zookeeper和Kafka的关系
Posted 垃圾王子晗
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了zookeeper和Kafka的关系相关的知识,希望对你有一定的参考价值。
1 zookeeper必备知识
- zk的整体结构很像java中的数,zk的单个节点很像java中的接待,也就是一个Node由value值和nexts指针构成;也就是ls /作为根节点,其它节点都派生于此
- ls时用于查看目录结构的命令,比如 ls / 该命令就是查看根目录下的子目录;目录可以理解为zk节点中 指针所表示的内容,而每个节点也有自己的值,可以通过get {path} 即可获到节点的值
- 有的节点只是为了存储值而已,也有的节点完全起到目录的作用,不会存储值(null),比如kafka存储在zookeeper上的节点信息中 /brokers,/ids只是作为目录;而/controller_epoch只是作为
- Node 可以分为持久节点和临时节点两类。所谓持久节点是指一旦这个 ZNode 被创建了,除非主动进行 ZNode 的移除操作,否则这个 ZNode 将一直保存在 ZooKeeper 上。而临时节点就不一样了,它的生命周期和客户端会话绑定,一旦客户端会话失效,那么这个客户端创建的所有临时节点都会被移除。
- Watcher(事件监听器),是 ZooKeeper 中的一个很重要的特性。ZooKeeper 允许用户在指定节点上注册一些 Watcher,并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知到感兴趣的客户端上去,该机制是 ZooKeeper 实现分布式协调服务的重要特性。
2 zk节点和watcher在kafka中的体现
Kakfa Broker集群受Zookeeper管理。所有的Kafka Broker节点一起去Zookeeper上注册一个临时节点,因为只有一个Kafka Broker会注册成功(共同注册/controller,但最终只有一个成功),其他的都会失败,所以这个成功在Zookeeper上注册临时节点的这个Kafka Broker会成为Kafka Broker Controller,其他的Kafka broker叫Kafka Broker follower。也就是为/Controller节点在ZooKeeper注册Watch。这个Controller会监听其他的Kafka Broker的所有信息,如果这个kafka broker controller宕机了,在zookeeper上面的那个临时节点就会消失,此时所有的kafka broker又会一起去 Zookeeper上注册一个临时节点,因为只有一个Kafka Broker会注册成功,其他的都会失败,所以这个成功在Zookeeper上注册临时节点的这个Kafka Broker会成为Kafka Broker Controller,其他的Kafka broker叫Kafka Broker follower 。例如:一旦有一个broker宕机了,这个kafka broker controller会读取该宕机broker上所有的partition在zookeeper上的状态,并选取ISR列表中的一个replica作为partition leader(如果ISR列表中的replica全挂,选一个幸存的replica作为leader; 如果该partition的所有的replica都宕机了,则将新的leader设置为-1,等待恢复,等待ISR中的任一个Replica“活”过来,并且选它作为Leader;或选择第一个“活”过来的Replica(不一定是ISR中的)作为Leader),这个broker宕机的事情,kafka controller也会通知zookeeper,zookeeper就会通知其他的kafka broker。
在Kafka的设计中,选择了使用Zookeeper来进行所有Broker的管理,kafka配置文件中有关kafka和zookeeper的配置如下,意思是每个broker上的本地zookeeper都会注册整个kafka集群的服务信息
zookeeper.connect=hadoop01:2181,hadoop02:2181,hadoop03:2181
以下是每个broker服务上zookeeper的连接配置
/brokers/ids专门用来进行kafka集群服务器列表记录的点;
/brokers/topics专门用来记录kafka集群服务器中的全部topic;
/brokers/topics/{topicName}:记录名为xxx的topic
/brokers/topics/topic-n/partitions:记录每个topic下的全部分区信息,包括一个【offse】
/brokers/topics/topic-n/partitions/{partitionNo}:0代表0号分区,1代表1号分区,以此类推
/brokers/topics/topic-n/partitions/{partitionNo}/state:存储中央控制器controller选取次数、leader partition所在broker的id,leader选举此时,初始时0,isr信息
/controller:kafka 存储服务器集群注册到zookeeper时成为controller的broker这个节点信息
/controller_epcho:kafka 存储服务器集群注册到zookeeper时成为controller的broker这个节点信息
声明:0.9之前offset存储在zk下,也就是consumer相关的信息存在zk下的consumers下了,但是0.9版本后consumer的信息存储在了brokers上的一块内存中了 /brokers/topics/__consumer_offsets/下存储,其中offset时以topic的分区为单位进行存储的,offset在通过javaapi些代码时会接触到
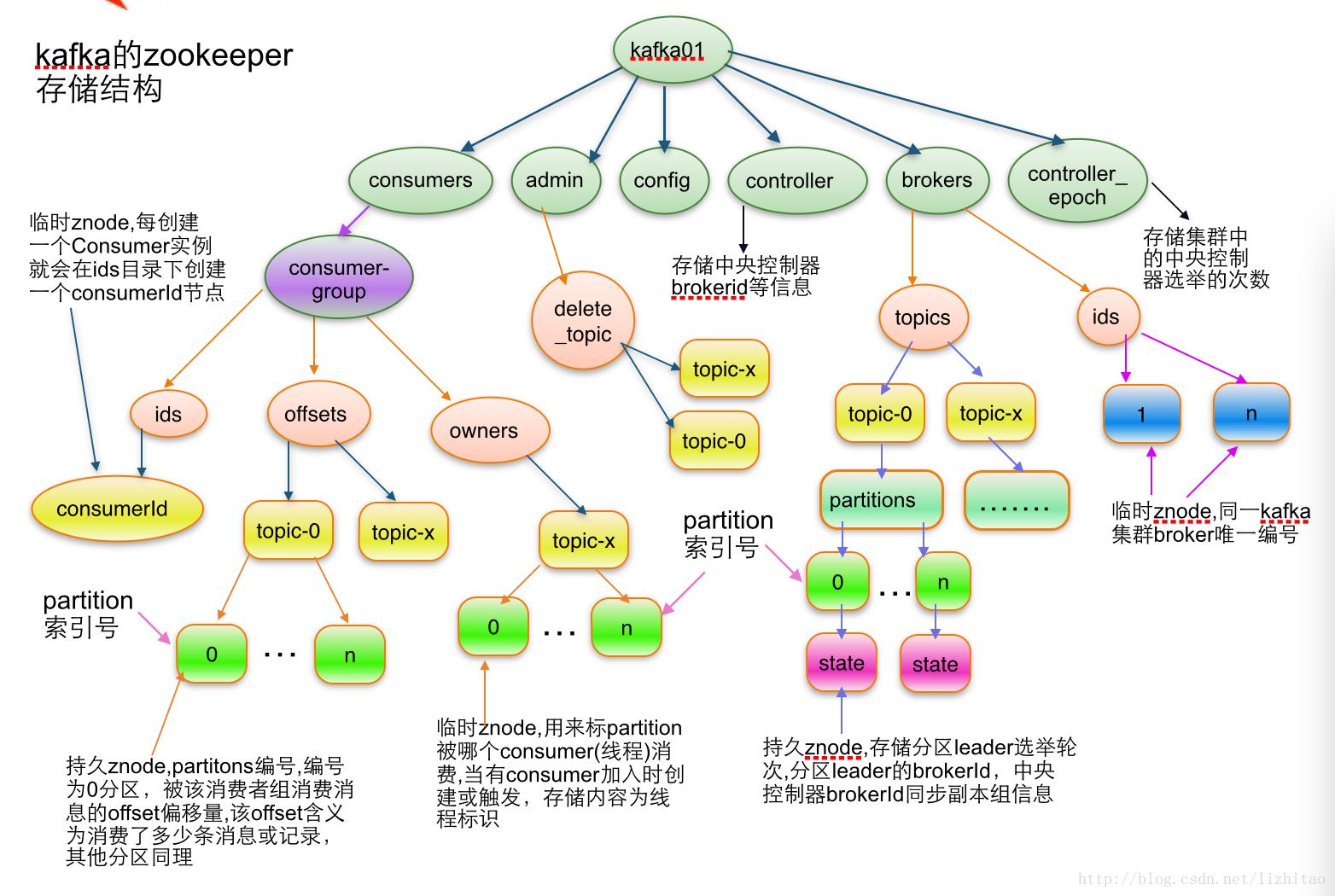
每个Broker服务器在启动时,都会到Zookeeper上进行注册,即创建/brokers/ids/[0-N]的节点,然后写入IP,端口等信息,Broker创建的是临时节点,所有一旦Broker上线或者下线,对应Broker节点也就被删除了,因此我们可以通过zookeeper上Broker节点的变化来动态表征Broker服务器的可用性,Kafka的Topic也类似于这种方式。
Kakfa Broker Leader的选举:
前提是整个kafka集群连接同一套zookeeper, Kakfa Broker集群受Zookeeper管理。所有的Kafka Broker节点一起去Zookeeper上注册一个临时节点,因为只有一个Kafka Broker会注册成功,其他的都会失败,所以这个成功在Zookeeper上注册临时节点的这个Kafka Broker会成为Kafka Broker Controller,其他的Kafka broker叫Kafka Broker follower。(这个过程叫Controller在ZooKeeper注册Watch)。这个Controller会监听其他的Kafka Broker的所有信息,如果这个kafka broker controller宕机了,在zookeeper上面的那个临时节点就会消失,此时所有的kafka broker又会一起去 Zookeeper上注册一个临时节点,因为只有一个Kafka Broker会注册成功,其他的都会失败,所以这个成功在Zookeeper上注册临时节点的这个Kafka Broker会成为Kafka Broker Controller,其他的Kafka broker叫Kafka Broker follower 。例如:一旦有一个broker宕机了,这个kafka broker controller会读取该宕机broker上所有的partition在zookeeper上的状态,并选取ISR列表中的一个replica作为partition leader(如果ISR列表中的replica全挂,选一个幸存的replica作为leader; 如果该partition的所有的replica都宕机了,则将新的leader设置为-1,等待恢复,等待ISR中的任一个Replica“活”过来,并且选它作为Leader;或选择第一个“活”过来的Replica(不一定是ISR中的)作为Leader),这个broker宕机的事情,kafka controller也会通知zookeeper,zookeeper就会通知其他的kafka broker。
消费者生产者负载均衡
生产者需要将消息合理的发送到分布式Broker上,这就面临如何进行生产者负载均衡问题。
对于生产者的负载均衡,Kafka支持传统的4层负载均衡,zookeeper同时也支持zookeeper方式来实现负载均衡。
(1)传统的4层负载均衡
根据生产者的IP地址和端口来为其定一个相关联的Broker,通常一个生产者只会对应单个Broker,只需要维护单个TCP链接。这样的方案有很多弊端,因为在系统实际运行过程中,每个生产者生成的消息量,以及每个Broker的消息存储量都不一样,那么会导致不同的Broker接收到的消息量非常不均匀,而且生产者也无法感知Broker的新增与删除。
(2)使用zookeeper进行负载均衡
很简单,生产者通过监听zookeeper上Broker节点感知Broker,Topic的状态,变更,来实现动态负载均衡机制,当然这个机制Kafka已经结合zookeeper实现了。
4.记录消息分区于消费者的关系,都是通过创建修改zookeeper上相应的节点实现,而且还会记录消息消费进度Offset记录,都是通过创建修改zookeeper上相应的节点实现。
kafka日志数据分离操作
原因:kafka中的数据存储配置字段为logs.dir,容易让人误解为日志,事实上kafka的日志和数据都是存在/kafka/logs下的,需要手动进行分离,但并非一定要分离,看个人爱好
- 删除kafka集群下kafka/logs文件夹
- 删除zk集群下的zookeeper/zkData中的version文件
数据分离后创建一个分区数何副本数都为2的topic first,那么/kafka-data下会生成first-0和first-1两份数据文件分别代表first两个分区的文件,另外的两个副本分别在其它位置,这里起到了数据库的作用,在一段时间内存储数据 => 主题是逻辑上的,分区时物理上的
kafka的每个分区数据如果不加以控制就会无限堆积,所以kafka的分区存在分片机制即每超过1g就进行分片segement,每个分片单独具有一个log和一个index,log是实实在在存储数据的,index可以看着是log的索引
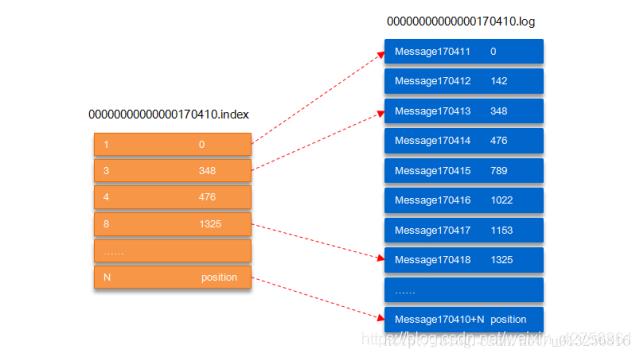
00000000000000170410.log这个文件记录了第170411到~(下一个log文件编号)的消息。
00000000000000170410.index:假设这个消息中有N条消息,第3条消息在index文件中对应的是348,也就是说在log文件中,第3条消息的偏移量为348。
以上是关于zookeeper和Kafka的关系的主要内容,如果未能解决你的问题,请参考以下文章
Apache Kafka 删除 Apache ZooKeeper 的依赖
CLOUD 04:zookeeper,kafka,hadoop高可用