Python数据分析-pandas-数据处理
Posted 小旺不正经
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python数据分析-pandas-数据处理相关的知识,希望对你有一定的参考价值。
插入数据
pandas模块没有专门提供插入行的方法
插入数据主要是指插入一列新的数据
方法一
以赋值的方式在数据表的最右侧插入列数据
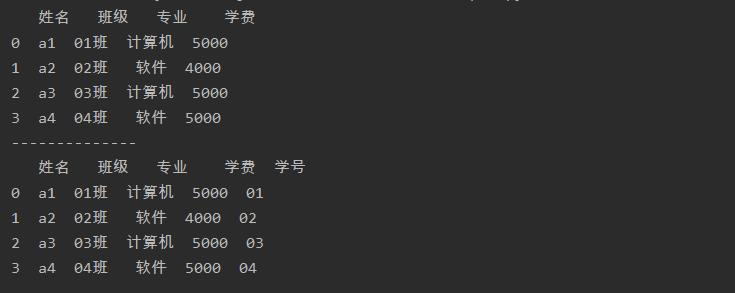
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a['学号'] = ['01','02','03','04']
print(a)
方法二
用insert()函数在数据表的指定位置插入列数据
第1个参数为插入列的位置;第2个参数为插入列的列标签;第3个参数以列表的形式给出插入列的数据。
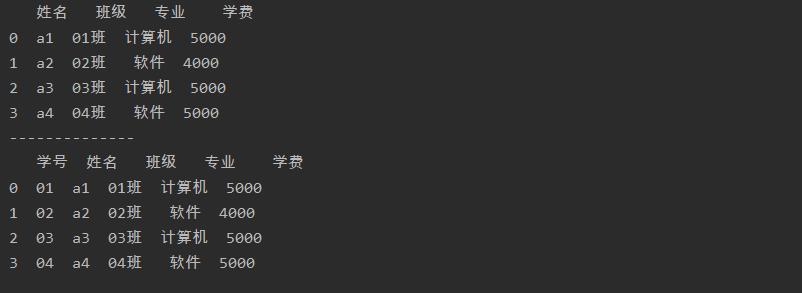
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a.insert(0,'学号',['01','02','03','04'])
print(a)
删除数据
删除列
drop()函数中直接给出要删除的列的列标签就可以删除列
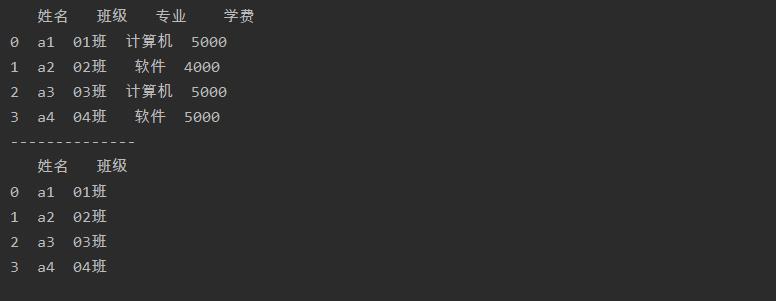
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a = a.drop(['专业','学费'],axis=1)
print(a)
 第1个参数以列表的形式给出要删除的行或列的标签;第2个参数axis用于设置按行删除还是按列删除,设置为0表示按行删除(即第1个参数中给出的标签是行标签),设置为1表示按列删除(即第1个参数中给出的标签是列标签)。
第1个参数以列表的形式给出要删除的行或列的标签;第2个参数axis用于设置按行删除还是按列删除,设置为0表示按行删除(即第1个参数中给出的标签是行标签),设置为1表示按列删除(即第1个参数中给出的标签是列标签)。
通过列序号来获取列标签,然后作为drop()函数的第1个参数使用
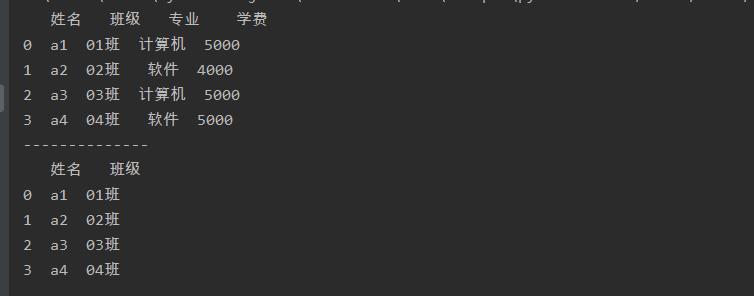
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a = a.drop(a.columns[[2,3]],axis=1)
print(a)
通过将列标签以列表的形式传递给drop()函数的参数columns来删除列
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a = a.drop(columns=['班级','专业'])
print(a)
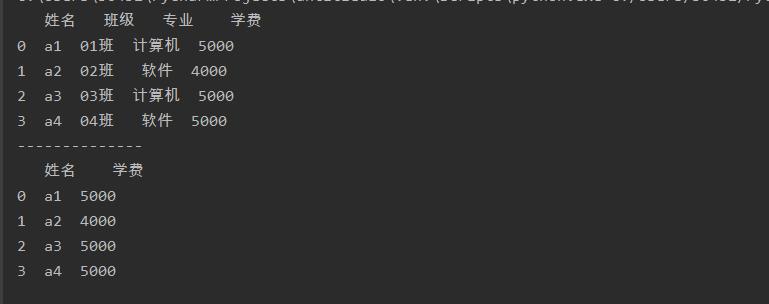
删除行
drop()函数,只不过需要将参数axis设置为0
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a = a.drop([0,1],axis=0)
print(a)
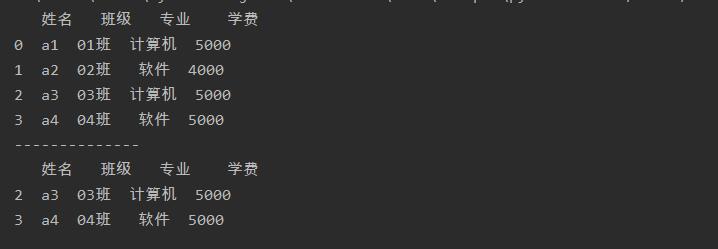
通过行序号来获取行标签
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a = a.drop(a.index[[0,3]],axis=0)
print(a)

处理缺失值
查看缺失值
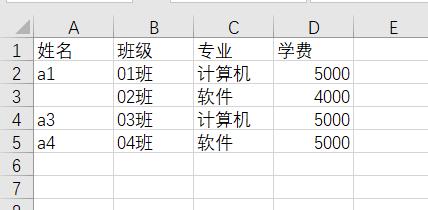
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)

查看每一列的缺失值情况
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
print(a.info())
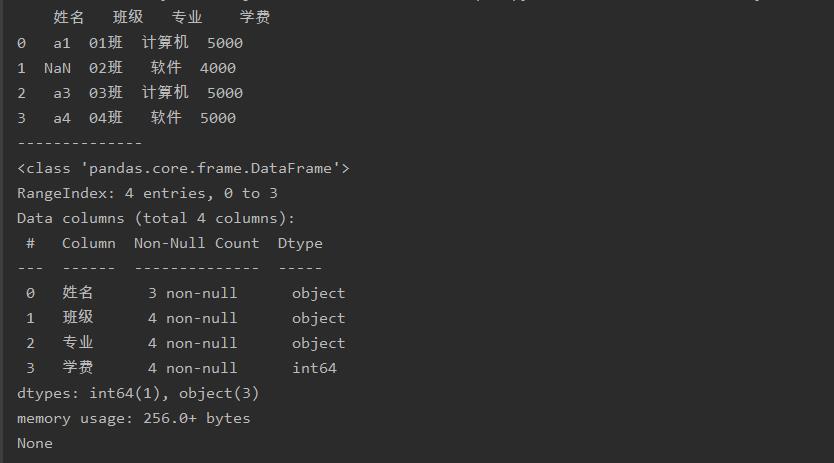
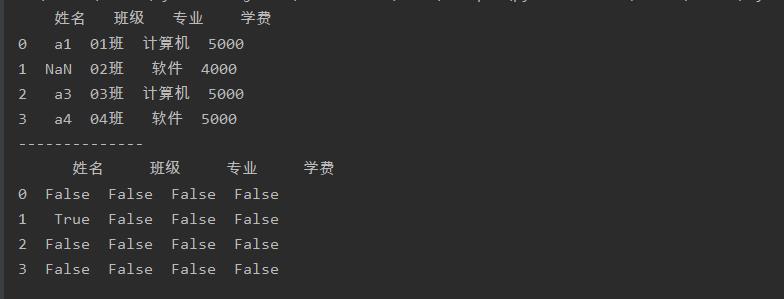
使用isnull()函数判断数据表中的哪个值是缺失值
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a = a.isnull()
print(a)
删除缺失值
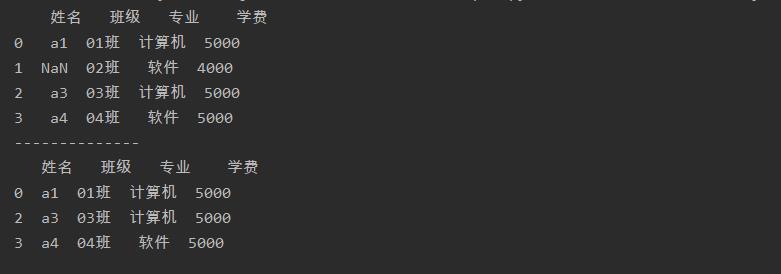
使用dropna()函数可以删除数据表中含有缺失值的行,默认只要某一行中有缺失值,该函数就把这一行删除
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a = a.dropna()
print(a)
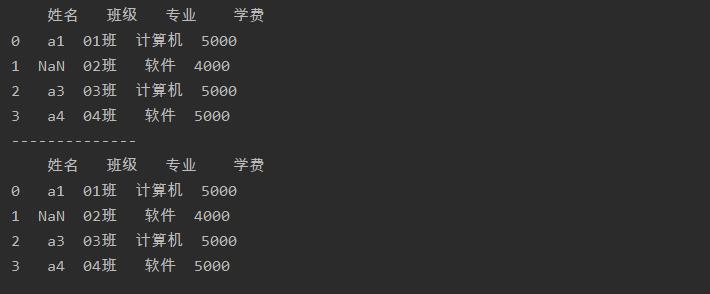
只想删除整行都为缺失值的行,则需要为dropna()函数设置参数how的值为’all’
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a = a.dropna(how='all')
print(a)
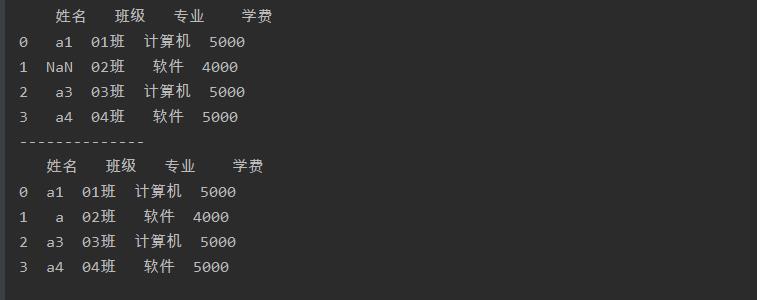
缺失值的填充
fillna()函数可以将数据表中的所有缺失值填充为指定的值
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
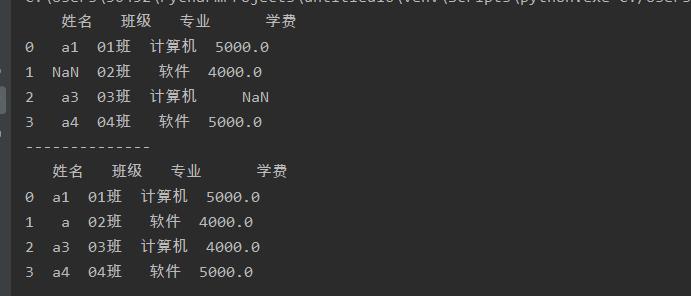
a = a.fillna('a')
print(a)
通过为fillna()函数传入一个字典,为不同列中的缺失值设置不同的填充值
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
a = a.fillna({'姓名':'a','学费':4000})
print(a)
处理重复值
删除重复行
drop_duplicates()函数,无须设置任何参数
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
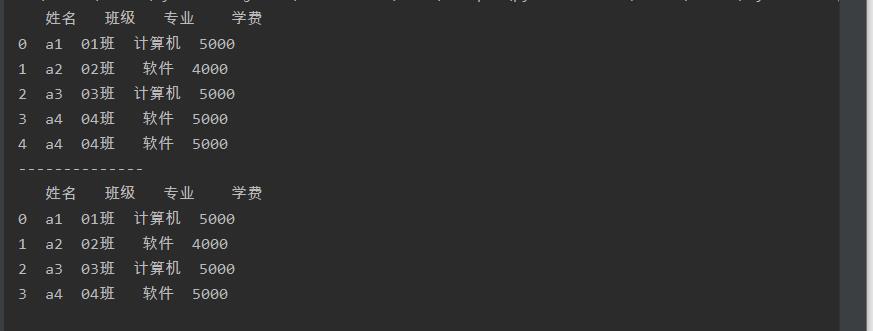
a = a.drop_duplicates()
print(a)
删除某一列中的重复值
drop_duplicates()函数添加参数subset,并设置该参数的值为要处理的列的标签
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
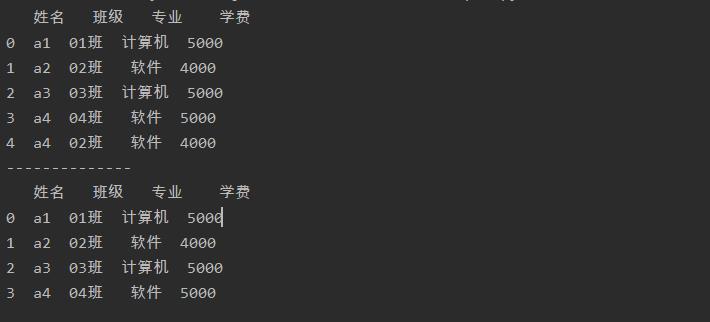
a = a.drop_duplicates(subset='姓名')
print(a)
 keep设置为’first’,表示保留第一个重复值所在的行
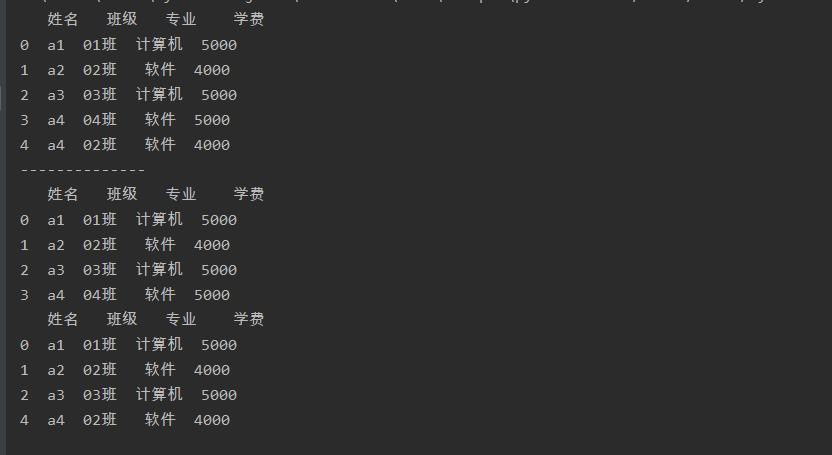
keep设置为’first’,表示保留第一个重复值所在的行
keep设置为’last’ 保留最后一个重复值所在的行
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
b = a.drop_duplicates(subset='姓名',keep='first')
print(b)
c = a.drop_duplicates(subset='姓名',keep='last')
print(c)
keep设置为False,表示把重复值一个不留地全部删除
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
b = a.drop_duplicates(subset='姓名',keep=False)
print(b)

排序数据
sort_values()函数排序数据
参数ascending为True,表示升序排序
参数ascending为False,表示升序排序
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
b = a.sort_values(by='学费',ascending=True)
print(b)
print('--------------')
c = a.sort_values(by='学费',ascending=False)
print(c)
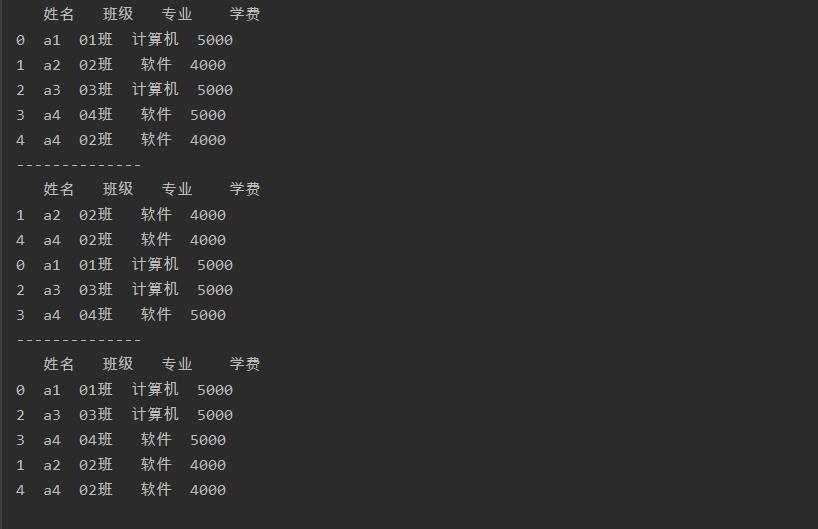
用rank()函数获取数据的排名
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
b = a['学费'].rank(method = 'first',ascending=False)
print(b)
print('--------------')
c = a['学费'].rank(method = 'average',ascending=False)
print(c)
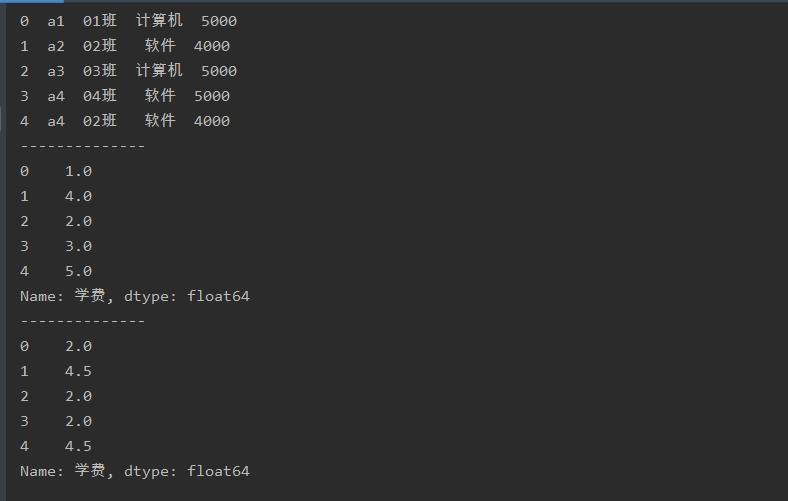
参数method设置为’first’,则表示在数据有重复值时,越先出现的数据排名越靠前
参数method设置为’average’,表示在数据有重复值时,返回重复值的平均排名
筛选数据
import pandas as pd
a = pd.read_excel('test.xlsx',sheet_name=0)
print(a)
print('--------------')
b = a[a['学费'] < 5000]
print(b)
print('--------------')
c = a[(a['学费'] < 5000) & (a['班级'] == '02班')]
print(c)
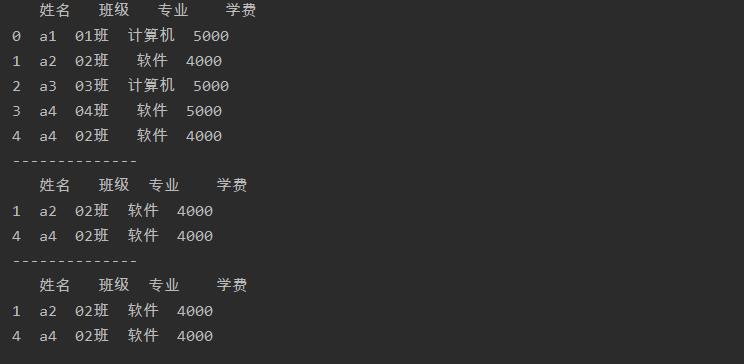
进行多条件筛选,并且这些条件之间是“逻辑与”的关系,可以用“&”符号连接多个筛选条件。
进行多条件筛选,并且这些条件之间是“逻辑或”的关系,可以用“|”符号连接多个筛选条件
注意:每个条件要分别用括号括起来。
以上是关于Python数据分析-pandas-数据处理的主要内容,如果未能解决你的问题,请参考以下文章