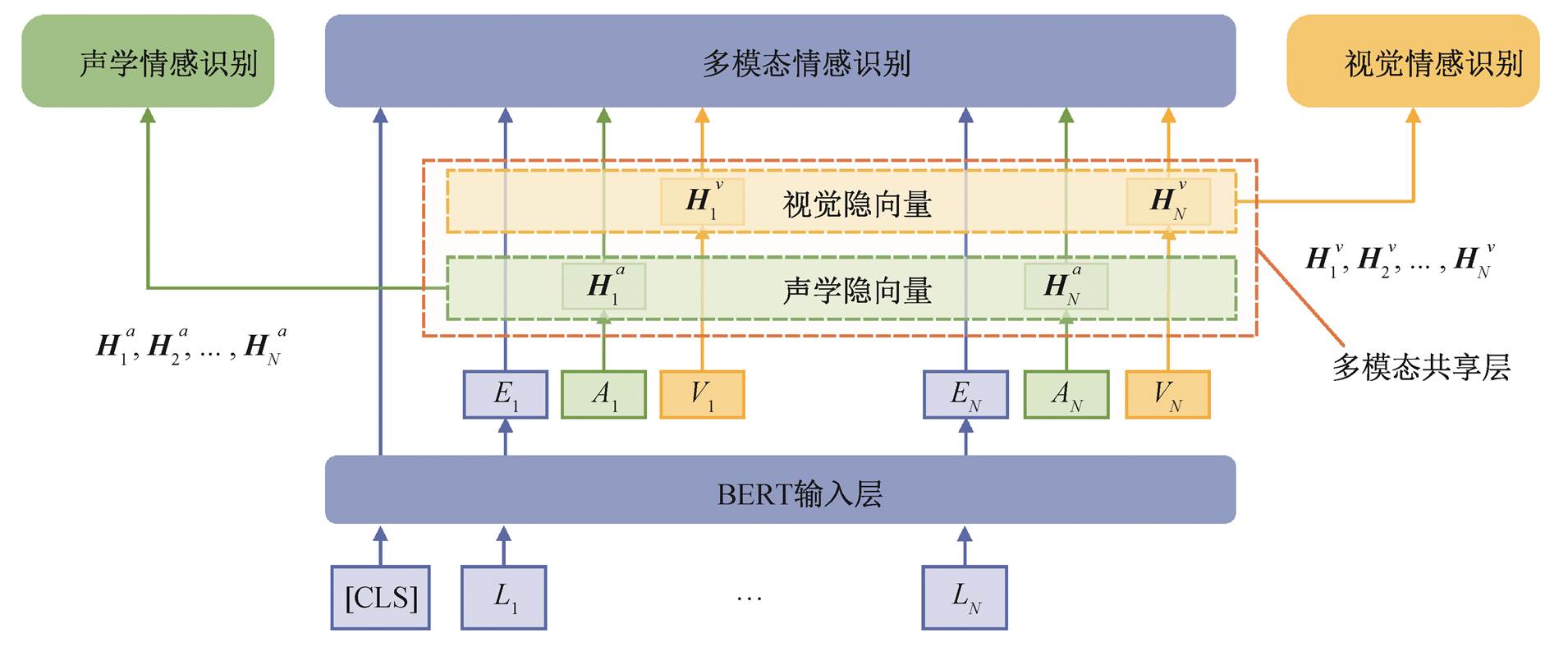
多任务学习的多模态情感识别模型框架如图 1 所示, 模型由以下 3 个部分组成。
-
多模态任务共享层: 包括 3 个任务模型共享的部分, 用于学习视频和语音表示, 位于输入层之后, 编码层之前。在训练的过程中, 每一次反向传播都会经过共享层。
-
多模态情感识别模型: 是加入了共享层的M-BERT, 除共享层外的部分, 只有在其输入为 3种模态的特征向量时, 才会在反向传播过程中更新参数。
-
单模态情感识别模型: 即视频/语音情感识别任务模型, 包括输入层、共享层、编码层和预测层。除共享层外, 只有在输入是任务对应模态的特征向量时, 才会在反向传播过程中更新参数。
共享层
在输入层后面加入视觉和语音共享层, 用于学习更适合情感分类任务的视觉/语音表示。图 1中的视觉隐向量和声学隐向量为视觉特征向量
V
i
V_{i}
Vi 和声学特征向量
A
i
A_{i}
Ai 经过共享层后的输出。这里为视频和语音模态分别设置一个线性层作为共享层, 共享层输出的视觉
/
/
/ 声学隐向量
H
i
v
\\boldsymbol{H}_{i}^{v}
Hiv 和
H
i
a
\\boldsymbol{H}_{i}^{a}
Hia :
H
i
v
=
W
v
⋅
V
i
+
b
v
H
i
a
=
W
a
⋅
A
i
+
b
a
(1)
\\begin{aligned} &\\boldsymbol{H}_{i}^{v}=\\boldsymbol{W}_{v} \\cdot \\boldsymbol{V}_{i}+\\boldsymbol{b}_{v} \\\\ &\\boldsymbol{H}_{i}^{a}=\\boldsymbol{W}_{a} \\cdot \\boldsymbol{A}_{\\mathrm{i}}+\\boldsymbol{b}_{a} \\end{aligned}\\tag{1}
Hiv=Wv⋅Vi+bvHia=Wa⋅Ai+ba(1)
其 中,
i
=
1
,
2
,
…
,
N
,
H
i
v
∈
R
d
r
,
H
i
a
∈
R
d
a
,
W
v
,
W
a
,
b
V
i=1,2, \\ldots, N, \\boldsymbol{H}_{i}^{v} \\in \\mathbb{R}^{\\mathrm{d}_{\\mathrm{r}}}, \\boldsymbol{H}_{i}^{a} \\in \\mathbb{R}^{d_{a}}, \\boldsymbol{W}_{v}, \\boldsymbol{W}_{a}, b_{V}
i=1,2,…,N,Hiv∈Rdr,Hia∈Rda,Wv,Wa,bV 和
b
a
b_{a}
ba 分 别为视频和语音模态共享层的参数权重 和 偏置,
W
v
∈
R
d
1
×
d
r
,
,
W
a
∈
R
d
d
×
d
a
,
b
v
∈
R
d
i
,
b
a
∈
R
d
a
W_{v} \\in \\mathbb{R}^{d_{1} \\times d_{r},}, \\boldsymbol{W}_{a} \\in \\mathbb{R}^{d_{d} \\times d_{a}}, \\boldsymbol{b}_{v} \\in \\mathbb{R}^{d_{i}}, \\boldsymbol{b}_{a} \\in \\mathbb{R}^{d_{a}}
Wv∈Rd1×dr,,Wa∈Rdd×da,bv∈Rdi,ba∈Rda 。
当模型的输入为多模态数据时, 进行多模态情感识别训练, 将共享层输出的视觉隐向量和声学隐向量传入MSG 单元, 与词向量一起进行模态融合; 当输入仅为视频/语音模态的数据时, 进行单模态情感识别训练, 学习到的视觉/声学隐向量将传入后续的单模态编码器中, 经过预测层输出情感极性。
多模态情感识别模型
使用加入多模态任务共享层的 M-BERT模型作为多模态情感识别模型,共享层的位置在特征输入层与模态融合层之间。模型将长度为 N N N 的词序列 ( L 1 , L 2 , ⋯ , L N ) \\left(L_{1}, L_{2}, \\cdots, L_{N}\\right) (L1,L2,⋯,LN) 、视觉特征序列 ( V 1 , V 2 , ⋯ , V N ) \\left(V_{1}, \\quad V_{2}, \\cdots, \\quad V_{N}\\right) (V1,V2,⋯,VN) 和声学特征序列 ( A 1 , A 2 , ⋯ , A N ) \\left(A_{1}, A_{2}, \\cdots, A_{N}\\right) (A1,A2,⋯,AN) 作为输入,词序列经BERT 输入层映射为词嵌入序列 ( E 1 , E 2 , ⋯ , E N ) \\left(E_{1}, E_{2}, \\cdots, E_{N}\\right) (E1,E2,⋯,EN) 。多模态情感识别模型的输出为预测的情感得分 y ~ \\tilde{y}