Python安全编程
Posted Wαff1ε
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python安全编程相关的知识,希望对你有一定的参考价值。
目录
一、Python黑客领域的现状
基于Python的平台:Seebug、TangScan、BugScan等 ;
Python程序的广度:进行蜜罐部署、WIFI中间人、快速把网页内容转pdf文档脚本等(我们可以利用python开发出方方面面的程序);
python的深度:sqlmap注入神器、中间人攻击神器mitmproxy/mitmdump等;
Python是跨平台的!
为什么选择python:
简单易学、免费开源、高级语言、可移植、可扩展、可嵌入、丰富的扩展库
学习基础:
掌握python基础知识(《python核心编程》),了解http协议、熟练使用BurpSuite,Sqlmap等工具
能学到什么:
python较为高级的用法;爬虫的开发,多线程,网络编程,数据库编程; Python hacker的应用;开发扫描器,爆破器,POC脚本
python就是一个能快速实现我们想法的编程语言!
python可以帮助我们做什么?
我们需要掌握:python正则表达式、python web编程、python多线程编程、python网络编程、python数据库编程(排列组合就可以写出很多有用的小工具哦!)
目录扫描:
Web+多线程{requests+threading+Queue:[后台 | 敏感文件(syn|upload)| 敏感目录(phpmyadmin)]}
信息收集:
Web+数据库{中间件(Tomcat|Jobss)+ C段WEB信息+ 搜集特定程序}
信息匹配&SQL注入:
Web+正则{抓取信息(用户名| 邮箱?)+SQL注入}
反弹Shell:
python网络编程
python在网络安全中的应用知识串讲:
1、选择一款自己使用舒服编辑器:我使用的是sublime text
2、至少看一本关于python的书籍
3、学会使用python自带的功能,学习阅读源代码(base64模块等)
4、阅读官方文档(docs.python.org)
5、多练习,刻意联系
如何在sublime上运行python:
C:\\Python27
C:\\Users\\mi\\AppData\\Local\\Programs\\Python\\Python36
import base64
#print dir(base64)
#print help(base64)
#print base64.__file__ #返回文件所在位置:C:\\Python27\\lib\\base64.pyc
#打开 C:\\Python27\\lib\\base64.pyc查看
-------------------------------------------------------------------------------------------
print base64.b64encode('waffle') #base64编码二、Python正则表达式
2.1 正则表达式的介绍
使用单个字符串来描述、匹配一系列符合某个句法规则的字符串,简单理解就是对字符串的检索匹配和处理。
2.2 正则表达式使用方法
Python通过re模块提供对正则表达式的支持。
①先将正则表达式的字符串形式编译为Pattern实例;
②使用Pattern实例处理文本并获得匹配结果;
③使用实例获得信息,进行其他的操作。

函数:
1、re.compile('佟丽娅') 编译
2、pattern.match(msg) 只要头没有匹配成功就返回None
3、re.search('佟丽娅',s) # search进行正则字符串匹配方法,匹配的是整个字符串
print(result) # <_sre.SRE_Match object; span=(2, 5), match='佟丽娅'> match是匹配的内容部分
print(result.span()) # 返回位置 (2, 5)
4、result.group() # 佟丽娅 使用group来提取到匹配的内容部分
5、re.findall('[a-z][0-9][a-z]',msg) # findall 匹配整个字符串,会找完所有的匹配的才会停止,一直到结尾
6、sub (类似replace) 将匹配的数据进行替换
sub(正则表达式,'新内容',string) 返回的结果就是替换后的结果
7、split 切割
result=re.split(r'[,:]','java:99,python:95') 在字符串中搜索,如果遇到冒号或逗号就分割一下,将分割内容保存到列表中实例:
>>> import re
>>> pattern=re.compile('hello')
>>> match=pattern.match('hello world!')
>>> print(match)
<_sre.SRE_Match object; span=(0, 5), match='hello'>
>>> print(match.group())
hello
>>>
---------------------------------------------------
实际情况下,我们可以将第一步和第二步合并
>>> word=re.findall('hello','hello world!')
>>> word
['hello']
>>>
---------------------------------------------------
>>> word='http://www.ichunqiu.com python_1.1'
>>> key=re.findall('h.',word) # .是匹配除换行外的所有字符
>>> key
['ht', 'hu', 'ho']
>>> key=re.findall('\\.',word) # \\是转义字符
>>> key
['.', '.', '.']
# [...]表示字符集,对应的位置可以是字符集中任意字符[abc]或[a-c],第一个字符是^表示取反,如[^abc],所有特殊字符在字符集都失去原有的特殊含义。在字符集中如果要使用、-或者^,可以在前面加上反斜杠。基础知识:
python re模块:提供正则
预定义字符集(可以写在[...]中):
\\A:表示从字符串的开始处匹配
\\Z:表示从字符串的结束处匹配,如果存在换行,只匹配到换行前的结束字符串。
\\b:匹配一个单词边界,也就是指单词和空格间的位置。例如, 'py\\b' 可以匹配"python" 中的 'py',但不能匹配 "openpyxl" 中的 'py'。
\\B:匹配非单词边界。 'py\\b' 可以匹配"openpyxl" 中的 'py',但不能匹配"python" 中的 'py'。
\\d:匹配任意数字,等价于 [0-9]。 digit
\\D:匹配任意非数字字符,等价于 [^\\d]。not digit
\\s:匹配任意空白字符,等价于 [\\t\\n\\r\\f]。 space
\\S:匹配任意非空白字符,等价于 [^\\s]。
\\w:匹配任意字母数字及下划线,等价于[a-zA-Z0-9_]。
\\W:匹配任意非字母数字及下划线,等价于[^\\w]
\\\\:匹配原义的反斜杠\\。
-----------------------------------------------------------------------------------------
字符:
‘.’用于匹配除换行符(\\n)之外的所有字符。
‘^’用于匹配字符串的开始,即行首。
‘$’用于匹配字符串的末尾(末尾如果有换行符\\n,就匹配\\n前面的那个字符),即行尾。
-----------------------------------------------------------------------------------------
定义正则验证次数(数量词):
‘*’用于将前面的模式匹配0次或多次(贪婪模式,即尽可能多的匹配) >=0
‘+’用于将前面的模式匹配1次或多次(贪婪模式) >=1
‘?’用于将前面的模式匹配0次或1次(贪婪模式) 0 ,1
'{m}' 用于验证将前面的模式匹配m次
'{m,}'用于验证将前面的模式匹配m次或者多次 >=m
'{m,n}' 用于验证将前面的模式匹配大于等于m次并且小于等于n次
-----------------------------------------------------------------------------------------
‘*?,+?,??’即上面三种特殊字符的非贪婪模式(尽可能少的匹配)。
‘{m,n}’用于将前面的模式匹配m次到n次(贪婪模式),即最小匹配m次,最大匹配n次。
‘{m,n}?’即上面‘{m,n}’的非贪婪版本。
-----------------------------------------------------------------------------------------
逻辑、分组:
| : 代表左右表达式任意匹配一个,它总是先尝试匹配左边的表达式,一旦成功匹配则跳过右边的表达式,如果|没有包括在()中,则它的范围是整个正则表达式。
(...): 被括起来的表达式将作为分组,从表达式左边开始,每遇到一个分组的左括号,编号+1,分组表达式作为一个整体,可以后接数量词。表达式中|仅在该组中有效。
(abc){2} ---->abcabc
a(123|456)c ----> a456c 或者 a123c
-----------------------------------------------------------------------------------------
‘\\\\’:'\\'是转义字符,在特殊字符前面加上\\,特殊字符就失去了其所代表的含义,比如\\+就仅仅代表加号+本身。
‘[]’用于标示一组字符,如果^是第一个字符,则标示的是一个补集。比如[0-9]表示所有的数字,[^0-9]表示除了数字外的字符。
‘|’比如A|B用于匹配A或B。
‘(...)’用于匹配括号中的模式,可以在字符串中检索或匹配我们所需要的内容。
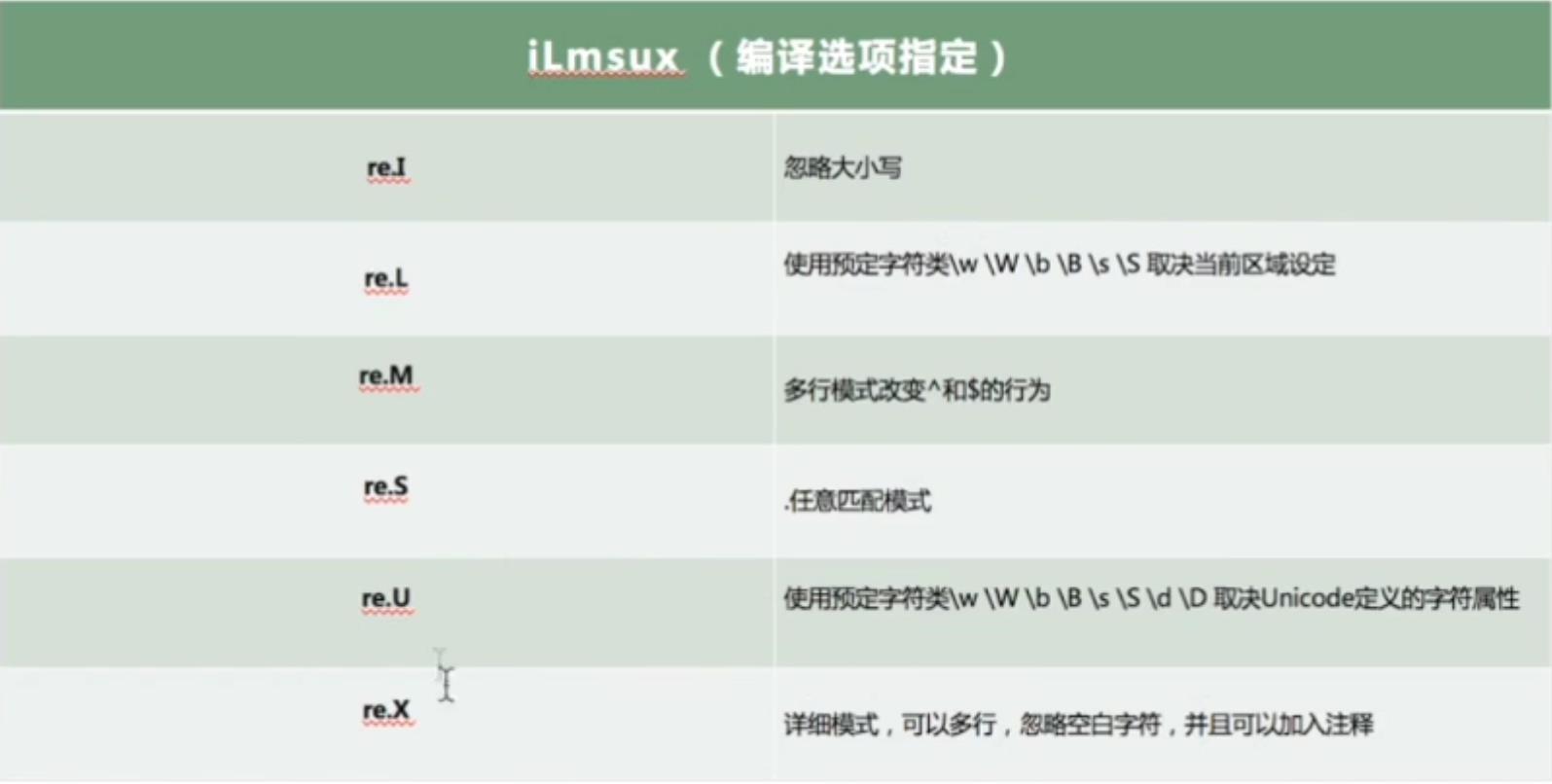
2.3 贪婪模式和非贪婪模式
Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;
非贪婪则相反,总是尝试匹配尽可能少的字符。
在"*","?","+","{m,n}"后面加上?,使贪婪变成非贪婪。

实战:提取i春秋官网课程名字


#coding=utf-8
import re
html='''
网页的HTML代码(观察课程名称附近代码,找出相似点)
'''
title=re.findall(r'<p class="coursename" title="(.*?)" onclick',html)
for i in title:
print i

三、Python Web编程
这里的web编程并不是利用python开发web程序,而是指利用python与web进行交互,获取web信息。
无论是哪种语言与web进行交互,获取web信息,都是黑客必备的一项技能
3.1 urllib、urllib2、requests
urllib、urllib2是python自带的两个web编程相关的库,他们长相相似,使用方法也有很大的相同,都是利用urlopen这个方法对对象发起请求
3.1.1 urllib
1、urllib.urlopen()
2、urllib.urlretrieve() [retrieve:取回;找回;检索数据]
urlretrieve(url,filename=None,reporthook=None,data=None)
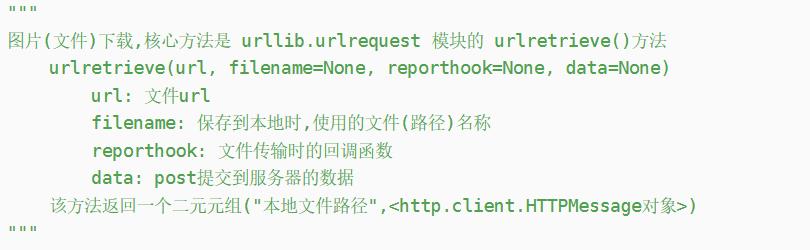
例如下载百度图片:https://www.baidu.com/img/bd_logo1.png
{kind=link}
>>> import urllib,urllib2
>>> urllib.urlretrieve('https://www.baidu.com/img/bd_logo1.png',filename='/tmp/baidu.png')
('/tmp/baidu.png', <httplib.HTTPMessage instance at 0x7fb477c2d1e0>)
>>>3.1.2 urllib2
1、urllib2.urlopen()
2、urllib2.Requests()
注:urllib和urllib2虽然虽然长的十分类似,但是他们是不可以相互代替的,他们都有各自独一无二的方法。其中最主要的两点:
urllib2有requests方法,它用来定制请求头
urllib有urlretrieve方法,它用来下载文件
举例:
>>> import urllib,urllib2
>>> url='http://www.baidu.com'
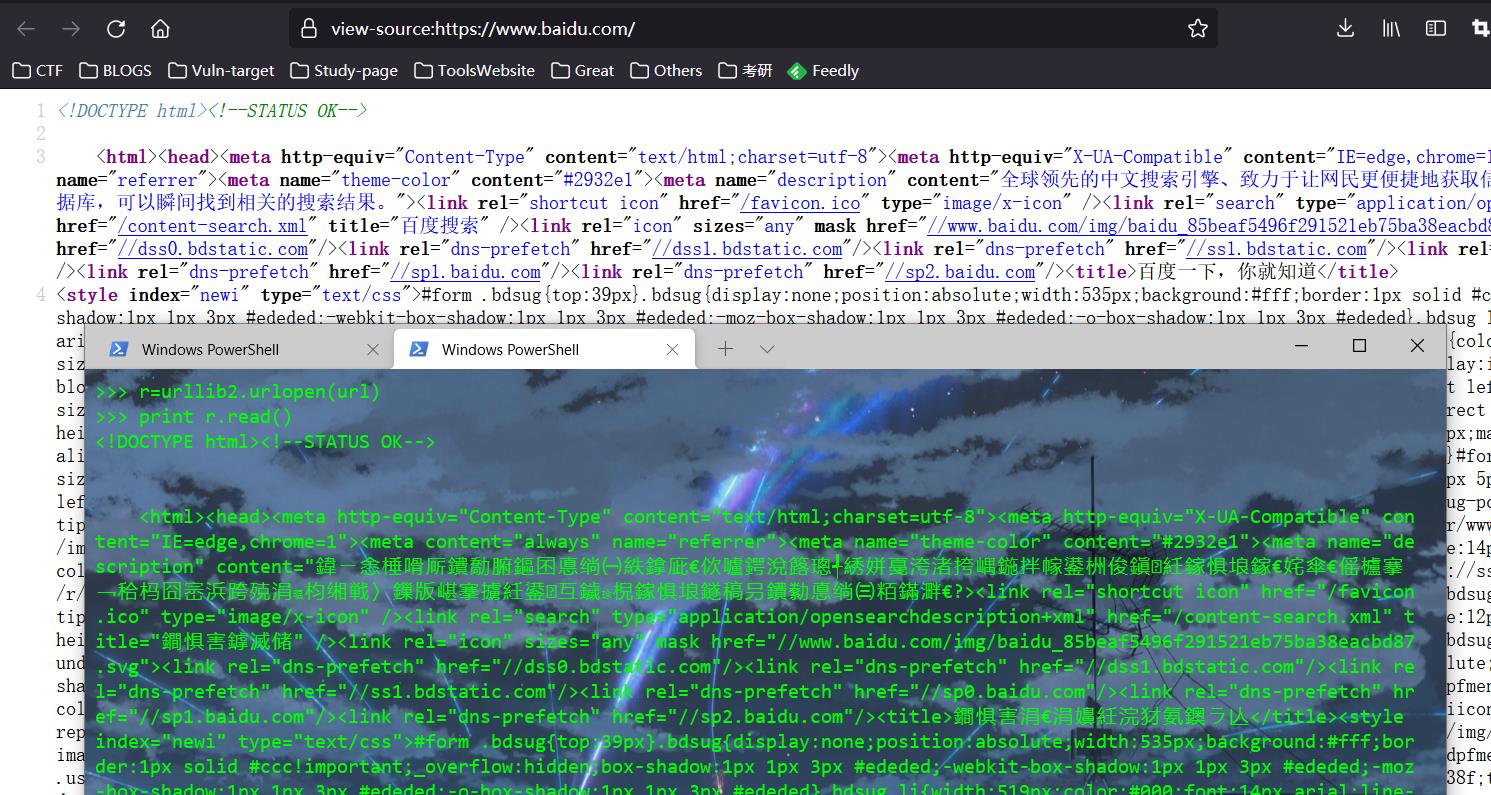
>>> r=urllib.urlopen(url) # 用urllib向百度这个地址发起请求
>>> print r.read() # 查看请求之后返回的内容、
----------------------------------------------
>>> r=urllib2.urlopen(url) #使用urllib2也能返回同样的内容
>>> print r.read()浏览器向百度发送请求后查看网页源代码:
3.1.3 requests
requests是第三方库,需要自己安装


>>> import requests
>>> r=requests.get('https://www.baidu.com')
>>> print r.text #返回响应内容
>>> print r.content #返回二进制的响应内容
>>> print r.status_code #返回状态码
200
>>> print r.headers #返回请求头
>>> print r.cookies #返回cookies
<RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
>>> r=requests.get('https://www.baidu.com',timeout=0.1) # 设置超时(在爬虫中有用)3.2 爬虫的介绍
网络爬虫(又被称为网页蜘蛛,网络机器人,更经常的称为网页追逐者),是一种按照一定规则,自动的抓取万维网信息的程序或者脚本。(各大搜索引擎说白了就是一个大的爬虫)
用爬虫最大的好处是批量且自动化的获取和处理信息。对于宏观或者微观的情况都可以多一个侧面去了解。
黑客使用爬虫,最常见的就是我们可以进行目录扫描,搜索测试页面,手册文档,搜索管理员的登录界面等。我们可以利用爬虫开发web的漏洞扫描,像绿盟的漏扫。
3.3 利用python开发一个爬虫
实例:用爬虫获取ichunqiu网站课程的名称
我们依次访问i春秋网站第1,2,3页面,用burpsuite抓取
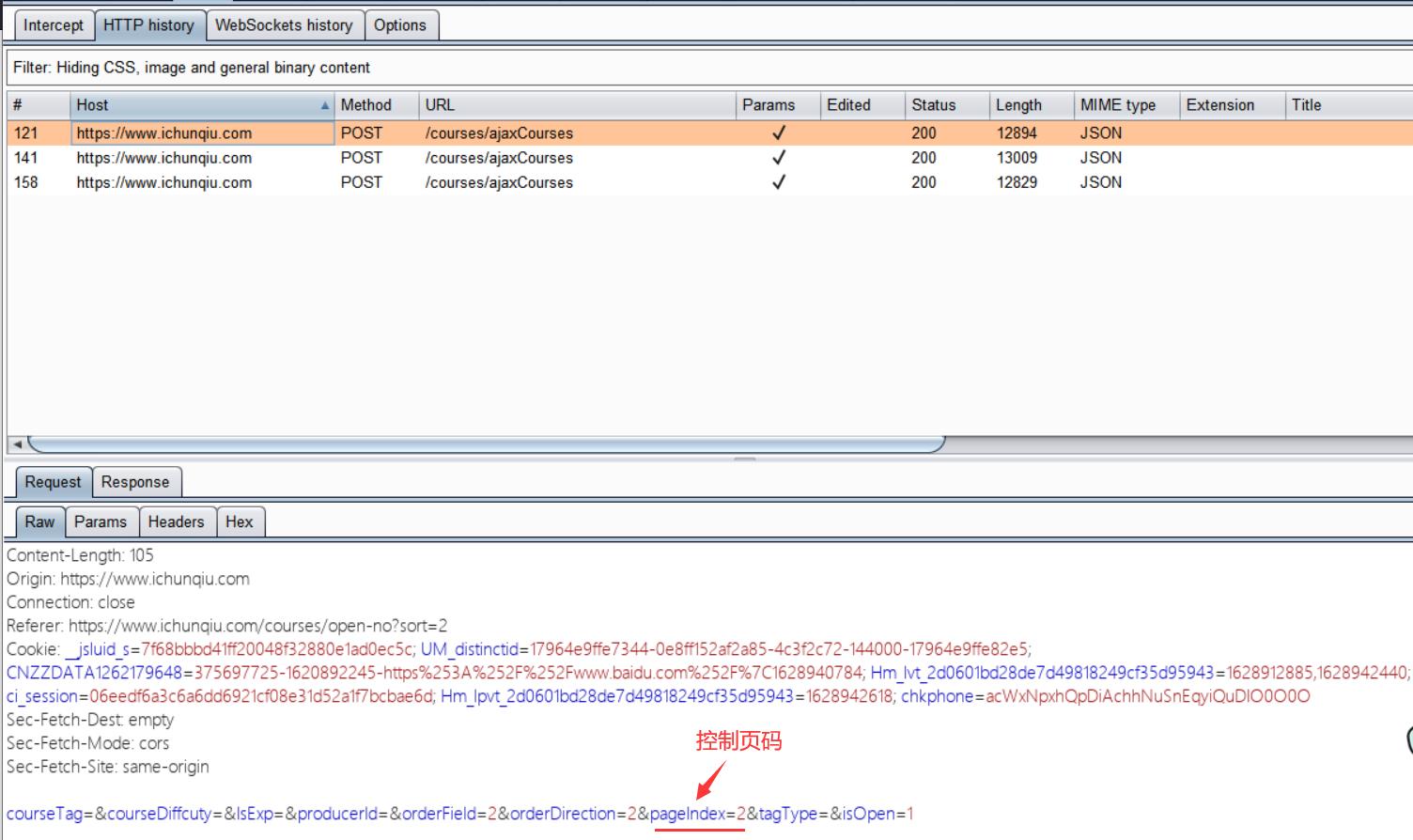
我们看看用python如何爬下这些课程内容,我们以第一页为例:
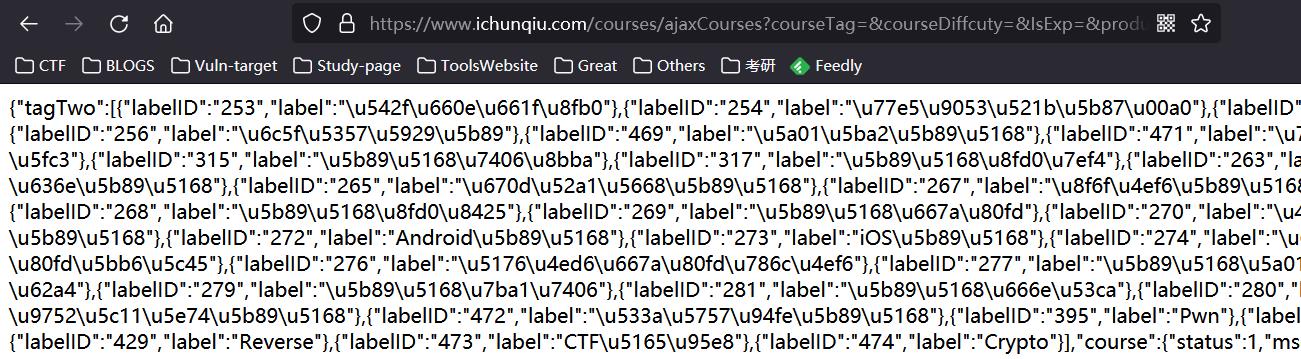
返回内容和python运行结果不一致,把header加上:
#coding=utf-8
import requests
#import re #用不到
import json
url='https://www.ichunqiu.com/courses/ajaxCourses?courseTag=&courseDiffcuty=&IsExp=&producerId=&orderField=2&orderDirection=2&pageIndex=1&tagType=&isOpen=1'
headers={
'Host': 'www.ichunqiu.com', #注意要加单引号和逗号分隔!
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:90.0) Gecko/20100101 Firefox/90.0',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With':'XMLHttpRequest',
'Referer': 'https://www.ichunqiu.com/courses/open-no?sort=2'
} #有防爬机制的网站都可以这样处理
r=requests.get(url=url,headers=headers) #给网站发起请求
print(r.text)
data=json.loads(r.text)
name_long=len(data['result'])
#print data['result'][0]['courseName']
for i in range(name_long):
print data['result'][i]['courseName']我们知道这些数据是通过json返回的,键值如下:


上面我们只获取了一页的课程名称,如果我们要获取所有课程怎么做呢?
演示:
#coding=utf-8
import requests
import json
#url='https://www.ichunqiu.com/courses/ajaxCourses?courseTag=&courseDiffcuty=&IsExp=&producerId=&orderField=2&orderDirection=2&pageIndex=1&tagType=&isOpen=1'
url_start='https://www.ichunqiu.com/courses/ajaxCourses?courseTag=&pageIndex='
def lesson(url):
headers={
'Host': 'www.ichunqiu.com',
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:90.0) Gecko/20100101 Firefox/90.0',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With':'XMLHttpRequest',
'Referer': 'https://www.ichunqiu.com/courses/open-no?sort=2'
} #有防爬机制的网站都可以这样处理
r=requests.get(url=url,headers=headers) #给网站发起请求
print(r.text)
data=json.loads(r.text)
# json.load()是用来读取文件的,即,将文件打开然后就可以直接读取
# json.loads()是用来读取字符串的,即,可以把文件打开,用readline()读取一行,然后json.loads()一行。
name_long=len(data['result'])
#print data['result'][0]['courseName']
for i in range(name_long):
print data['result'][i]['courseName']
for i in range(1,9): #有8页
url=url_start+str(i)+'courseDiffcuty=&IsExp=&producerId=&orderField=2&orderDirection=2&tagType=&isOpen=1'
lesson(url)上面代码就可以获得i春秋网站所有课程名称!
练习网站:
爬虫萌新:http://www.heibanke.com/lesson/crawler_ex00/
爬虫熟手:http://glidedsky.com/
全年龄段的爬虫爱好者:http://www.pythonchallenge.com/(脑洞)
四、Python 多线程
4.1 线程和进程
4.1.1 线程和进程介绍
进程:进程是程序的一次执行。每个进程都有自己的地址空间、内存、数据栈及其他记录其运行轨迹的辅助数据。(程序就是磁盘中可执行的一些数据,只他们运行了,他们才被赋予了生命),每一个进程之间是相互独立的,他们通过一些协议才可以相互访问,如果说一个进程能访问到超过自己分配内存的区域,也就产生了溢出。
线程:所有的线程运行在一个进程当中,共享相同的运行环境。线程有开始顺序执行和结束三个部分。进程包括了线程,许多线程结合在一起,辅助协同工作,从而完成进程分配给他们的任务。

在python使用多进程的时候,一定是要有多核CPU的支持,但是python的多进程对windows系统支持并不是很好,所以我们往往使用多线程来加速我们的处理。
多线程是python程序实现多任务的一种方式,线程是程序执行的最小单位。同属一个进程的多个线程共享进程所拥有的全部资源。
4.1.2 线程的创建步骤
1、导入线程模块 import threading
2、通过线程类创建线程对象
线程对象 = threading.Thread(target=任务名)
3、启动线程对象:线程对象.start()
4.1.3 通过线程类创建线程对象
线程对象 = threading.Thread(target=任务名)
| 参数名 | 说明 |
| target | 执行的目标任务名,这里指的是函数名(方法名) |
| name | 线程名,一般不用设置(创建线程时自己取的名字) |
| group | 线程组,目前只能使用None |
4.1.4 线程创建与启动的代码
使用单任务:
#!/usr/bin/env python
# coding=utf-8
import time
def sing():
for i in range(3):
print "唱歌..."
time.sleep(1)
def dance():
for i in range(3):
print "跳舞..."
time.sleep(1)
# 下面用单任务执行一下
if __name__ == '__main__':
sing()
dance()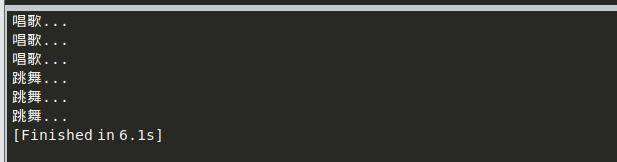
使用多任务改进: (提高效率)
#!/usr/bin/env python
# coding=utf-8
import time
import threading
def sing():
for i in range(3):
print "唱歌..."
time.sleep(1)
def dance():
for i in range(3):
print "跳舞..."
time.sleep(1)
# 下面用多任务执行一下
if __name__ == '__main__':
# 创建线程对象,并且希望他启动之后执行唱歌的函数
sing_thread=threading.Thread(target=sing)
#创建线程对象,并且希望他启动之后执行跳舞的函数
dance_thread=threading.Thread(target=dance)
# 启动线程
sing_thread.start()
dance_thread.start()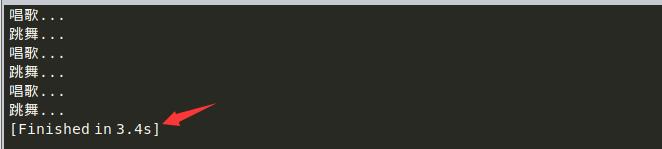
4.1.5 多线程完成多任务总结
- 导入线程模块:import threading
- 创建子进程并指定执行任务:sub_thread=threading.Thread(target=任务名)
- 启动线程执行任务:sub_thread.start()
4.2 thread模块
start_new_thread(function,args kwargs=None) //派生一个新的线程,给定agrs和kwargs来执行function
thread.start_new_thread ( function, args[, kwargs] )
参数说明:
该方法的第一个参数 function 表示要执行的函数,如上面定义的函数名,该函数将作为线程的入口函数使用。args 和kwargs是该函数的参数,args是必须的,类型是元组;kwargs是可选的,类型是字典。
产生一个新的线程,在新的线程中用指定的参数和可选的kwargs来调用这个函数
注意:使用这种方法的时候,一定要加time.sleep(),否则每个线程将可能不执行。
此方法还有一个缺点,遇到较复杂问题的时候,线程数不易控制。
#coding=utf-8
import thread
import time
def func1():
print "hello world! %s"%time.ctime()
# 当我们要使用多线程的方法让函数多次运行:
def main():
thread.start_new_thread(func1,())
thread.start_new_thread(func1,())
time.sleep(2)
if __name__== '__main__':
main()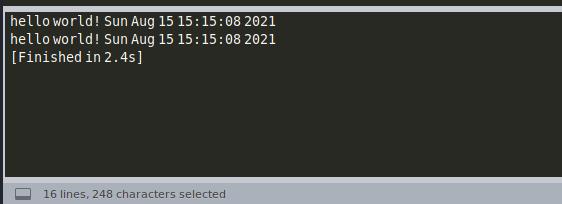
现在要对所有C段的机器进行探测,看它是否存活:
#coding=utf-8
#现在要对所有C段的机器进行探测,看它是否存活:
import thread
import time
from subprocess import Popen,PIPE #用这个模块来执行系统命令
def ping_check(ip):
check=Popen(['/bin/bash','-c','ping -c 2 '+ip],stdin=PIPE,stdout=PIPE)
data = check.stdout.read()
if 'ttl' in data:
print '%s is UP'% ip
# popen 打开进程文件指针
#pipe管道的意思 subprocess子进程
#stdout 标准输出
# stdin 标准输入
def main():
for i in range(1,255):
ip='116.211.155.'+str(i) # 1-254
thread.start_new_thread(ping_check,(ip,))
time.sleep(0.1)
if __name__== '__main__': #调用主函数
main()4.3 threading模块
4.3.1 Thread类
a)使用threading模块
b)子类化Thread类
解决了线程数可控的问题!
#coding=utf-8
import threading
import time
def fun1(key):
print "hello %s:%s"%(key,time.ctime()) #time.ctime打印当前时间
def main():
threads=[]
keys=['zhangsan','lisi','wangmazi']
threads_count=len(keys)
for i in range(threads_count): # 检查脚本的名称是threading.py,怀疑是与模块名称冲突,导致加载错误,换一个名字
t=threading.Thread(target=fun1,args=(keys[i],)) # 第一个参数是线程函数变量,第二个参数args是一个数组变量参数,如果只传递一个值,就只需要i, 如果需要传递多个参数,那么还可以继续传递下去其他的参数,其中的逗号不能少,少了就不是数组了,就会出错
threads.append(t)
for i in range(threads_count):
threads[i].start() # 告诉操作系统开一个线程
for i in range(threads_count):
threads[i].join() # Thread 的 join() 方法,可以阻塞自身所在的线程
if __name__== '__main__': #调用主函数
main()

想在很短的时间内访问baidu:
#coding=utf-8
import threading
import time
import requests
import sys
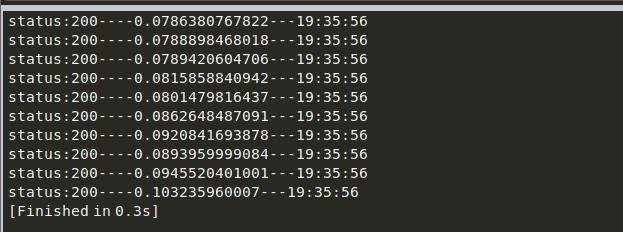
def fun1():
time_start=time.time() #访问百度的时间 time.time()返回当前时间的时间戳(1970纪元后经过的浮点秒数)。
r=requests.get(url='http://www.baidu.com')
times=time.time()-time_start # 计算出所有的访问时间
sys.stdout.write('status:%s----%s---%s\\n'%(r.status_code,times,time.strftime('%H:%M:%S'))) # 打印状态码、访问时间,当地时间
def main():
threads=[]
threads_count=10 # 定义线程数 10 同时对baidu访问十次,打印他返回的一些数据
for i in range(threads_count): # 检查脚本的名称是threading.py,怀疑是与模块名称冲突,导致加载错误,换一个名字
t=threading.Thread(target=fun1,args=()) # 第一个参数是线程函数变量,第二个参数args是一个数组变量参数,如果只传递一个值,就只需要i, 如果需要传递多个参数,那么还可以继续传递下去其他的参数,其中的逗号不能少,少了就不是数组了,就会出错
threads.append(t)
for i in range(threads_count):
threads[i].start() # 告诉操作系统开一个线程
for i in range(threads_count):
threads[i].join() # Thread 的 join() 方法,可以阻塞自身所在的线程
if __name__== '__main__': #调用主函数
main()
4.3.2 生产者 - 消费者问题和Queue模块
a)Queue模块( qsize(), empty(), full(), put(), get() )
b) 完美搭档,Queue + Thread
解决了生产参数和计算结果时间都不确定的问题!

案例:多线程对C段进行ping检测
#coding=utf-8
import threading
import Queue
from subprocess import Popen,PIPE
import sys
class DoRun(threading.Thread):
def __init__(self,queue):
threading.Thread.__init__(self)
self._queue=queue
def run(self):
while not self._queue.empty():
ip= self._queue.get()
print ip
check_ping=Popen(['/bin/bash','-c','ping -c 2 '+ip],stdin=PIPE,stdout=PIPE)
data = check_ping.stdout.read()
if 'ttl' in data:
sys.stdout.write(ip+ ' is UP\\n') # 使用sys以比较友好的方式对我们结果进行打印
def main():
threads=[]
threads_count=100
queue=Queue.Queue()
for i in range(1,255):
queue.put('116.211.155.'+str(i))
for i in range(threads_count):
threads.append(DoRun(queue))
for i in threads:
i.start()
for i in threads:
i.join()
if __name__== '__main__': #调用主函数
main()
练习:使用爬虫结合多线程的方式对ichunqiu,所有的课程进行爬取(http://www.ichunqiu.com/courses)
4.4 线程执行带有参数的任务
4.4.1 线程执行带有参数的任务
| 参数名 | 说明 |
| args | 以元祖的方式给执行任务传参 |
| kwargs | 以字典的方式给执行任务传参 |
4.4.2 args参数的使用
# target:线程执行的函数名
# args:表示以元祖方式给函数传参
sing_thread = threading.Thread(target=sing,args=(3,)) # 唱歌三次
sing_thread.start()4.4.3 kwargs参数使用
# target:线程执行的函数名
# kwargs:表示以字典方式给函数传参
dance_thread = threading.Thread(target=dance,kwargs={'count':3}) # 跳舞三次
# 开启线程
dance_thread.start()4.4.4 线程执行带有参数的任务代码演示
#!/usr/bin/env python
# coding=utf-8
import time
import threading
def sing(num,name):
for i in range(num):
print name,":唱歌..."
time.sleep(1)
def dance(count):
for i in range(count):
print "跳舞..."
time.sleep(1)
if __name__ == '__main__':
# args:以元组的方式给执行任务传递参数
sing_thread=threading.Thread(target=sing,args=(3,"xiaoming"))
#kwargs:以字典方式
dance_thread=threading.Thread(target=dance,kwargs={'count':2})
# 启动线程
sing_thread.start()
dance_thread.start()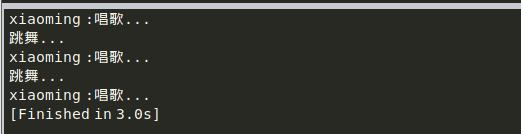
元祖方式传参要保证元素顺序和参数顺序一致,字典方式传参要保证key和参数名保持一致!
4.5 主线程和子线程的结束顺序
主线程会等待所有的子线程执行结束后主线程再结束。除非把它设置为守护主线程
#!/usr/bin/env python
# coding=utf-8
import time
import threading
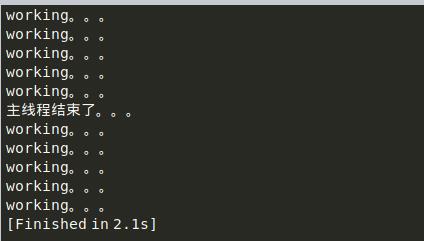
def work():
for i in range(10):
print "working。。。"
time.sleep(0.2)
if __name__ == '__main__':
sub_thread = threading.Thread(target=work)
sub_thread.start()
#主线程等待1s,后结束
time.sleep(1)
print "主线程结束了。。。"
# 结论: 主线程会等待所有的子线程结束后再结束
下面我希望主线程一结束,子线程就能自动销毁:
4.5.1 设置守护主线程
要想主线程不等待子线程执行完成可以设置守护主线程
#主线程结束时不想等待子线程结束再结束,可以设置子现场守护主线程
#1、threading.Thread(target=work,daemon=True)
#2、线程对象.setDaemon=True(setDaemon一定要在start之前)
#!/usr/bin/env python
# coding=utf-8
import time
import threading
# 设置守护主线程方式1: daemon=True 守护主线程
work_thread = threading.Thread(target=work,daemon=True)
# 设置主线程方式2
#work_thread.setDaemon(True)
work_thread.start()
# 主线程延时1s
time.sleep(1)
print "over!"五、Python 多进程
5.1 多任务介绍
5.1.1 电脑中的多任务:
5.1.2 多任务的优势:
多任务的最大好处是充分利用CPU资源,提高程序的执行效率。
多任务是指在同一时间内执行多个任务。
5.1.3 多任务的两种表现形式:
- 并发:在一段时间内交替去执行多个任务
例子:对于单核CPU处理多任务,操作系统轮流让各个任务交替执行。由于交替的速度非常快,所以我们认为他们一起在运行。
- 并行:在一段时间内真正同时一起执行多个任务。
例子:对于多核CPU处理多任务,操作系统会给CPU的每个内核安排一个执行的任务,多个内核是真正的一起同时执行多个任务。这里需要注意多核CPU是并行的执行多任务,始终有多个任务一起执行。(并行:任务数量小于或等于CPU的核心数)
5.2 进程的介绍
5.2.1 程序中实现多任务的方式
在python语言中,想要实现多任务可以使用多进程来完成。
5.2.2 进程的概念
进程是资源分配的最小单位,它是操作系统进行资源分配和调度运行的基本单位,通俗理解:一个正在运行的程序就是一个进程。例如:正在运行的QQ,微信等,他们都是一个进程。(一个没运行的程序就是一个程序),一个程序运行后至少有一个进程。
5.2.3 多进程的作用
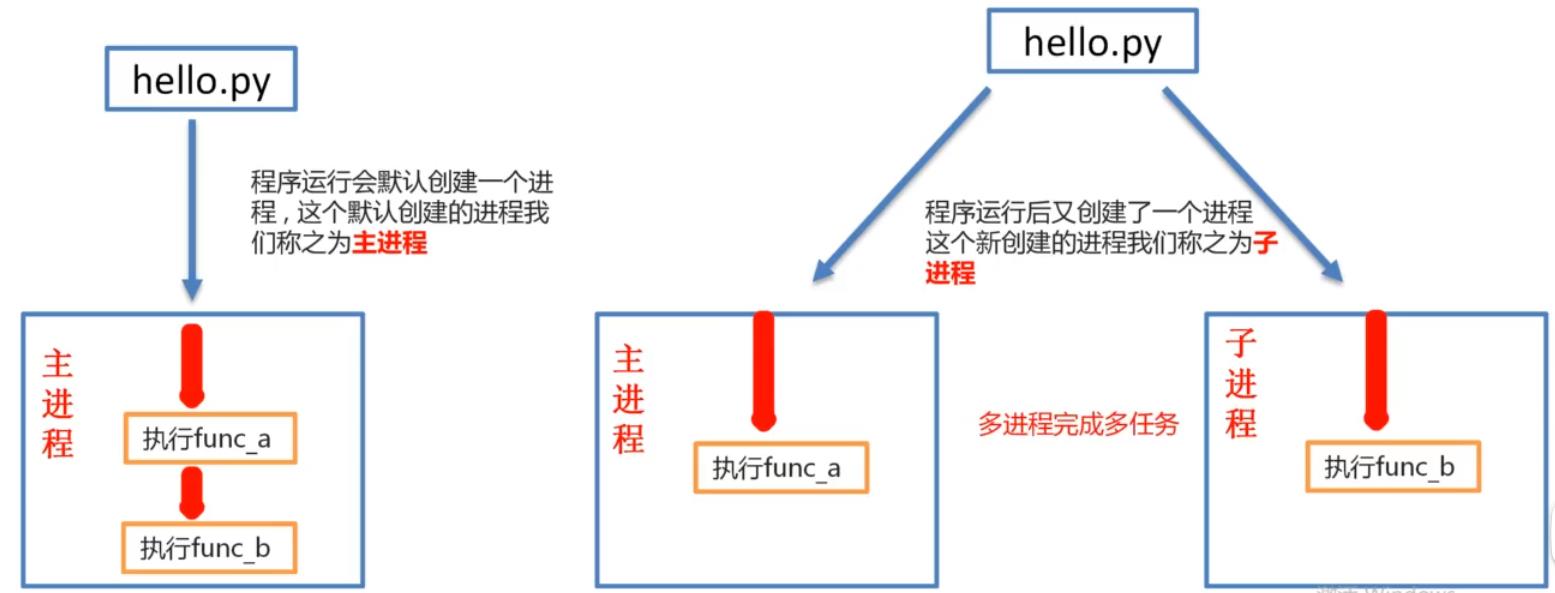
5.3 多进程完成多任务
5.3.1 进程的创建步骤
1、导入进程包:import multiprocessing
2、通过进程类创建进程对象:进程对象=multiprocessing.Process()
3、启动进程执行任务:进程对象.start()
5.3.2 通过进程类创建进程对象
进程对象=multiprocessing.Process(target=任务名)
| 参数名 | 说明 |
| target | 执行的目标任务名,这里指的是函数名(方法名) |
| name | 进程名,一般不用设置(系统会默认设置) |
| group | 进程组,目前只能使用None |
5.3.3 进程创建与启动的代码
# 创建子进程
sing_process = multiprocessing.Process(target=sing)
# 创建子进程
dance_process = multiprocessing.Process(target=dance)
#启动进程
sing_process.start()
dance_process.start()单任务:
import time
# 唱歌
def sing():
for i in range(3):
print "singing..."
time.sleep(0.5)
# 跳舞
def dance():
for i in range(3):
print "dancing..."
time.sleep(0.5)
if __name__='__main__':
sing()
dance()使用多进程实现多任务:
# 1、导入进程包
import time
import multiprocessing
# 唱歌
def sing():
for i in range(3):
print "singing..."
time.sleep(0.5)
# 跳舞
def dance():
for i in range(3):
print "dancing..."
time.sleep(0.5)
if __name__='__main__':
# 2、使用进程类创建进程对象
sing_process=multiprocessing.Process(target=sing)
dance_process=multiprocessing.Process(target=dance)
# 3、使用进程对象启动进程执行指定任务
sing_process.start()
dance_process.start()5.4 进程执行带有参数的任务
5.4.1 进程执行带有参数的任务
| 参数名 | 说明 |
| args | 以元祖的方式给执行任务传参 |
| kwargs | 以字典的方式给执行任务传参 |
通多线程操作一样,不再演示。
5.5 获取进程编号
进程编号的作用:
当程序中进程的数量越来越多的时候,如果没有办法区分主线程和子线程还有不同的子线程,那么就无法进行有效的进程管理,为了方便管理实际上每个进程都是有自己的编号的。
获取进程编号的两种方式:
1、获取当前进程编号
os.getpid()
2、获取当前父进程编号
os.getppid()
5.5.1 os.getpid()的使用
import os
pid=os.getpid()
print(pid)