使用Python,OpenCV进行Tesseract-OCR绑定及识别
Posted 程序媛一枚~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用Python,OpenCV进行Tesseract-OCR绑定及识别相关的知识,希望对你有一定的参考价值。
使用Python,OpenCV进行Tesseract-OCR绑定及识别
上一篇博客介绍了Windows上Tesseract-OCR的安装,并使用命令行参数进行了OCR数字和字母的识别。这一篇将介绍如何使用Python应用Tesseract-OCR绑定,并进行图像上字符的识别。当前景文本与背景进行(非常)清晰的分割时,Tesseract-OCR将获得好的效果。
-
最大的缺点是Tesseract本身的局限性。当前景文本与背景之间有非常清晰的分割时,Tesseract效果最佳。
-
这些分割需要尽可能高的分辨率(DPI),并且分割后输入图像中的字符不能出现“像素化”。如果字符确实出现像素化,那么Tesseract将难以正确识别文本。
-
将OCR应用于真实世界的无约束图像时,仍有挑战。深度学习和卷积神经网络(CNN)将能够获得更高的精度
-
在将OCR应用于项目时,建议首先尝试Tesseract,如果结果不理想,可使用Google 在线API。
-
如果Tesseract和Google Vision API都没有获得合理的准确度,则需要重新评估数据集,并决定是否要培训自定义字符分类器。
1. 效果图
原始图如下:

命令行Tesseract-OCR结果如图:
tesseract版本 v5.0.0,可以看到高于v4,使用的是长短时记忆(LSTM)OCR模型,该模型比Tesseract的早期版本精确得多!
 Python+Tessearct-OCR绑定识别,预处理(阈值化)后的效果图如下:
Python+Tessearct-OCR绑定识别,预处理(阈值化)后的效果图如下:
可以看到阈值化后的图像相当清晰,分辨率也很高,因此成功识别。

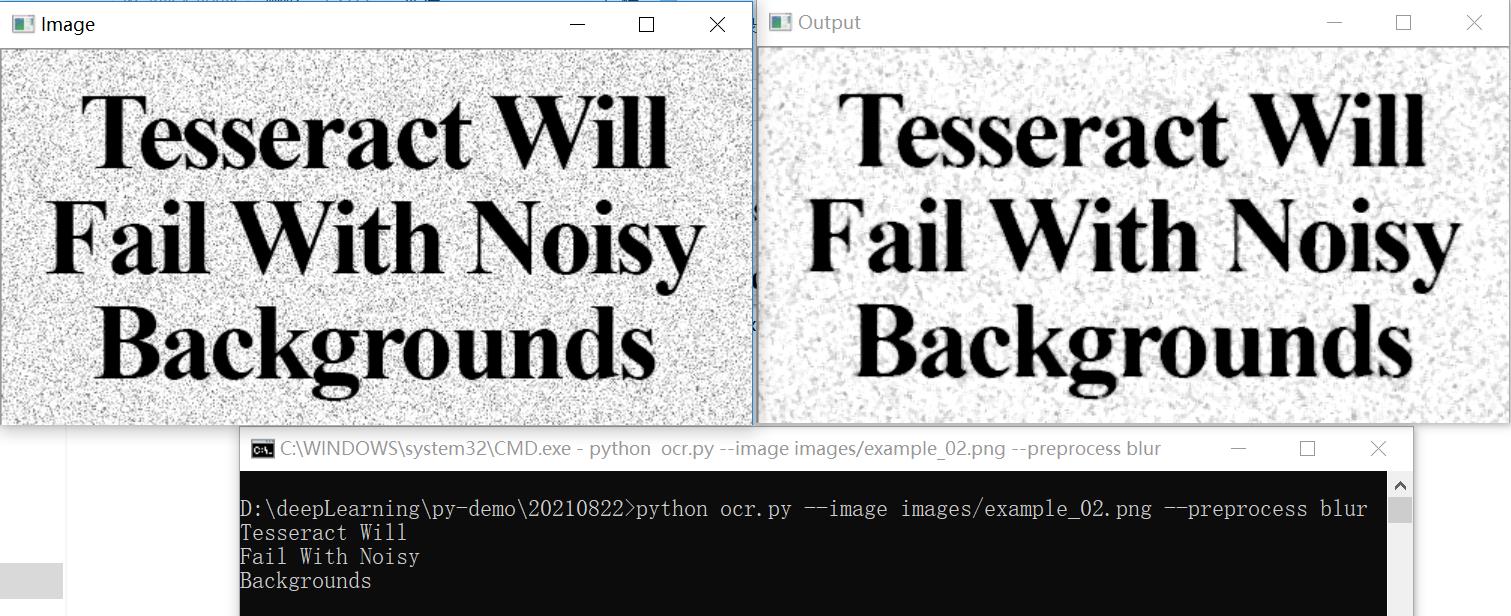
Python+Tessearct-OCR绑定识别,预处理(中值模糊)后的效果图如下:
可以看到成功识别~

效果图2——原始图VS 阈值化后的图像:

噪音更多一些的Tesseract-OCR命令行也能成功识别:

python+Tesseract-OCR预处理(阈值化后)识别效果图如下:

python+Tesseract-OCR预处理(中值模糊后)识别效果图如下:
可以看到中值模糊后有不少噪音,依然成功识别~
更多的文本也可以成功识别,Python+Tesseract-OCR效果图如下:

2. 安装Tesseract+Python“绑定”及识别
- 安装pillow,它是一个对Python更友好的PIL(一个依赖项)端口
- 安装tesseract
pip install pillow
pip install pytesseract
pytesseract 不提供真正的Python绑定。相反,它只是提供了一个到tesseract的调用映射接口。然后调用tesseract二进制文件,并捕获结果输出。
可以使用Tesseract for OCR获得良好或可接受的结果,但最好的准确度将来自对实际图像中出现的特定字体集的自定义字符分类器进行训练。
通过升级Tesseract版本来提高OCR准确性。
如果在输出中看到Tesseract v4或更高版本,则使用的是长短时记忆(LSTM)OCR模型,该模型比Tesseract的早期版本精确得多!
如果看到任何低于v4的版本,则应升级Tesseract安装-使用Tesseract v4 LSTM引擎将获得更准确的OCR结果。
3. 源码
# 使用pytesseract调用tesseract-ocr进行OCR识别
# 命令行ocr
# tesseract D:\\deepLearning\\py-demo\\20210822\\images\\example_01.png stdout
# USAGE
# python ocr.py --image images/example_01.png
# python ocr.py --image images/example_01.png --preprocess blur
# 导入必要的包
from PIL import Image #以PIL格式加载磁盘图像
import pytesseract
import argparse
import cv2
import os
# 构建命令行参数及解析
# --image 输入图像路径
# --preprocess:预处理类型,thresh或blur
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required=True,
help="path to input image to be OCR'd")
ap.add_argument("-p", "--preprocess", type=str, default="thresh",
help="type of preprocessing to be done")
args = vars(ap.parse_args())
# 加载图像并转换为灰度图
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 预处理以便将前景与背景分割开来
# 检测是该用阈值还是模糊预处理步骤
if args["preprocess"] == "thresh":
gray = cv2.threshold(gray, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
# 检测是否应该用中值模糊
# 应用中值模糊有助于减少椒盐噪声,使Tesseract更容易正确地对图像进行OCR。
elif args["preprocess"] == "blur":
gray = cv2.medianBlur(gray, 3)
# 将灰度图临时写入磁盘以调用OCR识别
filename = "{}.png".format(os.getpid())
cv2.imwrite(filename, gray)
# 以PIL(pillow)格式加载图像,应用OCR,删除临时文件
# 将图像的内容转换为所需的字符串文本
text = pytesseract.image_to_string(Image.open(filename))
os.remove(filename)
# 输出识别的文本值
print(text)
# 展示原始图像和预处理图像
cv2.imshow("Image", image)
cv2.imshow("Output", gray)
cv2.waitKey(0)
参考
以上是关于使用Python,OpenCV进行Tesseract-OCR绑定及识别的主要内容,如果未能解决你的问题,请参考以下文章
音视频处理图像处理图像识别和字符识别全能库JavaCV完整教程(包含完整JavaCV入门JavaCV实战ffmpegopencv和tesserac教程)