项目记录--文件压缩1
Posted 水澹澹兮生烟.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了项目记录--文件压缩1相关的知识,希望对你有一定的参考价值。
1.文件压缩的概念
文件压缩是指在不丢失有用信息的前提下,所见数据量以减少存储空间,提高其传输,存储和处理效率,或者按照一定的算法对文件中数据进行重新组织,减少数据冗余和存储的空间的一种技术方法。
2.文件压缩的优点
a.紧缩数据存储容量,减少存储空间
b.可以提高数据传输的速度,减少带宽占用量,提高通讯效率
c.对数据的一种加密保护,增强数据在传输过程中的安全性
3.文件压缩的分类
我们根据解压缩的结构是否产生损害,将其分成无损压缩与有损压缩。
无损压缩是指解压缩的结构与被解压缩的内容是完全相同的,常见的有对文本文件的压缩。
有损压缩是指解压缩的结构不能完全被还原成与文件相同的结构,常见的有图片或者视频进行压缩。
一般情况下,有损压缩算法比无损压缩算法效率高。压缩率=压缩之后结构的大小/源文件大小 。
4.压缩的原理
压缩文件的本质:让文件占用的空间更小。
压缩文件的三种方式:
a.对于公众熟知的词汇利用更短的短语代替
优点:这种压缩较为简单。
缺点:提前需要准备好所有公众熟知的语句以及对应的短语。
b.LZ77,通用的压缩算法
有一些短语重复出现,对重复出现的短语利用更短的短语来进行压缩<距离,长度>,对于没有重复出现的内容,原封不动的王压缩文件中写入。
举个栗子:
给出源文件:accdesdertswccdew
压缩结果:accdesdertsw(11,3)ew
通过无损的压缩算法:accdesdertswccdew
c.对原文件中的字节找一个更短的比特位编码来进行替换
文件中的数据最终是在磁盘上都是以字节方式来进行存储的,一个字节对应8个比特位,如果将源文件中的数据往磁盘中写的时候,每个字节如果都能够找到更短的比特位来进行替换,可以达到压缩文件的目的。它的核心也就是如何给文件中的字节找对应其的更短的编码。
举个栗子:
源文件:ABCDBCDBCDCDCDDD
通过观察源文件发现,源文件总共占了16个字节,但是字符种类一共有4种,因此只需要两个比特位来进行表示。以下是源字符与其对应的二进制编码。
A–00 B–01 C–10 D–11
接下来对每个文件进行压缩:只需要用每个字节对应的二进制编码改写源文件就可以了,因此最后的结果是:00011011011011011011101110111111,最终解压缩文件时将要文件还原成与源文件完全相同的内容,是无损的。
根据上面的例子,我们进一步改进,一般情况下使用的都是不同长的编码进行提花的,不等长编码的方式可以达到更好的压缩率。不等长编码是指编码中比特位个数不同,在这里我们要保证让出现多的次数的字节对应的编码更短一些。
现在我们来看原文件中字节出现的频次:A–1;B–3;C–5;D–7;此时我们可以一字节和其出现 的次数作为叶子节点求构造一棵二叉树。
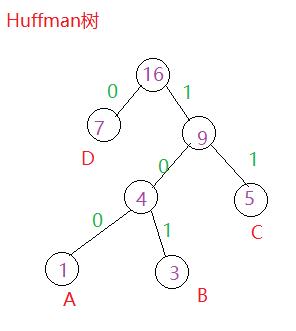
创建好树之后,令左分支为0,右分支为1,获取编码是从根遍历到也直接点所经路径,得到编码如下表:
| 字符 | 编码 |
|---|---|
| A | 100 |
| B | 101 |
| C | 11 |
| D | 0 |
基于Huffamn编码的文件压缩的压缩方式:
- 获取源文件中每个字节出现的次数
- 跟进字节频次信息,构建二叉树(构建Huffman树)
- 获取编码
- 使用获取到的字节的编码对源文件进行改写
5.Huffman的理解与构建
5.1Huffman树定义
从二叉树根节点到二叉树所有叶节点的路径长度与所有权值的乘积之和为该二叉树的带权路径长度WPL。具有最小带权路径长度的二叉树称之为Huffman树,也称之为最优树。
如下所示:
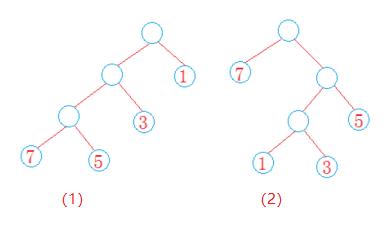
WPL1 = (7+5)3+32+11 =43;WPL2 = 71+5*2+(1+3)*3=29;从这个结构中我们可以知道如何将做到带权路径最短,就是让权值大的节点离得近一点,让权值晓得节点离根节点远一些。
5.2构建Huffman树
- 由给定的n个权值{W1,W2,…,Wn }构造n棵只有根节点的二叉树, 从而得到一个二叉树的集合F={T1,T2,…,Tn }。这就相当于给的权值来构造节点,然后将节点保存起来。
- 在F中选取根节点的权值最小和次小的两棵二叉树作为左、右子树构造一棵新的二叉树,这棵新的二叉树根节点的权值为其左、右子树根节点
- 权值之和。 在集合F中删除作为左、右子树的两棵二叉树,并将新建立的二叉 树加入到集合F中。
- 重复2,3两步,当F中只剩下一棵二叉树时,这棵二叉树 便是所要建立的哈夫曼树。
#include<queue>
#include<vector>
using namespace std;
//保存二叉树中的节点
template<class W>//W代表的是权值
struct HuffmanNode {
HuffmanNode<W>* left;
HuffmanNode<W>* right;
W weight;
HuffmanNode(const W& w):left(nullptr)
,right(nullptr)
,weight(w){}
};
//我们自己写一个比较函数
template<class W>
struct comapre {
typedef huffmanNode<W> Node;
bool operator()(const Node* left, const Node* right) {
return left->weight > right->weight;
}
};
template<class W>
class huffmanTree{
typedef Huffmannode<W> Node;
public:
huffmanTree() :root(nullptr) {}
void CreateHuffmanTree(const W array[], size_t size) {
//优先级队列默认情况下树大堆,我们要修改其比较规则,将其改成小堆
priority_queue<Node* , vector<Node*> , comapre()> q;
//我们先使用所给的权创建只有根节点的二叉树森林,我们采用优先级队列进行保存
for (size_t i = 0; i < size; i++) {
q.push(new Node(array[i]));
}
//循环进行以下步骤,直到我们所给的二叉树森林中只剩下一棵二叉树为止
while (q.size() > 1) {//从二叉树森林中先去权值最小的两棵二叉树
Node* left = q.top();
q.pop();
Node* right = q.top();
q.pop();
//将left和right作为某个新的节点的左右孩子构造一个新的二叉树,新二叉树根节点的权值就是七左右孩子权值之和
Node* parent = new Node(left->weight, right->weight);
parent->left = left;
panret->right = right;
//将新的二叉树插入到二叉树森林中
q.push(parent);
}
//循环结束后,就是我们所需要的huffman树
root = q.top();
}
void destory(Node* &p){//销毁树,不销毁会产生内存泄漏
if (p) {
destory(p->left);
destory(p->right);
delete p;
p = nullptr;
}
}
private:
Node* root;
};
在这里我们遇到了一个问题,如下:
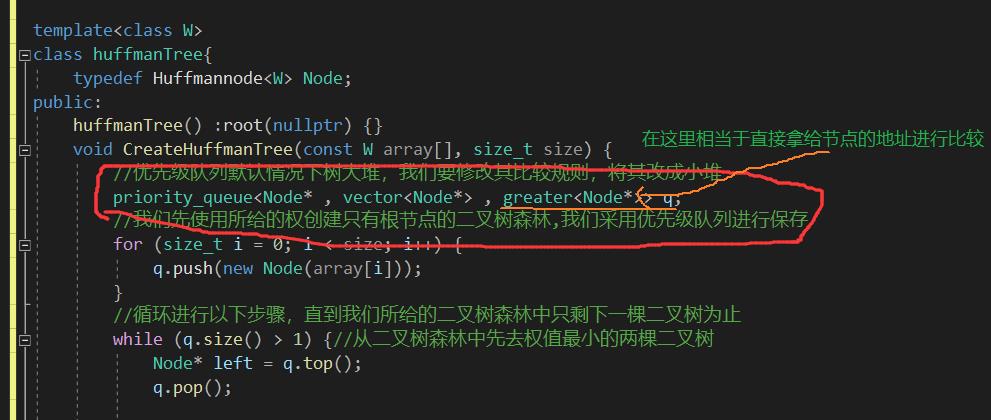
在进行调节大堆成为小堆的时候并没有成功,原因是在将大堆变成小堆的时候,我们二叉树比较的并非权值的大小,而是比较的是地址的大小,此时地址是一个小堆,但是权值并非是是小堆。
以上是关于项目记录--文件压缩1的主要内容,如果未能解决你的问题,请参考以下文章