Hivehive函数与hive shell
Posted 人生,唯有锻炼与读书不能辜负
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hivehive函数与hive shell相关的知识,希望对你有一定的参考价值。
一、hive函数
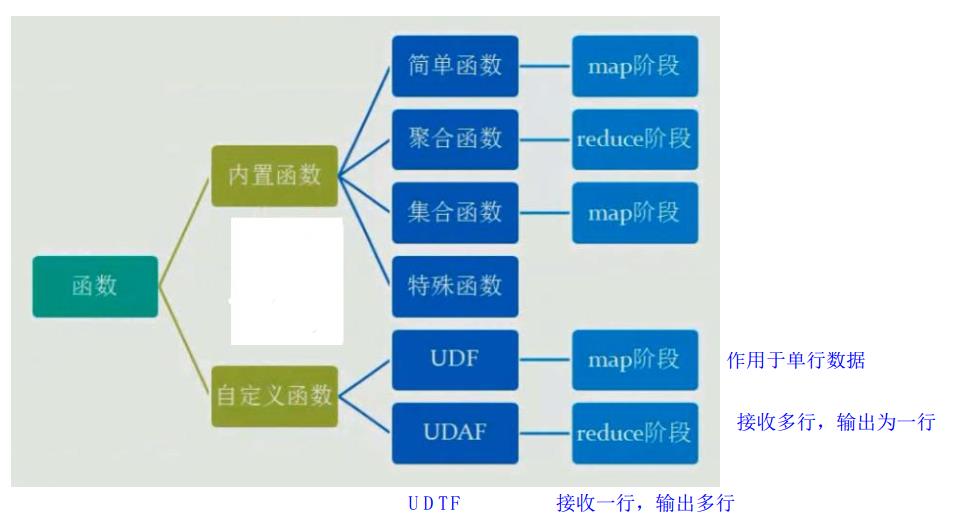
1、hive内置函数
(1)内容较多,见《 Hive 官方文档》
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
(2)详细解释:
http://blog.sina.com.cn/s/blog_83bb57b70101lhmk.html
(3) 测试内置函数的快捷方式:
1、创建一个 dual 表 create table dual(id string);
2、 load 一个文件(一行,一个空格)到 dual 表
3、 select substr(\'huangbo\',2,3) from dual;
(4)查看内置函数 show functions;
显示函数的详细信息 desc function abs;
显示函数的扩展信息 desc function extended concat;
(5)详细使用见文档
2、hive自定义函数
当 Hive 提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函 数
UDF ( user-defined function)作用于单个数据行,产生一个数据行作为输出。(数学函数, 字符串函数)
UDAF(用户定义聚集函数 User- Defined Aggregation Funcation):接收多个输入数据行,并产 生一个输出数据行。( count, max)
3、一个简单的UDF函数示例:
(1)先开发一个简单的 java 类,继承 org.apache.hadoop.hive.ql.exec.UDF,重载 evaluate 方法

(2)打成jar包上传到服务器
(3) 将 jar 包添加到 hive 的 classpath
hive>add JAR /root/hivejar /udf.jar;
(4)创建临时函数与开发好的 class 关联起来
Hive>create temporary function tolowercase as \' com.mazh.udf. ToLowerCase \';
(5)至此,便可以在 hql 在使用自定义的函数
select tolowercase(name),age from studentss;
4、Transform实现 (把json数据中timeStamp字段变成日期编号)
Hive 的 TRANSFORM 关键字提供了在 SQL 中调用自写脚本的功能。适合实现 Hive 中没有的 功能又不想写 UDF 的情况
具体以一个实例讲解。
(1)先加载 rating.json 文件到 hive 的一个原始表 rat_json
create table rat_json(line string) row format delimited;
load data local inpath \'/root/rating.json\' into table rat_json;
(2) 创建 rate 这张表用来存储解析 json 出来的字段:
create table rate(movie int, rate int, unixtime int, userid int) row format delimited fields
terminated by \'\\t\';
解析 json,得到结果之后存入 rate 表:
insert into table rate select get_json_object(line,\'$.movie\') as moive,get_json_object(line,\'$.rate\')
as rate,get_json_object(line,\'$.timeStamp\') as unixtime,get_json_object(line,\'$.uid\') as userid
from rat_json;
(3)使用 transform+python 的方式去转换 unixtime 为 weekday
先编辑一个 python 脚本文件
vi weekday_mapper.py
#!/bin/python
import sys
import datetime
for line in sys.stdin:
line = line.strip()
movie,rate,unixtime,userid = line.split(\'\\t\')
weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday()
print \'\\t\'.join([movie, rate, str(weekday),userid])
保存文件
然后,将文件加入 hive 的 classpath:

最后查询看数据是否正确:
select distinct(weekday) from lastjsontable;
二、Hive Shell 操作
1、hive 命令行

语法结构:
hive [-hiveconf x=y]* [<-i filename>]* [<-f filename>|<-e query-string>] [-S]
说明:
(1) -i 从文件初始化 HQL。
(2) -e 从命令行执行指定的 HQL
(3) -f 执行 HQL 脚本
(4) -v 输出执行的 HQL 语句到控制台
(5) -p <port> connect to Hive Server on port number
(6) -hiveconf x=y( Use this to set hive/hadoop configuration variables)
(7)-S 表示以不打印日志的形式执行 (hive -S -e ......)
实例:
(1)
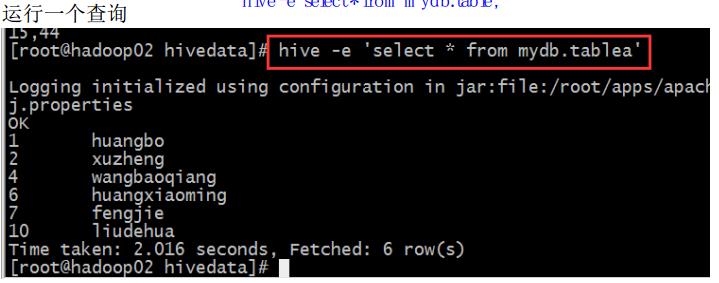
(2)运行一个文件
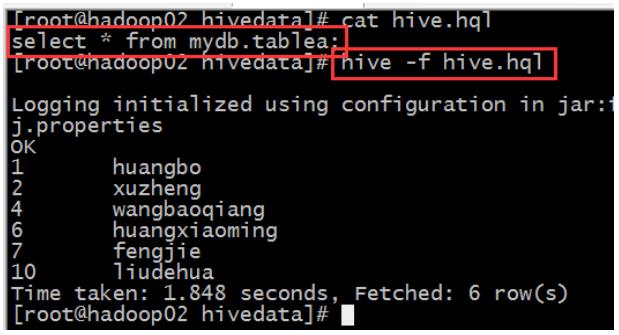
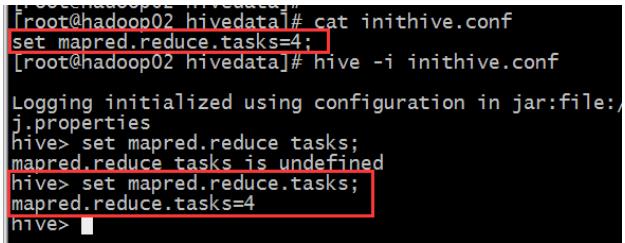
(3)运行参数文件
从配置文件启动 hive,并加载配置文件当中的配置参数
2、hive参数配置方式
hive参数大全:https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
开发 Hive 应用时,不可避免地需要设定 Hive 的参数。设定 Hive 的参数可以调优 HQL 代码 的执行效率,或帮助定位问题。然而实践中经常遇到的一个问题是,为什么设定的参数没有起作用?这通常是错误的设定方式导致的。
对于一般参数,有以下三种设定方式:
配置文件 (全局有效)
命令行参数(对 hive 启动实例有效) (hive -i ...)
参数声明 (对 hive 的连接 session 有效)(进入hive客户端之后设置)
优先级:参数声明 高于命令行参数 高于配置文件
(1)配置文件: Hive 的配置文件包括
用户自定义配置文件: $HIVE_CONF_DIR/hive-site.xml
默认配置文件: $HIVE_CONF_DIR/hive-default.xml
用户自定义配置会覆盖默认配置。
另外, Hive 也会读入 Hadoop 的配置,因为 Hive 是作为 Hadoop 的客户端启动的, Hive 的配
置会覆盖 Hadoop 的配置。
配置文件的设定对本机启动的所有 Hive 进程都有效。
(2)命令行参数:启动 Hive(客户端或 Server 方式)时,可以在命令行添加-hiveconf param=value
来设定参数,例如:
bin/hive -hiveconf hive.root.logger=INFO,console
这一设定对本次启动的 Session(对于 Server 方式启动,则是所有请求的 Sessions)有效。
(3)
参数声明:可以在 HQL 中使用 SET 关键字设定参数,例如:
set mapred.reduce.tasks=100;
这一设定的作用域也是 session 级的。
set hive.exec.reducers.bytes.per.reducer=<number> 每个 reduce task 的平均负载数据量 hive 会估算我们的总数据量,然后用总数据量除以上述参数值,就能得出需要运行的 reduce task 数
set hive.exec.reducers.max=<number> 设置 reduce task 数量的上限
set mapreduce.job.reduces=<number> 指定固定的 reduce task 数量 但是,这个参数在必要时<业务逻辑决定只能用一个 reduce task> hive 会忽略
上述三种设定方式的优先级依次递增。即参数声明覆盖命令行参数,命令行参数覆盖配置文 件设定。注意某些系统级的参数,例如 log4j 相关的设定,必须用前两种方式设定,因为那 些参数的读取在 Session 建立以前已经完成了。
以上是关于Hivehive函数与hive shell的主要内容,如果未能解决你的问题,请参考以下文章