教你如何打造网页爬虫工具(实现思路及源码下载)
Posted 显亮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了教你如何打造网页爬虫工具(实现思路及源码下载)相关的知识,希望对你有一定的参考价值。
现在网页爬虫代码可谓是满天飞,特别是python、php写的居多,百度随便一搜,满屏都是,不管什么计算机语言编写的,性能都不会相关到哪里去,重要的是实现思路。
一、实现思路
1、以前的思路
下面我说说我个人的实现思路:
十多年前,我写过了一款爬虫,当时的思路:
1、根据设定的关键词。
2、百度搜索相关关键词并保存。
3、遍历关键词库,搜索相关网页信息。
4、提取搜索页面的页面链接。
5、遍历每页的网页链接。
6、爬取网页数据。
7、解析数据、构造标题、关键词、描述、内容,并入库。
8、部署到服务器上、每天自动更新html页面。
这里最关键的点就是:标题的智能组织、关键词的自动组合、和内容的智能拼接。
当时、在搜索引擎还没有那么智能的时候,效果相当好!百度收录率非常高。
2、现在的思路
数据采集部分:
根据设定的最初关键词,从百度搜索引擎搜索相关关键词,遍历相关关键词库,爬取百度数据。
构建数据部分:
根据原有的文章标题,分解为多个关键词,作为SEO的关键词。同样,分解文章内容,取第一段内容的前100个字作为SEO的网页描述。内容就不变,整理好数据,入库保存。
文章发布部分:
根据整理好的数据(SEO相关设置),匹配相关页面模板,依次生成文章内容页、文章列表页面、网站首页。部署到服务器上,每天自动更新设定数量的文章。
二、相关流程
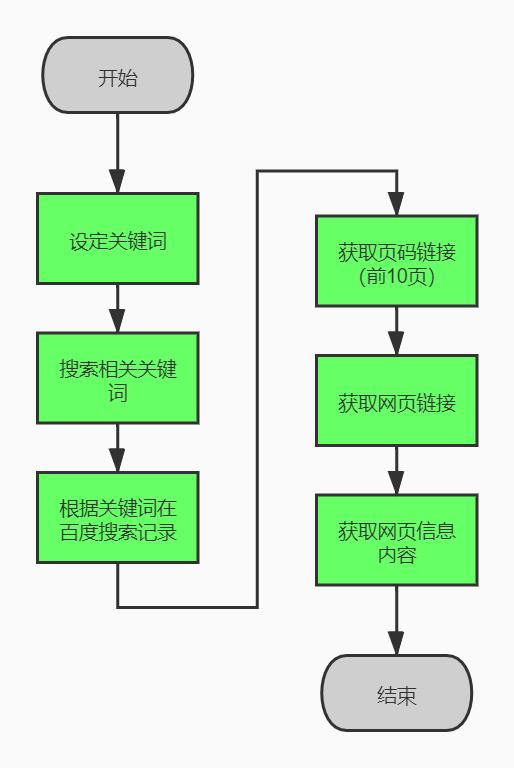
1.抓取数据流程
1、设定关键词。
2、根据设置关键词搜索相关关键词。
3、遍历关键词,百度搜索结果,获取前10页页面。
4、根据页码链接、获取前10页(大概前100条数据,后面的排名已经很后了,没多大意义)
5、获取每页的网页链接集合。
6、根据链接获取网页信息(标题、作者、时间、内容、原文链接)。
2.数据生成流程
1、初始化表(关键词、链接、内容、html数据、发布统计)。
2、根据基础关键词抓取相关关键词,并入库。
3、抓取链接,入库。
4、抓取网页内容、入库。
5、构建html内容,入库。

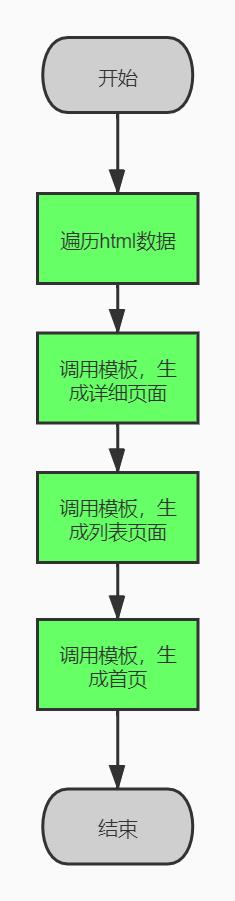
3.页面发布流程
1、从html数据表中从早到晚获取数据。
2、创建内容详细页。
3、创建内容列表页面。
4、创建首页。
4.相关数据表
1、关键词表
2、URL表
3、网页内容表
4、html数据表
5、发布记录表

5.项目的结构目录
项目是用.net5写的,可以在windows服务、linux服务跑,分三部分。
1、类库项目
2、数据采集项目
3、生成页面项目

6.运行效果截图
1、内页生成效果

2、列表页生成效果

3、首页生成效果

最后
由于篇幅比较长,涉及到很多细节方面,例如:网页关键词、描述如何智能重组,相关文章如何智能自动归类等等、代码我就不贴了,需要代码的加我vixin:xiaoqiu20121212,注明:爬虫代码。注意:该工具只限于学习使用!!!
以上是关于教你如何打造网页爬虫工具(实现思路及源码下载)的主要内容,如果未能解决你的问题,请参考以下文章
华为云技术分享40行代码教你利用Python网络爬虫批量抓取小视频
python网络爬虫抓取动态网页并将数据存入数据库MySQL
非常适合新手的一个Python爬虫项目: 打造一个英文词汇量测试脚本!