如何利用 Kyligence+tableau提高分析效率?
Posted 张国荣家的弟弟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何利用 Kyligence+tableau提高分析效率?相关的知识,希望对你有一定的参考价值。
前言
今天和kyligence的团队对其产品的优势和未来合作方向规划有了一个深度的交流研讨,不管是在AI增强的数据服务和管理,抑或是对于灵活响应不断的业务需求,kyligence都能提高海量规模高性能的OLAP服务,无缝连接Bi工具tableau,助力业务用户随时随地获得及时洞察。个人还是蛮看好kyligence未来的发展和以后应用生态搭建的。
将改变人类使用数据的习惯,让使用数据变得更加简单,让最有价值的数据被看见!这句话来自kyligence的创始人李扬对其产品的价值定位。对应其大数据5V特点的数据低价值密度,如何结合业务逻辑并通过强大的机器算法来挖掘数据价值,这是kyligence正在做的事情。下面我们先来了解一下数据服务层,方便我们对后续kyligence 对tableau进行探讨。
数据服务层
现在很多的客户都需要一个工具产品或者是平台整合底下的所有的数据,kyligence可以对接丰富的数据源,支持从多种数据存储系统加载数据,并进行统一的管理和加数。因为一些公司会存在这种情况:公司的不管是业务方面的数据或是内部产生的数据可能会存储在不同的数据库当中,不管是当前老牌的的数据库,mysql,Oracle,以及现在流行的hive数据仓库等都能将它们整合到一起并且能够构建相应的业务需求模型。方便分析师更好的去洞察到业务痛点和如何去解决业务方案。
Kyligence 同时还能在通过ODBC连接现在的主流的BI分析工具,这里呢主要给大家介绍kyligence助力Tableau用户实现交互式分析体验,与Tableau无缝集成,语义模糊互通,海量数据分析实现压秒级响应的。借助kyligence 的强大OLAP引擎,分析效率大大提高,在此基础上,我们可以使用tableau 实现提速。
Tableau 如何连接kyligence
我们先来看一下tableau和kyligence之间的架构,帮助我们更加容易的去理解他们之间的关系。
Tableau+kyligence架构图
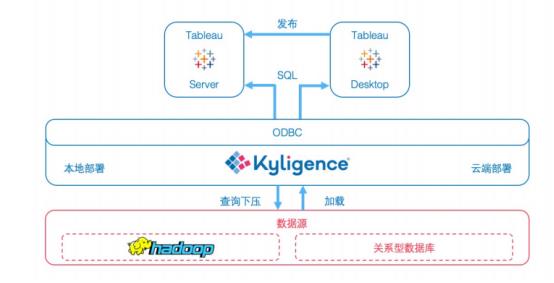
从架构图中我们可以知道tableau与kyligence之间的连接是开发式数据库连接的ODBC行业标准方式连接的,kyligence 基于此标准开发了企业版的kyligence ODBC驱动,tableau通过此驱动访问kyligence enterprise 进行数据的查询。第二种方式我们可以使用Connector连接,Kyligence 基于tableau提供的connector SDK来进行数据源连接进行开发,tableau专为kyligence 特性定制了基于ODBC的数据源接口,针对kyligence查询语法特性定制的,保持查询兼容性。
提高tableau查询性能
操作步骤
1.这里的Model描述了一个星型模式的数据结构,实际就是定义了一个事实表和多个查找表的连接以及过滤关系。
2. Cube描述的式实例的定义和配置选项,包括那些数据模型,包含那些维度和度量,如何进行数据的分区,处理自动合并等。
3. 通过Build Cube 得到,这里包含了一个或者多个Cube Segment
4. Query支持标准的SQL查询
了解了kyligence 这些简单的步骤后,我们使用.tds同步模型(这里说一下.tds也是tableau的数据源文件格式)。在kyligence Enterprise完成建模与创建Cube之后,可以之间导出tableau对应的数据文件,一键同步模型,维度,度量,我们不需要再次重复的建模,以此来提高效率。
提高实时性
使用tableau的用户都知道,当数据量级很大的时候,实时响应的比较满,进而建议我们做数据提取。由于kyligence enterprise 式高性能的分析数据仓库,大大的提高了实时性的提取响应速度。当然如果用户需要脱机数据来缓存,无需连接到可以kyligence enterprise 即可使用,而tableau数据解释功能,会自动支队所选值提高AI驱动解释。
提高Tableau平滑切换数据源和模型变更
对于业务场景的变化快,往往数据源和kyligence的模型需要进行不同程度的变更,对于我们已经发布在tableau server 上面的数据源如何如何去平滑的切换,避免数据源的重构,一般用户最关心的问题。 如果你使用的是企业版的kyligence enterprise 时候,你需要在kyligence里面加载和源数据一样的表,通过同样的步骤,建立模型,Cube,导入.tds数据源文件,接着,在tableau desktop里面打开文件,发布数据源,替换tableau server原来的数据源即可。这样,我们就实现了tableau server的平滑切换到新的数据源了。
提高数据安全性
当客户有对访问数据需要基于角色安全性,不同的角色查看不同的数据和视图。例如销售部门只能看销售部门的视图,财务部只能看财务部的视图,而上层经理或者老板能看得到所有的视图,这时我们制作好的tableau 仪表板或者视图就需要设置权限。但是当我们需要访问的数据的详细级别到达行,列的时候,这时候kyligence就能发挥到它的能力了。我们可以基于实际的场景灵活去选择我们所需的控制行级别权限。

如果当我们的tableau的视图多,用户数多时,我们可以建立权限表,和模型关联,实现批量用权限控制。我们可以在数据库里面插件用户的权限表,并且kyligence enterprise里面创建权限表单,这就是为了在制作报表的时候筛选用户可访问的行级别权限。这是方式实现技术就是实现数据库里面的用户创建权限表和server 上面的用户在视图制作的时候筛选匹配而进一步的达到控制权限的方法。
提高查询server工作簿性能
当我们在tableau desktop上设计字段很复杂,数据量大的时候,上传到server里面,经常遇到查看视图和数据时候响应的时间会有点慢。现在我们可以在kyligence和tableau他们之间做缓存,缓存的越有效,相对的环境效率就更高,查询工作簿的时候可以更快的返回结果。
Viz 客户段监控用户交互的会话(例如:为一个工具提示悬停,选择标记,高亮显示,过滤交互等等如下图),如果需要制作内容,需要想服务器发送一个请求来获取新的贴片,客户机不存储任何数据,因此所有的交互都需要一个服务器的往返。

我们为了提高性能,我们将这些贴片图像保存在tableau server 的贴片缓存中,当我们在此请求此动作时候,可以从缓存里面提供,而不是重新从server上面在发送,这时候就会快很多。为了提升查询效率,kyligence enterprise 系统自带查询缓存,并且是默认开启的,这就更好的提升在集群部署环境下查询效率。如果我们想对缓存的一些配置进行自定义的修改,可以在kyligence enterprise安装目录下面进行我们需要的修改设置。
注意:修改之后需要重新启动才能生效。
最后,跟kyligence团队沟通了一下特定场景的一些功能,像银行行业对数据特别敏感,需要进行数据脱敏,对某些敏感信息通过脱敏规则进行相应的数据变形,实现敏感隐私数据的可保护性,这样就可以在tableau环境进行安全使用脱敏后的真实数据集。类似的场景的话kyligence团队会进行低代码的开发,进而加速了应用程序,部署环境的集成,开发的周期相对较短。综合来说kyligence整体的功能和可拓展性还是很强的。
以上是关于如何利用 Kyligence+tableau提高分析效率?的主要内容,如果未能解决你的问题,请参考以下文章